 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQoS based resource management for concurrent operation using MCTS
Feb 17, 2025



Modern AESA technology enables RF systems to not only perform various radar, communication and electronic warfare tasks on a single aperture, but even to execute multiple tasks concurrently. These capabilities increase system complexity and require intelligent or cognitive resource management. This paper introduces such a resource management framework based on quality of service based resource allocation and Monte Carlo tree search allowing for optimal system usage and profound decision-making. Furthermore, we present experimental verification in a complex application scenario.
A resource management approach for concurrent operation of RF functionalities
Jan 14, 2025



Future multifunction RF systems will be able to not only perform various different radar, communication and electronic warfare functionalities but also to perform them simultaneously on the same aperture. This ability of concurrent operations requires new, cognitive approaches of resource management compared to classical methods. This paper presents such a new approach using a combination of quality of service based resource management and Monte Carlo tree search.
Measurement Uncertainty: Relating the uncertainties of physical and virtual measurements
Feb 21, 2024

In the context of industrially mass-manufactured products, quality management is based on physically inspecting a small sample from a large batch and reasoning about the batch's quality conformance. When complementing physical inspections with predictions from machine learning models, it is crucial that the uncertainty of the prediction is known. Otherwise, the application of established quality management concepts is not legitimate. Deterministic (machine learning) models lack quantification of their predictive uncertainty and are therefore unsuitable. Probabilistic (machine learning) models provide a predictive uncertainty along with the prediction. However, a concise relationship is missing between the measurement uncertainty of physical inspections and the predictive uncertainty of probabilistic models in their application in quality management. Here, we show how the predictive uncertainty of probabilistic (machine learning) models is related to the measurement uncertainty of physical inspections. This enables the use of probabilistic models for virtual inspections and integrates them into existing quality management concepts. Thus, we can provide a virtual measurement for any quality characteristic based on the process data and achieve a 100 percent inspection rate. In the field of Predictive Quality, the virtual measurement is of great interest. Based on our results, physical inspections with a low sampling rate can be accompanied by virtual measurements that allow an inspection rate of 100 percent. We add substantial value, especially to complex process chains, as faulty products/parts are identified promptly and upcoming process steps can be aborted.
SoK: Assessing the State of Applied Federated Machine Learning
Aug 03, 2023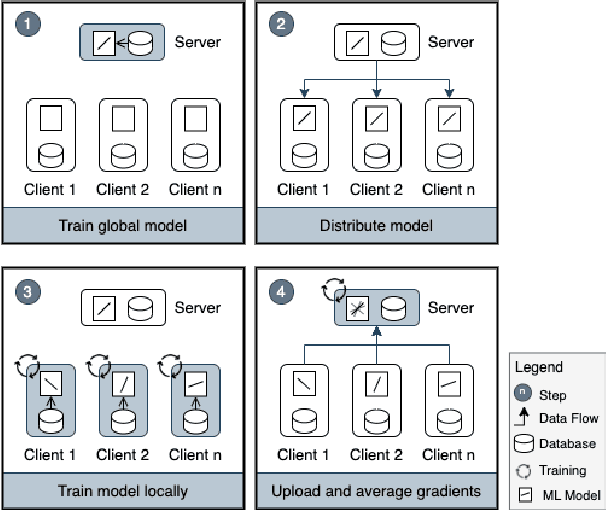
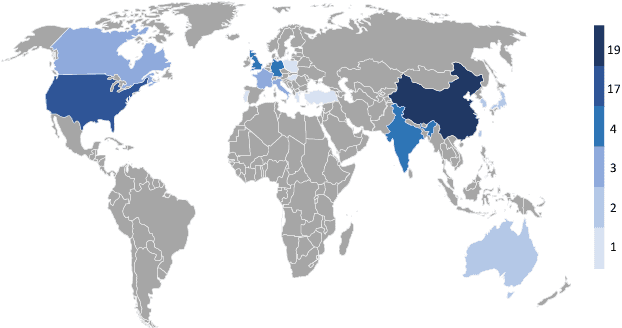
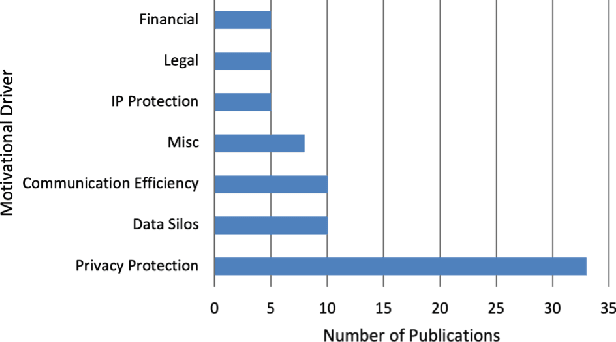
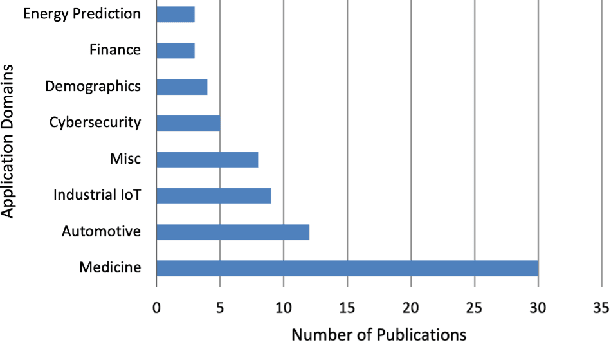
Machine Learning (ML) has shown significant potential in various applications; however, its adoption in privacy-critical domains has been limited due to concerns about data privacy. A promising solution to this issue is Federated Machine Learning (FedML), a model-to-data approach that prioritizes data privacy. By enabling ML algorithms to be applied directly to distributed data sources without sharing raw data, FedML offers enhanced privacy protections, making it suitable for privacy-critical environments. Despite its theoretical benefits, FedML has not seen widespread practical implementation. This study aims to explore the current state of applied FedML and identify the challenges hindering its practical adoption. Through a comprehensive systematic literature review, we assess 74 relevant papers to analyze the real-world applicability of FedML. Our analysis focuses on the characteristics and emerging trends of FedML implementations, as well as the motivational drivers and application domains. We also discuss the encountered challenges in integrating FedML into real-life settings. By shedding light on the existing landscape and potential obstacles, this research contributes to the further development and implementation of FedML in privacy-critical scenarios.
Quality of Service Based Radar Resource Management for Navigation and Positioning
Jun 12, 2023



In hostile environments, GNSS is a potentially unreliable solution for self-localization and navigation. Many systems only use an IMU as a backup system, resulting in integration errors which can dramatically increase during mission execution. We suggest using a fighter radar to illuminate satellites with known trajectories to enhance the self-localization information. This technique is time-consuming and resource-demanding but necessary as other tasks depend on the self-localization accuracy. Therefore an adaption of classical resource management frameworks is required. We propose a quality of service based resource manager with capabilities to account for inter-task dependencies to optimize the self-localization update strategy. Our results show that this leads to adaptive navigation update strategies, mastering the trade-off between self-localization and the requirements of other tasks.
* 8 pages, 9 figures
Unlocking the Potential of Collaborative AI -- On the Socio-technical Challenges of Federated Machine Learning
Apr 29, 2023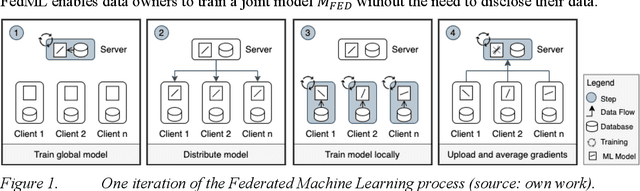

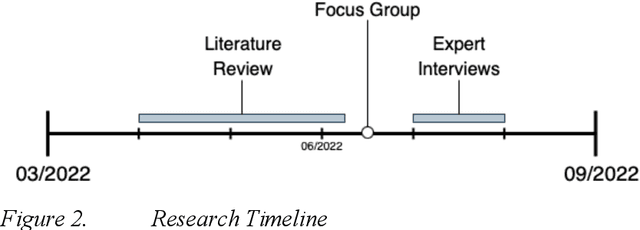
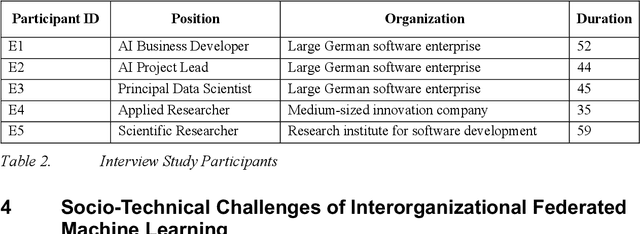
The disruptive potential of AI systems roots in the emergence of big data. Yet, a significant portion is scattered and locked in data silos, leaving its potential untapped. Federated Machine Learning is a novel AI paradigm enabling the creation of AI models from decentralized, potentially siloed data. Hence, Federated Machine Learning could technically open data silos and therefore unlock economic potential. However, this requires collaboration between multiple parties owning data silos. Setting up collaborative business models is complex and often a reason for failure. Current literature lacks guidelines on which aspects must be considered to successfully realize collaborative AI projects. This research investigates the challenges of prevailing collaborative business models and distinct aspects of Federated Machine Learning. Through a systematic literature review, focus group, and expert interviews, we provide a systemized collection of socio-technical challenges and an extended Business Model Canvas for the initial viability assessment of collaborative AI projects.
Quality of service based radar resource management for synchronisation problems
Mar 03, 2023



An intelligent radar resource management is an essential building block of any modern radar system. The quality of service based resource allocation model (Q-RAM) provides a framework for profound and quantifiable decision-making but lacks a representation of inter-task dependencies that can e.g. arise for tracking and synchronisation tasks. As a consequence, synchronisation is usually performed in fixed non-optimal patterns. We present an extension of Q-RAM which enables the resource allocation to consider complex inter-task dependencies and can produce adaptive and intelligent synchronisation schemes. The provided experimental results demonstrate a significant improvement over traditional strategies.
* 4 pages, 6 figures
Training one model to detect heart and lung sound events from single point auscultations
Jan 15, 2023



Objective: This work proposes a semi-supervised training approach for detecting lung and heart sounds simultaneously with only one trained model and in invariance to the auscultation point. Methods: We use open-access data from the 2016 Physionet/CinC Challenge, the 2022 George Moody Challenge, and from the lung sound database HF_V1. We first train specialist single-task models using foreground ground truth (GT) labels from different auscultation databases to identify background sound events in the respective lung and heart auscultation databases. The pseudo-labels generated in this way were combined with the ground truth labels in a new training iteration, such that a new model was subsequently trained to detect foreground and background signals. Benchmark tests ensured that the newly trained model could detect both, lung, and heart sound events in different auscultation sites without regressing on the original task. We also established hand-validated labels for the respective background signal in heart and lung sound auscultations to evaluate the models. Results: In this work, we report for the first time results for i) a multi-class prediction for lung sound events and ii) for simultaneous detection of heart and lung sound events and achieve competitive results using only one model. The combined multi-task model regressed slightly in heart sound detection and gained significantly in lung sound detection accuracy with an overall macro F1 score of 39.2% over six classes, representing a 6.7% improvement over the single-task baseline models. Conclusion/Significance: To the best of our knowledge, this is the first approach developed to date for measuring heart and lung sound events invariant to both, the auscultation site and capturing device. Hence, our model is capable of performing lung and heart sound detection from any auscultation location.
SEQUENT: Towards Traceable Quantum Machine Learning using Sequential Quantum Enhanced Training
Jan 06, 2023



Applying new computing paradigms like quantum computing to the field of machine learning has recently gained attention. However, as high-dimensional real-world applications are not yet feasible to be solved using purely quantum hardware, hybrid methods using both classical and quantum machine learning paradigms have been proposed. For instance, transfer learning methods have been shown to be successfully applicable to hybrid image classification tasks. Nevertheless, beneficial circuit architectures still need to be explored. Therefore, tracing the impact of the chosen circuit architecture and parameterization is crucial for the development of beneficially applicable hybrid methods. However, current methods include processes where both parts are trained concurrently, therefore not allowing for a strict separability of classical and quantum impact. Thus, those architectures might produce models that yield a superior prediction accuracy whilst employing the least possible quantum impact. To tackle this issue, we propose Sequential Quantum Enhanced Training (SEQUENT) an improved architecture and training process for the traceable application of quantum computing methods to hybrid machine learning. Furthermore, we provide formal evidence for the disadvantage of current methods and preliminary experimental results as a proof-of-concept for the applicability of SEQUENT.
Towards Multi-Agent Reinforcement Learning using Quantum Boltzmann Machines
Sep 22, 2021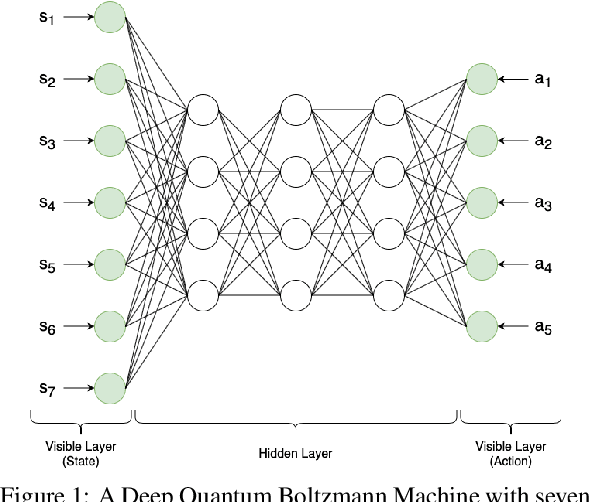
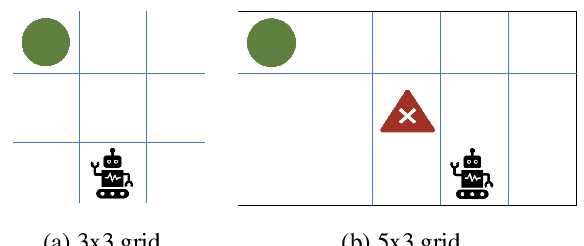
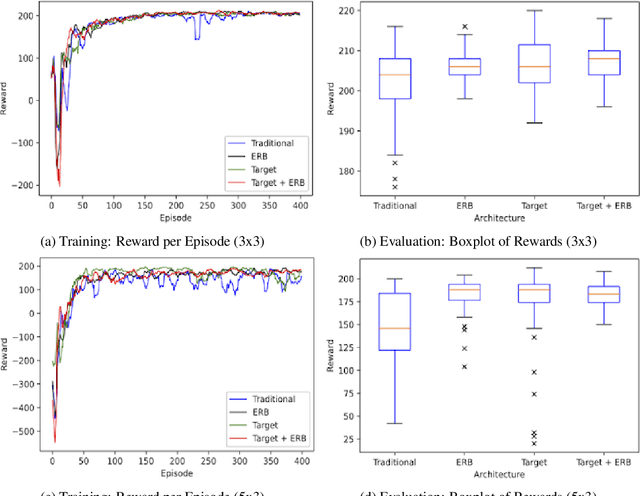
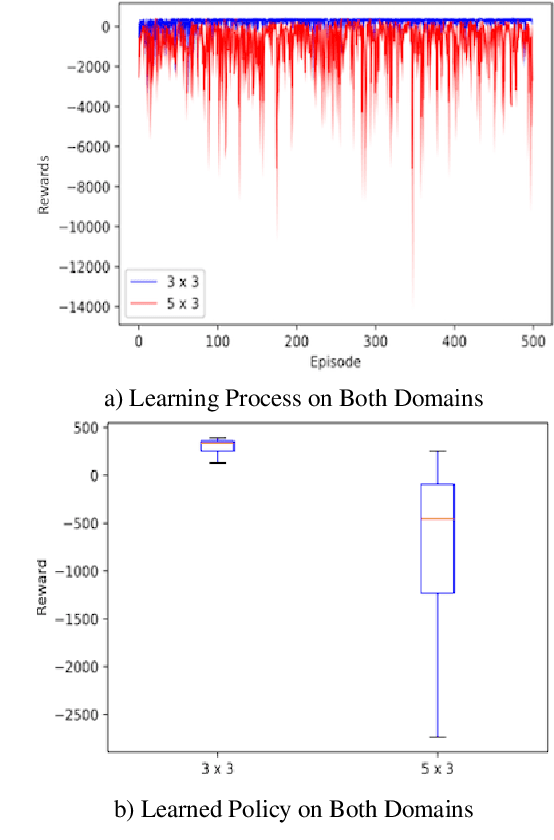
Reinforcement learning has driven impressive advances in machine learning. Simultaneously, quantum-enhanced machine learning algorithms using quantum annealing underlie heavy developments. Recently, a multi-agent reinforcement learning (MARL) architecture combining both paradigms has been proposed. This novel algorithm, which utilizes Quantum Boltzmann Machines (QBMs) for Q-value approximation has outperformed regular deep reinforcement learning in terms of time-steps needed to converge. However, this algorithm was restricted to single-agent and small 2x2 multi-agent grid domains. In this work, we propose an extension to the original concept in order to solve more challenging problems. Similar to classic DQNs, we add an experience replay buffer and use different networks for approximating the target and policy values. The experimental results show that learning becomes more stable and enables agents to find optimal policies in grid-domains with higher complexity. Additionally, we assess how parameter sharing influences the agents behavior in multi-agent domains. Quantum sampling proves to be a promising method for reinforcement learning tasks, but is currently limited by the QPU size and therefore by the size of the input and Boltzmann machine.