 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Participate through Trading of Reward Shares
Jan 18, 2023Enabling autonomous agents to act cooperatively is an important step to integrate artificial intelligence in our daily lives. While some methods seek to stimulate cooperation by letting agents give rewards to others, in this paper we propose a method inspired by the stock market, where agents have the opportunity to participate in other agents' returns by acquiring reward shares. Intuitively, an agent may learn to act according to the common interest when being directly affected by the other agents' rewards. The empirical results of the tested general-sum Markov games show that this mechanism promotes cooperative policies among independently trained agents in social dilemma situations. Moreover, as demonstrated in a temporally and spatially extended domain, participation can lead to the development of roles and the division of subtasks between the agents.
Stochastic Market Games
Jul 19, 2022



Some of the most relevant future applications of multi-agent systems like autonomous driving or factories as a service display mixed-motive scenarios, where agents might have conflicting goals. In these settings agents are likely to learn undesirable outcomes in terms of cooperation under independent learning, such as overly greedy behavior. Motivated from real world societies, in this work we propose to utilize market forces to provide incentives for agents to become cooperative. As demonstrated in an iterated version of the Prisoner's Dilemma, the proposed market formulation can change the dynamics of the game to consistently learn cooperative policies. Further we evaluate our approach in spatially and temporally extended settings for varying numbers of agents. We empirically find that the presence of markets can improve both the overall result and agent individual returns via their trading activities.
Towards Multi-Agent Reinforcement Learning using Quantum Boltzmann Machines
Sep 22, 2021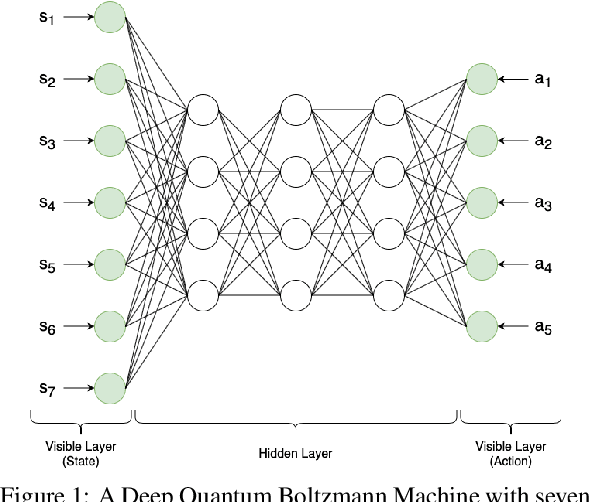
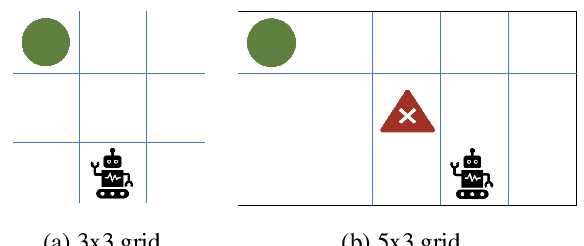
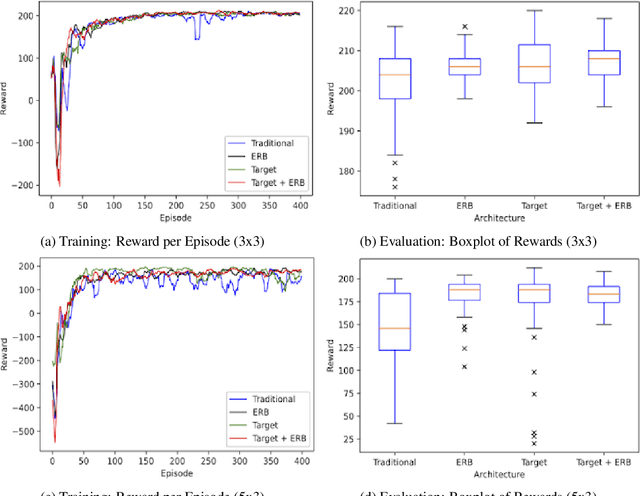
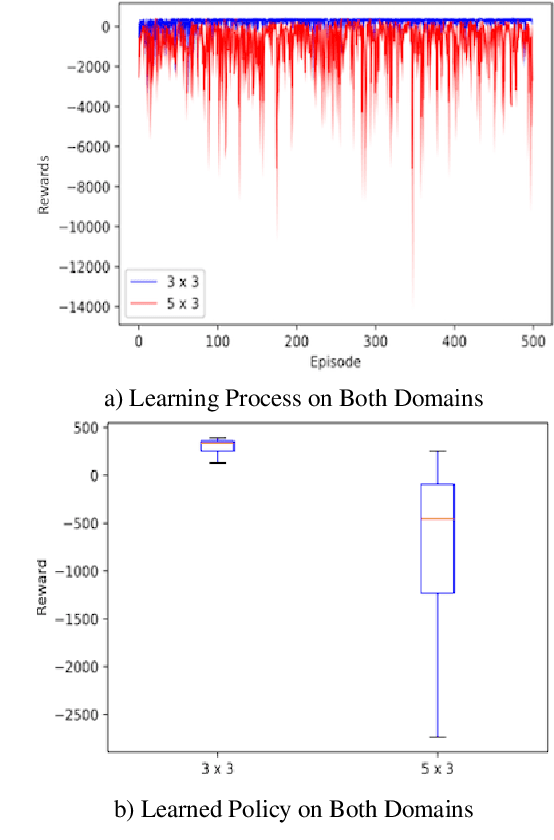
Reinforcement learning has driven impressive advances in machine learning. Simultaneously, quantum-enhanced machine learning algorithms using quantum annealing underlie heavy developments. Recently, a multi-agent reinforcement learning (MARL) architecture combining both paradigms has been proposed. This novel algorithm, which utilizes Quantum Boltzmann Machines (QBMs) for Q-value approximation has outperformed regular deep reinforcement learning in terms of time-steps needed to converge. However, this algorithm was restricted to single-agent and small 2x2 multi-agent grid domains. In this work, we propose an extension to the original concept in order to solve more challenging problems. Similar to classic DQNs, we add an experience replay buffer and use different networks for approximating the target and policy values. The experimental results show that learning becomes more stable and enables agents to find optimal policies in grid-domains with higher complexity. Additionally, we assess how parameter sharing influences the agents behavior in multi-agent domains. Quantum sampling proves to be a promising method for reinforcement learning tasks, but is currently limited by the QPU size and therefore by the size of the input and Boltzmann machine.
Solving Large Steiner Tree Problems in Graphs for Cost-Efficient Fiber-To-The-Home Network Expansion
Sep 22, 2021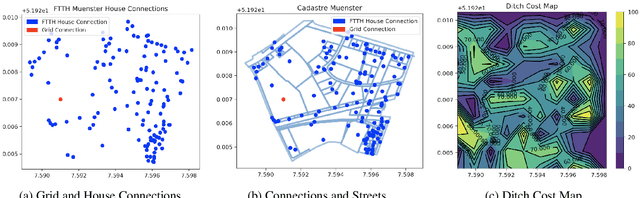
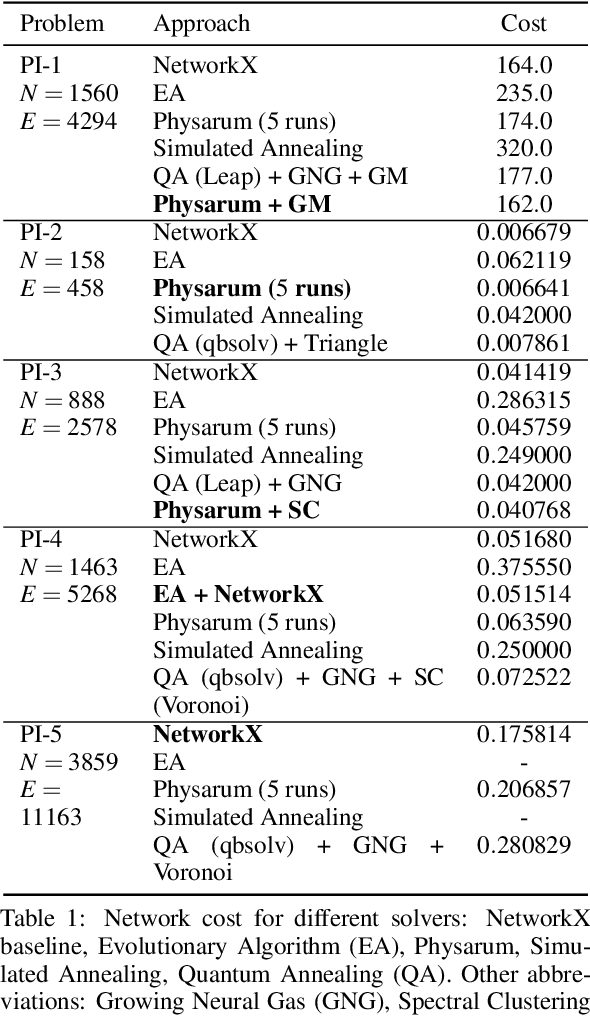
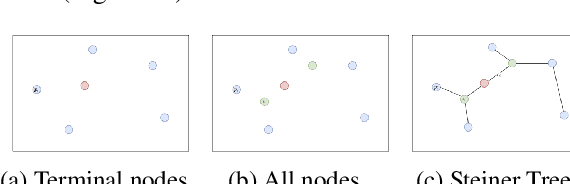
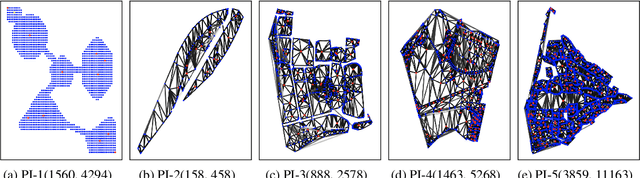
The expansion of Fiber-To-The-Home (FTTH) networks creates high costs due to expensive excavation procedures. Optimizing the planning process and minimizing the cost of the earth excavation work therefore lead to large savings. Mathematically, the FTTH network problem can be described as a minimum Steiner Tree problem. Even though the Steiner Tree problem has already been investigated intensively in the last decades, it might be further optimized with the help of new computing paradigms and emerging approaches. This work studies upcoming technologies, such as Quantum Annealing, Simulated Annealing and nature-inspired methods like Evolutionary Algorithms or slime-mold-based optimization. Additionally, we investigate partitioning and simplifying methods. Evaluated on several real-life problem instances, we could outperform a traditional, widely-used baseline (NetworkX Approximate Solver) on most of the domains. Prior partitioning of the initial graph and the presented slime-mold-based approach were especially valuable for a cost-efficient approximation. Quantum Annealing seems promising, but was limited by the number of available qubits.
Analysis of Feature Representations for Anomalous Sound Detection
Dec 11, 2020
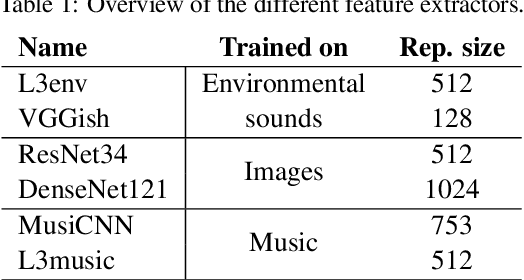
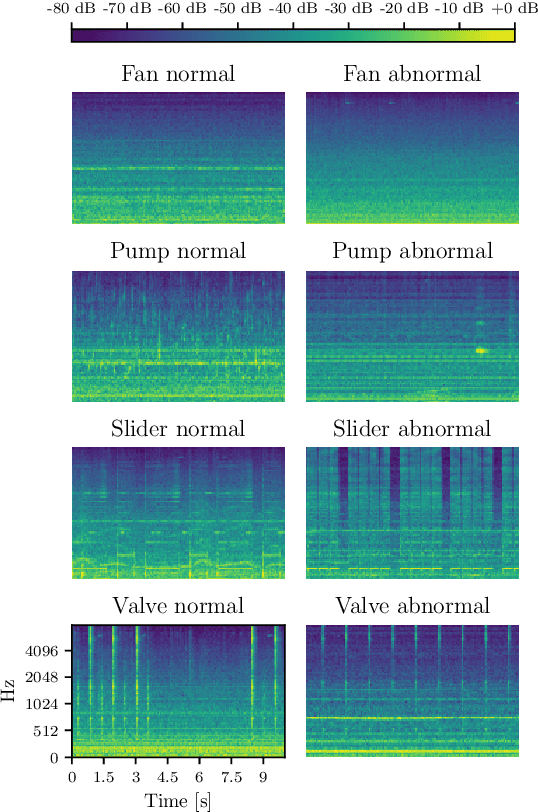
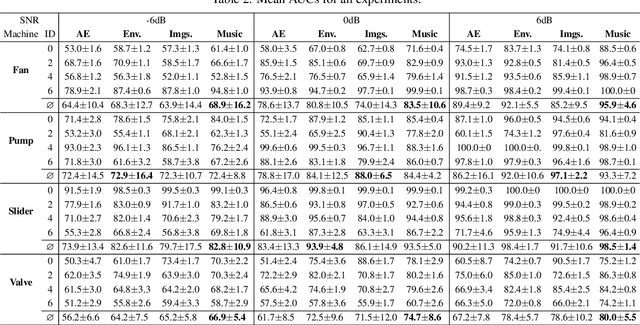
In this work, we thoroughly evaluate the efficacy of pretrained neural networks as feature extractors for anomalous sound detection. In doing so, we leverage the knowledge that is contained in these neural networks to extract semantically rich features (representations) that serve as input to a Gaussian Mixture Model which is used as a density estimator to model normality. We compare feature extractors that were trained on data from various domains, namely: images, environmental sounds and music. Our approach is evaluated on recordings from factory machinery such as valves, pumps, sliders and fans. All of the evaluated representations outperform the autoencoder baseline with music based representations yielding the best performance in most cases. These results challenge the common assumption that closely matching the domain of the feature extractor and the downstream task results in better downstream task performance.
Difficulty Classification of Mountainbike Downhill Trails utilizing Deep Neural Networks
Aug 05, 2019


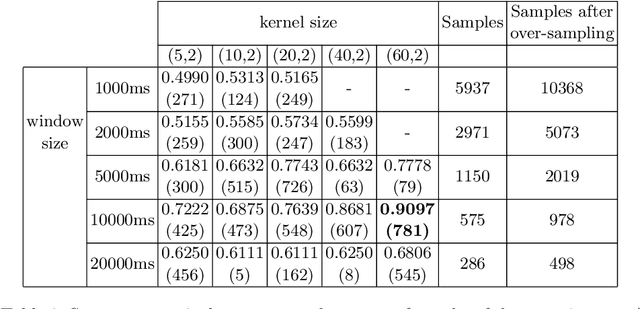
The difficulty of mountainbike downhill trails is a subjective perception. However, sports-associations and mountainbike park operators attempt to group trails into different levels of difficulty with scales like the Singletrail-Skala (S0-S5) or colored scales (blue, red, black, ...) as proposed by The International Mountain Bicycling Association. Inconsistencies in difficulty grading occur due to the various scales, different people grading the trails, differences in topography, and more. We propose an end-to-end deep learning approach to classify trails into three difficulties easy, medium, and hard by using sensor data. With mbientlab Meta Motion r0.2 sensor units, we record accelerometer- and gyroscope data of one rider on multiple trail segments. A 2D convolutional neural network is trained with a stacked and concatenated representation of the aforementioned data as its input. We run experiments with five different sample- and five different kernel sizes and achieve a maximum Sparse Categorical Accuracy of 0.9097. To the best of our knowledge, this is the first work targeting computational difficulty classification of mountainbike downhill trails.
Memory Bounded Open-Loop Planning in Large POMDPs using Thompson Sampling
May 10, 2019

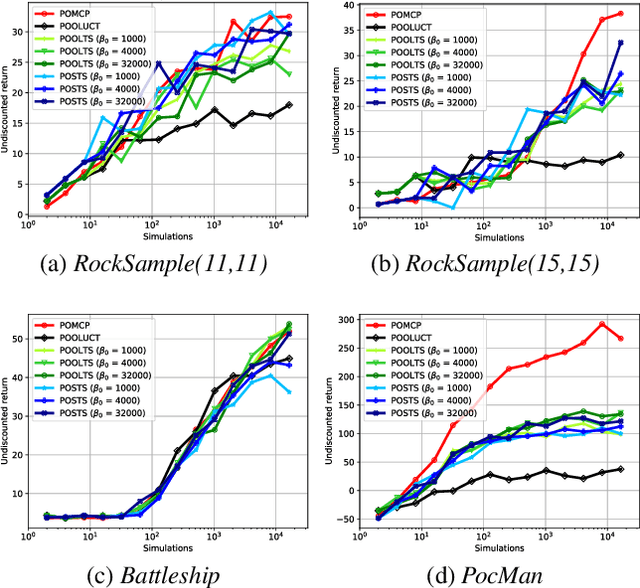
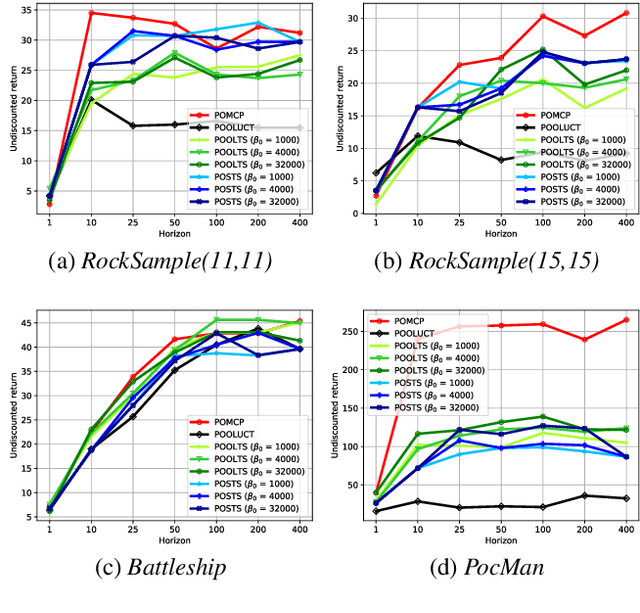
State-of-the-art approaches to partially observable planning like POMCP are based on stochastic tree search. While these approaches are computationally efficient, they may still construct search trees of considerable size, which could limit the performance due to restricted memory resources. In this paper, we propose Partially Observable Stacked Thompson Sampling (POSTS), a memory bounded approach to open-loop planning in large POMDPs, which optimizes a fixed size stack of Thompson Sampling bandits. We empirically evaluate POSTS in four large benchmark problems and compare its performance with different tree-based approaches. We show that POSTS achieves competitive performance compared to tree-based open-loop planning and offers a performance-memory tradeoff, making it suitable for partially observable planning with highly restricted computational and memory resources.
Distributed Policy Iteration for Scalable Approximation of Cooperative Multi-Agent Policies
Jan 25, 2019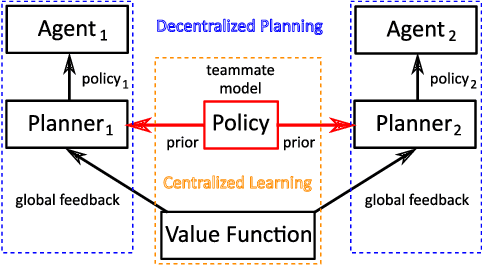
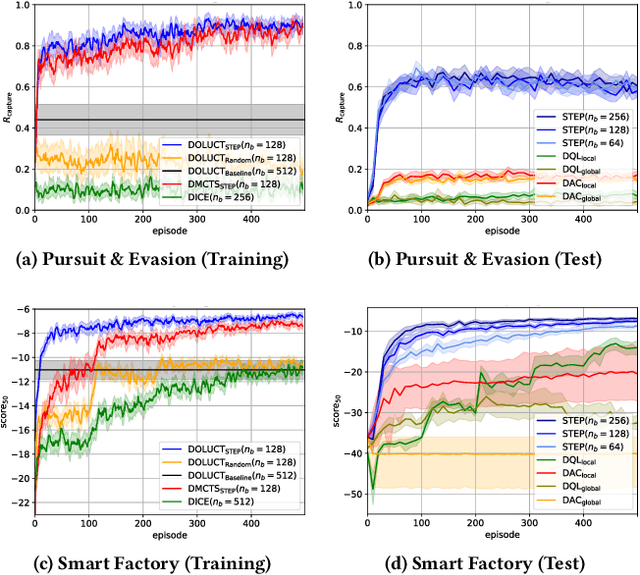
Decision making in multi-agent systems (MAS) is a great challenge due to enormous state and joint action spaces as well as uncertainty, making centralized control generally infeasible. Decentralized control offers better scalability and robustness but requires mechanisms to coordinate on joint tasks and to avoid conflicts. Common approaches to learn decentralized policies for cooperative MAS suffer from non-stationarity and lacking credit assignment, which can lead to unstable and uncoordinated behavior in complex environments. In this paper, we propose Strong Emergent Policy approximation (STEP), a scalable approach to learn strong decentralized policies for cooperative MAS with a distributed variant of policy iteration. For that, we use function approximation to learn from action recommendations of a decentralized multi-agent planning algorithm. STEP combines decentralized multi-agent planning with centralized learning, only requiring a generative model for distributed black box optimization. We experimentally evaluate STEP in two challenging and stochastic domains with large state and joint action spaces and show that STEP is able to learn stronger policies than standard multi-agent reinforcement learning algorithms, when combining multi-agent open-loop planning with centralized function approximation. The learned policies can be reintegrated into the multi-agent planning process to further improve performance.
Preparing for the Unexpected: Diversity Improves Planning Resilience in Evolutionary Algorithms
Oct 30, 2018
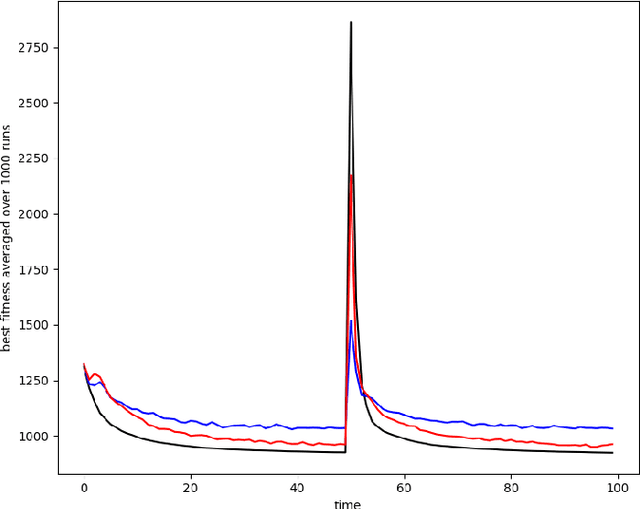

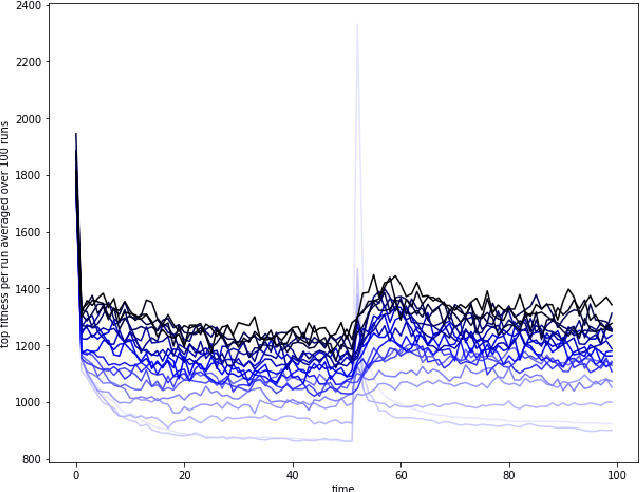
As automatic optimization techniques find their way into industrial applications, the behavior of many complex systems is determined by some form of planner picking the right actions to optimize a given objective function. In many cases, the mapping of plans to objective reward may change due to unforeseen events or circumstances in the real world. In those cases, the planner usually needs some additional effort to adjust to the changed situation and reach its previous level of performance. Whenever we still need to continue polling the planner even during re-planning, it oftentimes exhibits severely lacking performance. In order to improve the planner's resilience to unforeseen change, we argue that maintaining a certain level of diversity amongst the considered plans at all times should be added to the planner's objective. Effectively, we encourage the planner to keep alternative plans to its currently best solution. As an example case, we implement a diversity-aware genetic algorithm using two different metrics for diversity (differing in their generality) and show that the blow in performance due to unexpected change can be severely lessened in the average case. We also analyze the parameter settings necessary for these techniques in order to gain an intuition how they can be incorporated into larger frameworks or process models for software and systems engineering.