 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCattle Trade: A Multi-Agent Benchmark for LLM Bluffing, Bidding, and Bargaining
May 14, 2026We introduce \textsc{Cattle Trade, a multi-agent benchmark for evaluating large language models (LLMs) as agents in strategic reasoning under imperfect information, adversarial interaction, and resource constraints. The benchmark combines auctions, hidden-offer trade challenges (TCs), bargaining, bluffing, opponent modeling, and resource allocation within a single long-horizon game lasting 50--60 turns. Unlike prior agent benchmarks that test these abilities in isolation, \textsc{Cattle Trade} evaluates whether agents integrate them across a competitive, multi-agent economic game with conflicting incentives. The benchmark logs every bid, TC offer, counteroffer, and card selection, enabling behavioural analysis beyond final scores or win rates. We evaluate seven cost-efficient language models and three deterministic code agents across 242 games. Strategic coherence, in particular spending efficiency, resource discipline, and phase-adaptive bidding, is associated with rank more strongly than spending volume or any single subskill. Two heuristic code agents outperform most tested LLMs, and behavioural traces surface recurring LLM failure modes including overbidding, self-bidding, bankrupt TC initiation, and weak opponent-state adaptation. Evaluating agentic competence requires benchmarks that test the joint deployment of multiple capabilities in multi-agent environments with conflicting incentives, uncertainty, and economic dynamics.
Reinforcement Learning for Tool-Calling Agents in Fast Healthcare Interoperability Resources (FHIR)
May 13, 2026Fast Healthcare Interoperability Resources (FHIR) is the dominant standard for interoperable exchange of healthcare data. In FHIR, electronic health records form a directed graph of resources. Answering clinically meaningful questions over FHIR requires agents to perform multi-step reasoning, filtering, and aggregation across multiple resource types. Prior work shows that even tool-augmented LLM agents (retrieval, code execution, multi-turn planning) often select the wrong resources or violate traversal constraints. We study this problem in the context of FHIR-AgentBench, a benchmark for realistic question answering over real-world hospital data, and frame reasoning on FHIR as a sequential decision-making problem over a queryable structured graph. We implement a multi-turn CodeAct agent and post-train it with reinforcement learning using a custom harness and tools. A LLM Judge provides execution-grounded rewards. Compared to prompt-based, closed-model baselines, RL post-training improves performance while enforcing data-integrity constraints. Empirically, our approach improves answer correctness from 50% (o4-mini) to 77% on FHIR-AgentBench using a smaller and cheaper Qwen3-8B model. We present an end-to-end post-training pipeline (environment building, harness construction, model training and custom evaluation) that reliably improves multi-turn reasoning over structured clinical graphs.
Coconut Palm Tree Counting on Drone Images with Deep Object Detection and Synthetic Training Data
Dec 16, 2024



Drones have revolutionized various domains, including agriculture. Recent advances in deep learning have propelled among other things object detection in computer vision. This study utilized YOLO, a real-time object detector, to identify and count coconut palm trees in Ghanaian farm drone footage. The farm presented has lost track of its trees due to different planting phases. While manual counting would be very tedious and error-prone, accurately determining the number of trees is crucial for efficient planning and management of agricultural processes, especially for optimizing yields and predicting production. We assessed YOLO for palm detection within a semi-automated framework, evaluated accuracy augmentations, and pondered its potential for farmers. Data was captured in September 2022 via drones. To optimize YOLO with scarce data, synthetic images were created for model training and validation. The YOLOv7 model, pretrained on the COCO dataset (excluding coconut palms), was adapted using tailored data. Trees from footage were repositioned on synthetic images, with testing on distinct authentic images. In our experiments, we adjusted hyperparameters, improving YOLO's mean average precision (mAP). We also tested various altitudes to determine the best drone height. From an initial mAP@.5 of $0.65$, we achieved 0.88, highlighting the value of synthetic images in agricultural scenarios.
Efficient Quantum One-Class Support Vector Machines for Anomaly Detection Using Randomized Measurements and Variable Subsampling
Jul 30, 2024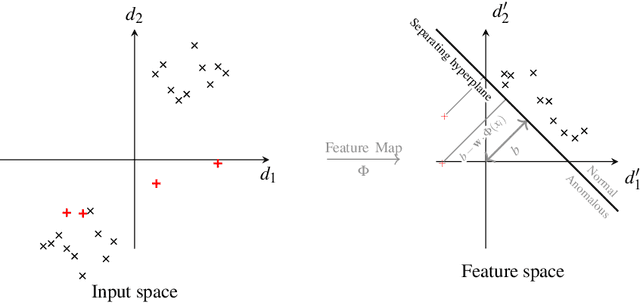
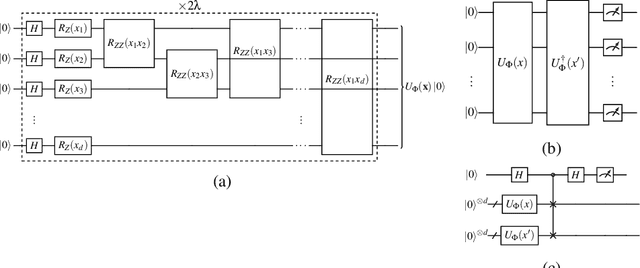
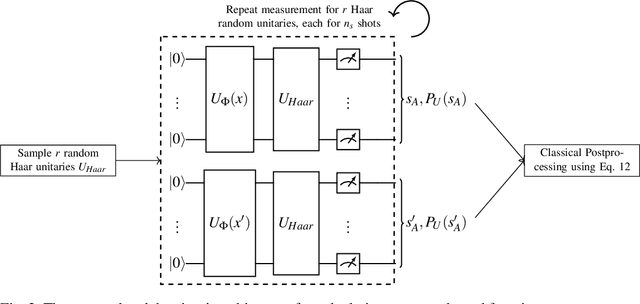
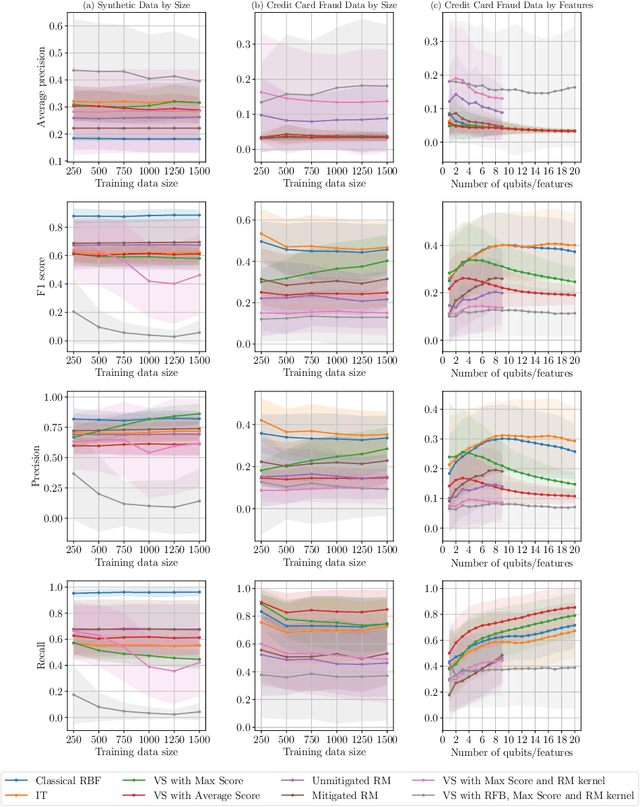
Quantum one-class support vector machines leverage the advantage of quantum kernel methods for semi-supervised anomaly detection. However, their quadratic time complexity with respect to data size poses challenges when dealing with large datasets. In recent work, quantum randomized measurements kernels and variable subsampling were proposed, as two independent methods to address this problem. The former achieves higher average precision, but suffers from variance, while the latter achieves linear complexity to data size and has lower variance. The current work focuses instead on combining these two methods, along with rotated feature bagging, to achieve linear time complexity both to data size and to number of features. Despite their instability, the resulting models exhibit considerably higher performance and faster training and testing times.
ClusterComm: Discrete Communication in Decentralized MARL using Internal Representation Clustering
Jan 07, 2024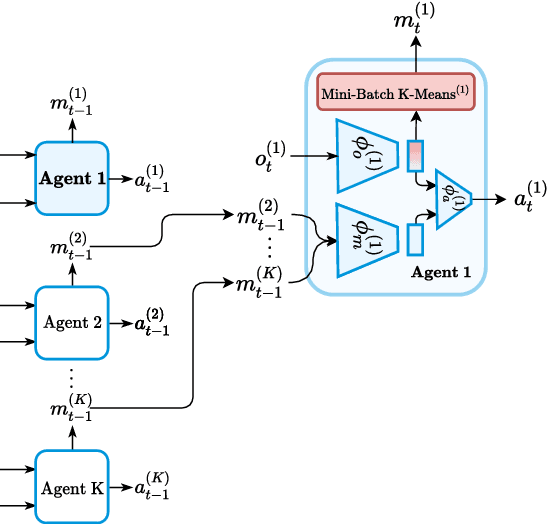
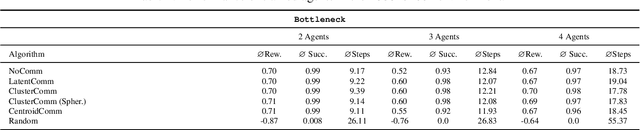

In the realm of Multi-Agent Reinforcement Learning (MARL), prevailing approaches exhibit shortcomings in aligning with human learning, robustness, and scalability. Addressing this, we introduce ClusterComm, a fully decentralized MARL framework where agents communicate discretely without a central control unit. ClusterComm utilizes Mini-Batch-K-Means clustering on the last hidden layer's activations of an agent's policy network, translating them into discrete messages. This approach outperforms no communication and competes favorably with unbounded, continuous communication and hence poses a simple yet effective strategy for enhancing collaborative task-solving in MARL.
Towards Efficient Quantum Anomaly Detection: One-Class SVMs using Variable Subsampling and Randomized Measurements
Dec 14, 2023



Quantum computing, with its potential to enhance various machine learning tasks, allows significant advancements in kernel calculation and model precision. Utilizing the one-class Support Vector Machine alongside a quantum kernel, known for its classically challenging representational capacity, notable improvements in average precision compared to classical counterparts were observed in previous studies. Conventional calculations of these kernels, however, present a quadratic time complexity concerning data size, posing challenges in practical applications. To mitigate this, we explore two distinct approaches: utilizing randomized measurements to evaluate the quantum kernel and implementing the variable subsampling ensemble method, both targeting linear time complexity. Experimental results demonstrate a substantial reduction in training and inference times by up to 95\% and 25\% respectively, employing these methods. Although unstable, the average precision of randomized measurements discernibly surpasses that of the classical Radial Basis Function kernel, suggesting a promising direction for further research in scalable, efficient quantum computing applications in machine learning.
Applying QNLP to sentiment analysis in finance
Jul 31, 2023As an application domain where the slightest qualitative improvements can yield immense value, finance is a promising candidate for early quantum advantage. Focusing on the rapidly advancing field of Quantum Natural Language Processing (QNLP), we explore the practical applicability of the two central approaches DisCoCat and Quantum-Enhanced Long Short-Term Memory (QLSTM) to the problem of sentiment analysis in finance. Utilizing a novel ChatGPT-based data generation approach, we conduct a case study with more than 1000 realistic sentences and find that QLSTMs can be trained substantially faster than DisCoCat while also achieving close to classical results for their available software implementations.
Weight Re-Mapping for Variational Quantum Algorithms
Jun 09, 2023Inspired by the remarkable success of artificial neural networks across a broad spectrum of AI tasks, variational quantum circuits (VQCs) have recently seen an upsurge in quantum machine learning applications. The promising outcomes shown by VQCs, such as improved generalization and reduced parameter training requirements, are attributed to the robust algorithmic capabilities of quantum computing. However, the current gradient-based training approaches for VQCs do not adequately accommodate the fact that trainable parameters (or weights) are typically used as angles in rotational gates. To address this, we extend the concept of weight re-mapping for VQCs, as introduced by K\"olle et al. (2023). This approach unambiguously maps the weights to an interval of length $2\pi$, mirroring data rescaling techniques in conventional machine learning that have proven to be highly beneficial in numerous scenarios. In our study, we employ seven distinct weight re-mapping functions to assess their impact on eight classification datasets, using variational classifiers as a representative example. Our results indicate that weight re-mapping can enhance the convergence speed of the VQC. We assess the efficacy of various re-mapping functions across all datasets and measure their influence on the VQC's average performance. Our findings indicate that weight re-mapping not only consistently accelerates the convergence of VQCs, regardless of the specific re-mapping function employed, but also significantly increases accuracy in certain cases.
Visual Transformers for Primates Classification and Covid Detection
Dec 20, 2022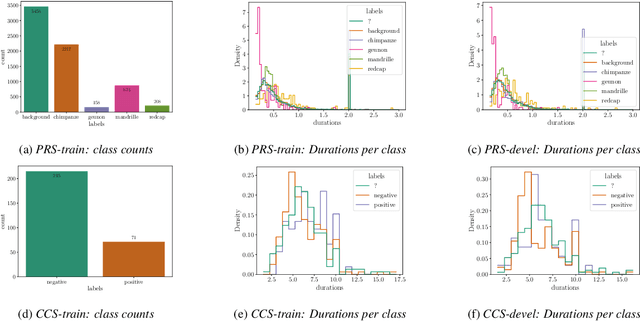
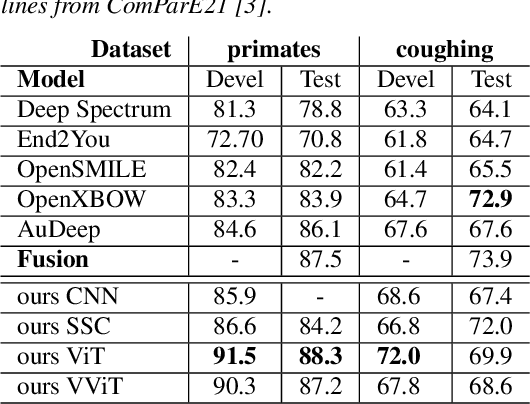
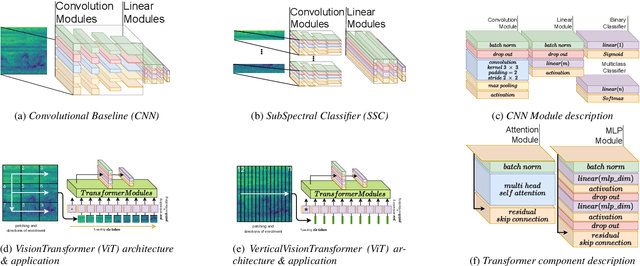
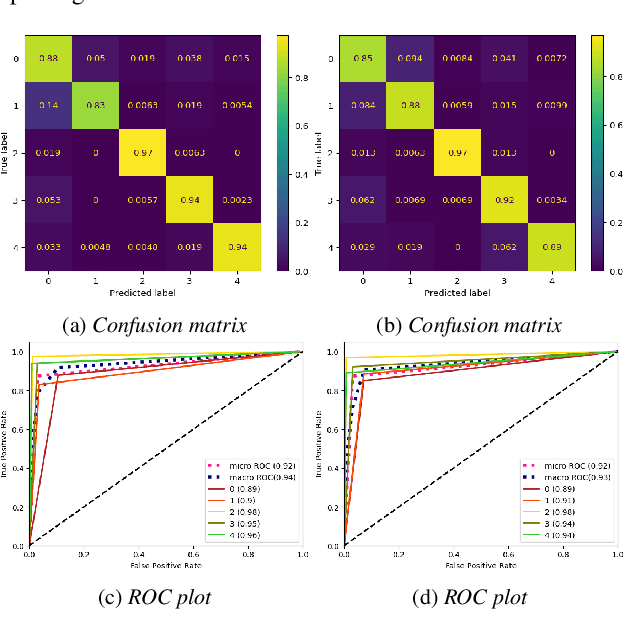
We apply the vision transformer, a deep machine learning model build around the attention mechanism, on mel-spectrogram representations of raw audio recordings. When adding mel-based data augmentation techniques and sample-weighting, we achieve comparable performance on both (PRS and CCS challenge) tasks of ComParE21, outperforming most single model baselines. We further introduce overlapping vertical patching and evaluate the influence of parameter configurations. Index Terms: audio classification, attention, mel-spectrogram, unbalanced data-sets, computational paralinguistics
Empirical Analysis of Limits for Memory Distance in Recurrent Neural Networks
Dec 20, 2022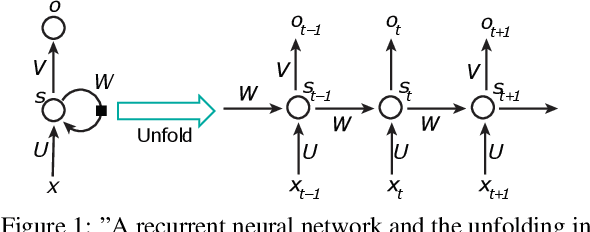
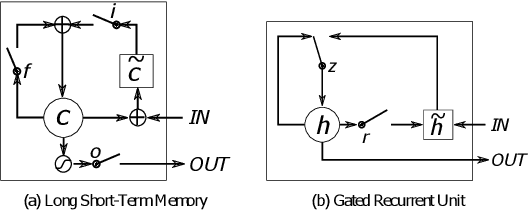
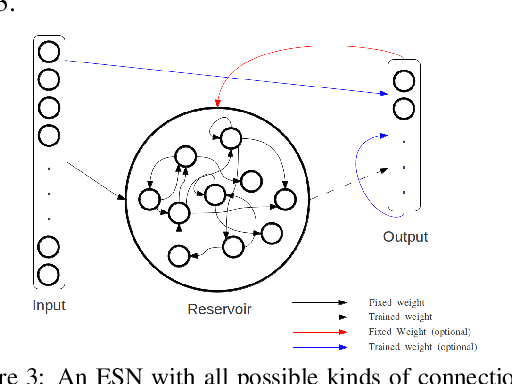
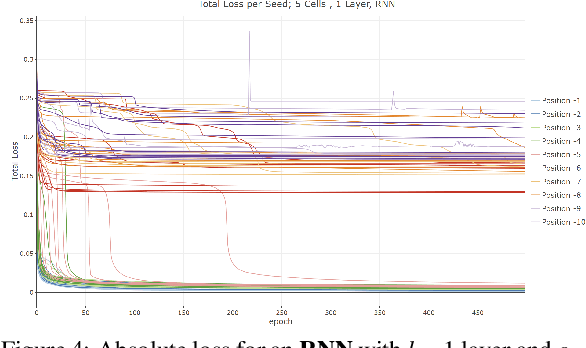
Common to all different kinds of recurrent neural networks (RNNs) is the intention to model relations between data points through time. When there is no immediate relationship between subsequent data points (like when the data points are generated at random, e.g.), we show that RNNs are still able to remember a few data points back into the sequence by memorizing them by heart using standard backpropagation. However, we also show that for classical RNNs, LSTM and GRU networks the distance of data points between recurrent calls that can be reproduced this way is highly limited (compared to even a loose connection between data points) and subject to various constraints imposed by the type and size of the RNN in question. This implies the existence of a hard limit (way below the information-theoretic one) for the distance between related data points within which RNNs are still able to recognize said relation.