 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesebis at ArchEHR-QA 2026: How Much Can You Do Locally? Evaluating Grounded EHR QA on a Single Notebook
Mar 14, 2026Clinical question answering over electronic health records (EHRs) can help clinicians and patients access relevant medical information more efficiently. However, many recent approaches rely on large cloud-based models, which are difficult to deploy in clinical environments due to privacy constraints and computational requirements. In this work, we investigate how far grounded EHR question answering can be pushed when restricted to a single notebook. We participate in all four subtasks of the ArchEHR-QA 2026 shared task and evaluate several approaches designed to run on commodity hardware. All experiments are conducted locally without external APIs or cloud infrastructure. Our results show that such systems can achieve competitive performance on the shared task leaderboards. In particular, our submissions perform above average in two subtasks, and we observe that smaller models can approach the performance of much larger systems when properly configured. These findings suggest that privacy-preserving EHR QA systems running fully locally are feasible with current models and commodity hardware. The source code is available at https://github.com/ibrahimey/ArchEHR-QA-2026.
Real-Time Generation of Game Video Commentary with Multimodal LLMs: Pause-Aware Decoding Approaches
Mar 03, 2026Real-time video commentary generation provides textual descriptions of ongoing events in videos. It supports accessibility and engagement in domains such as sports, esports, and livestreaming. Commentary generation involves two essential decisions: what to say and when to say it. While recent prompting-based approaches using multimodal large language models (MLLMs) have shown strong performance in content generation, they largely ignore the timing aspect. We investigate whether in-context prompting alone can support real-time commentary generation that is both semantically relevant and well-timed. We propose two prompting-based decoding strategies: 1) a fixed-interval approach, and 2) a novel dynamic interval-based decoding approach that adjusts the next prediction timing based on the estimated duration of the previous utterance. Both methods enable pause-aware generation without any fine-tuning. Experiments on Japanese and English datasets of racing and fighting games show that the dynamic interval-based decoding can generate commentary more closely aligned with human utterance timing and content using prompting alone. We release a multilingual benchmark dataset, trained models, and implementations to support future research on real-time video commentary generation.
SoK: Privacy Risks and Mitigations in Retrieval-Augmented Generation Systems
Jan 07, 2026The continued promise of Large Language Models (LLMs), particularly in their natural language understanding and generation capabilities, has driven a rapidly increasing interest in identifying and developing LLM use cases. In an effort to complement the ingrained "knowledge" of LLMs, Retrieval-Augmented Generation (RAG) techniques have become widely popular. At its core, RAG involves the coupling of LLMs with domain-specific knowledge bases, whereby the generation of a response to a user question is augmented with contextual and up-to-date information. The proliferation of RAG has sparked concerns about data privacy, particularly with the inherent risks that arise when leveraging databases with potentially sensitive information. Numerous recent works have explored various aspects of privacy risks in RAG systems, from adversarial attacks to proposed mitigations. With the goal of surveying and unifying these works, we ask one simple question: What are the privacy risks in RAG, and how can they be measured and mitigated? To answer this question, we conduct a systematic literature review of RAG works addressing privacy, and we systematize our findings into a comprehensive set of privacy risks, mitigation techniques, and evaluation strategies. We supplement these findings with two primary artifacts: a Taxonomy of RAG Privacy Risks and a RAG Privacy Process Diagram. Our work contributes to the study of privacy in RAG not only by conducting the first systematization of risks and mitigations, but also by uncovering important considerations when mitigating privacy risks in RAG systems and assessing the current maturity of proposed mitigations.
Facts Fade Fast: Evaluating Memorization of Outdated Medical Knowledge in Large Language Models
Sep 04, 2025The growing capabilities of Large Language Models (LLMs) show significant potential to enhance healthcare by assisting medical researchers and physicians. However, their reliance on static training data is a major risk when medical recommendations evolve with new research and developments. When LLMs memorize outdated medical knowledge, they can provide harmful advice or fail at clinical reasoning tasks. To investigate this problem, we introduce two novel question-answering (QA) datasets derived from systematic reviews: MedRevQA (16,501 QA pairs covering general biomedical knowledge) and MedChangeQA (a subset of 512 QA pairs where medical consensus has changed over time). Our evaluation of eight prominent LLMs on the datasets reveals consistent reliance on outdated knowledge across all models. We additionally analyze the influence of obsolete pre-training data and training strategies to explain this phenomenon and propose future directions for mitigation, laying the groundwork for developing more current and reliable medical AI systems.
Leveraging Semantic Triples for Private Document Generation with Local Differential Privacy Guarantees
Aug 28, 2025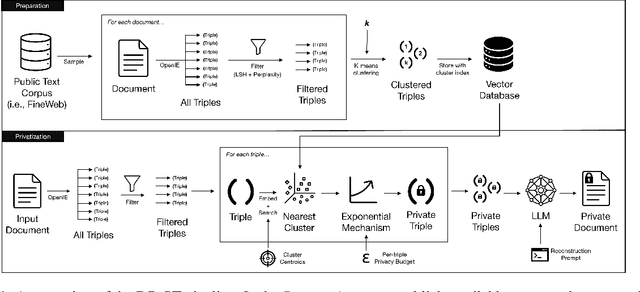
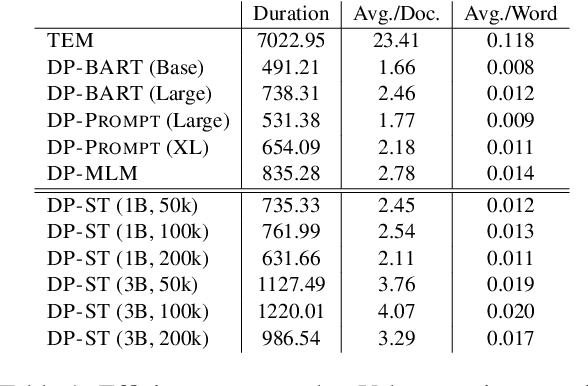
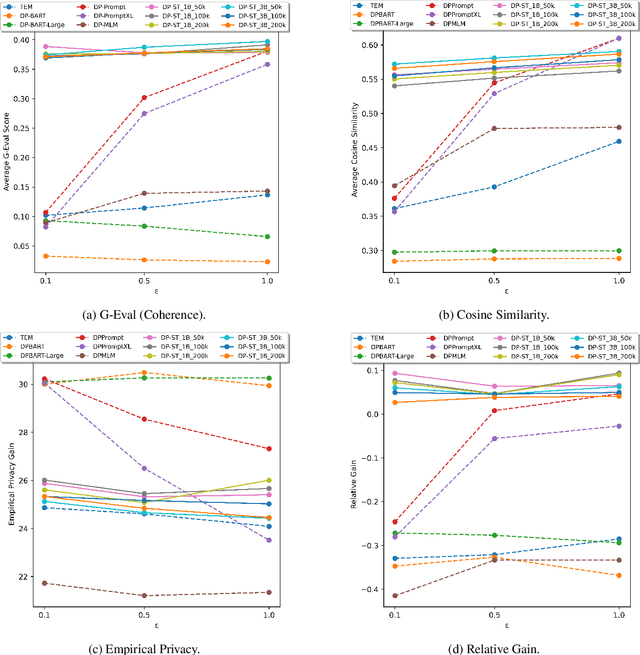

Many works at the intersection of Differential Privacy (DP) in Natural Language Processing aim to protect privacy by transforming texts under DP guarantees. This can be performed in a variety of ways, from word perturbations to full document rewriting, and most often under local DP. Here, an input text must be made indistinguishable from any other potential text, within some bound governed by the privacy parameter $\varepsilon$. Such a guarantee is quite demanding, and recent works show that privatizing texts under local DP can only be done reasonably under very high $\varepsilon$ values. Addressing this challenge, we introduce DP-ST, which leverages semantic triples for neighborhood-aware private document generation under local DP guarantees. Through the evaluation of our method, we demonstrate the effectiveness of the divide-and-conquer paradigm, particularly when limiting the DP notion (and privacy guarantees) to that of a privatization neighborhood. When combined with LLM post-processing, our method allows for coherent text generation even at lower $\varepsilon$ values, while still balancing privacy and utility. These findings highlight the importance of coherence in achieving balanced privatization outputs at reasonable $\varepsilon$ levels.
The Double-edged Sword of LLM-based Data Reconstruction: Understanding and Mitigating Contextual Vulnerability in Word-level Differential Privacy Text Sanitization
Aug 26, 2025
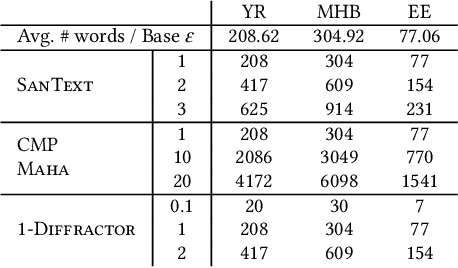


Differentially private text sanitization refers to the process of privatizing texts under the framework of Differential Privacy (DP), providing provable privacy guarantees while also empirically defending against adversaries seeking to harm privacy. Despite their simplicity, DP text sanitization methods operating at the word level exhibit a number of shortcomings, among them the tendency to leave contextual clues from the original texts due to randomization during sanitization $\unicode{x2013}$ this we refer to as $\textit{contextual vulnerability}$. Given the powerful contextual understanding and inference capabilities of Large Language Models (LLMs), we explore to what extent LLMs can be leveraged to exploit the contextual vulnerability of DP-sanitized texts. We expand on previous work not only in the use of advanced LLMs, but also in testing a broader range of sanitization mechanisms at various privacy levels. Our experiments uncover a double-edged sword effect of LLM-based data reconstruction attacks on privacy and utility: while LLMs can indeed infer original semantics and sometimes degrade empirical privacy protections, they can also be used for good, to improve the quality and privacy of DP-sanitized texts. Based on our findings, we propose recommendations for using LLM data reconstruction as a post-processing step, serving to increase privacy protection by thinking adversarially.
LLMs for Legal Subsumption in German Employment Contracts
Jul 02, 2025Legal work, characterized by its text-heavy and resource-intensive nature, presents unique challenges and opportunities for NLP research. While data-driven approaches have advanced the field, their lack of interpretability and trustworthiness limits their applicability in dynamic legal environments. To address these issues, we collaborated with legal experts to extend an existing dataset and explored the use of Large Language Models (LLMs) and in-context learning to evaluate the legality of clauses in German employment contracts. Our work evaluates the ability of different LLMs to classify clauses as "valid," "unfair," or "void" under three legal context variants: no legal context, full-text sources of laws and court rulings, and distilled versions of these (referred to as examination guidelines). Results show that full-text sources moderately improve performance, while examination guidelines significantly enhance recall for void clauses and weighted F1-Score, reaching 80\%. Despite these advancements, LLMs' performance when using full-text sources remains substantially below that of human lawyers. We contribute an extended dataset, including examination guidelines, referenced legal sources, and corresponding annotations, alongside our code and all log files. Our findings highlight the potential of LLMs to assist lawyers in contract legality review while also underscoring the limitations of the methods presented.
Correcting Hallucinations in News Summaries: Exploration of Self-Correcting LLM Methods with External Knowledge
Jun 24, 2025While large language models (LLMs) have shown remarkable capabilities to generate coherent text, they suffer from the issue of hallucinations -- factually inaccurate statements. Among numerous approaches to tackle hallucinations, especially promising are the self-correcting methods. They leverage the multi-turn nature of LLMs to iteratively generate verification questions inquiring additional evidence, answer them with internal or external knowledge, and use that to refine the original response with the new corrections. These methods have been explored for encyclopedic generation, but less so for domains like news summarization. In this work, we investigate two state-of-the-art self-correcting systems by applying them to correct hallucinated summaries using evidence from three search engines. We analyze the results and provide insights into systems' performance, revealing interesting practical findings on the benefits of search engine snippets and few-shot prompts, as well as high alignment of G-Eval and human evaluation.
Improving Reliability and Explainability of Medical Question Answering through Atomic Fact Checking in Retrieval-Augmented LLMs
May 30, 2025



Large language models (LLMs) exhibit extensive medical knowledge but are prone to hallucinations and inaccurate citations, which pose a challenge to their clinical adoption and regulatory compliance. Current methods, such as Retrieval Augmented Generation, partially address these issues by grounding answers in source documents, but hallucinations and low fact-level explainability persist. In this work, we introduce a novel atomic fact-checking framework designed to enhance the reliability and explainability of LLMs used in medical long-form question answering. This method decomposes LLM-generated responses into discrete, verifiable units called atomic facts, each of which is independently verified against an authoritative knowledge base of medical guidelines. This approach enables targeted correction of errors and direct tracing to source literature, thereby improving the factual accuracy and explainability of medical Q&A. Extensive evaluation using multi-reader assessments by medical experts and an automated open Q&A benchmark demonstrated significant improvements in factual accuracy and explainability. Our framework achieved up to a 40% overall answer improvement and a 50% hallucination detection rate. The ability to trace each atomic fact back to the most relevant chunks from the database provides a granular, transparent explanation of the generated responses, addressing a major gap in current medical AI applications. This work represents a crucial step towards more trustworthy and reliable clinical applications of LLMs, addressing key prerequisites for clinical application and fostering greater confidence in AI-assisted healthcare.
Knowing Before Saying: LLM Representations Encode Information About Chain-of-Thought Success Before Completion
May 30, 2025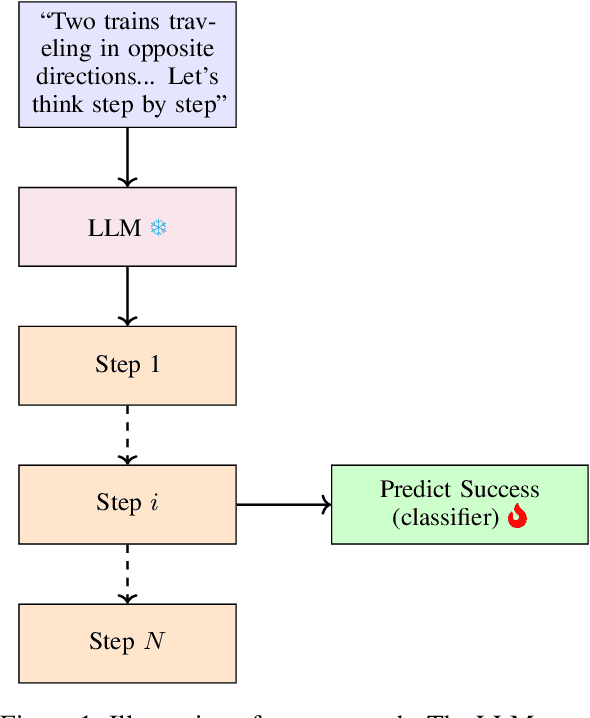
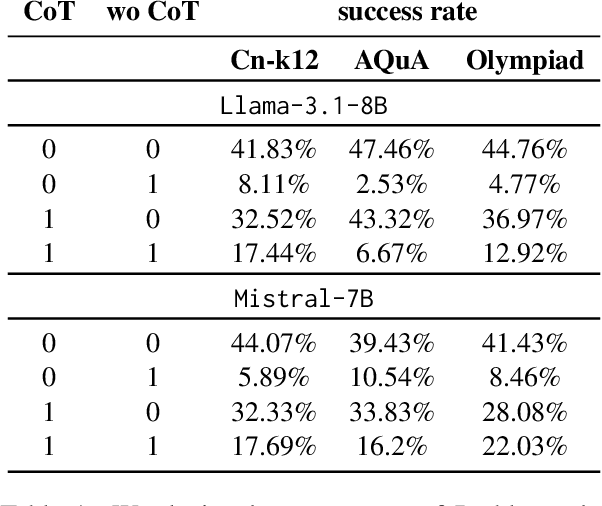
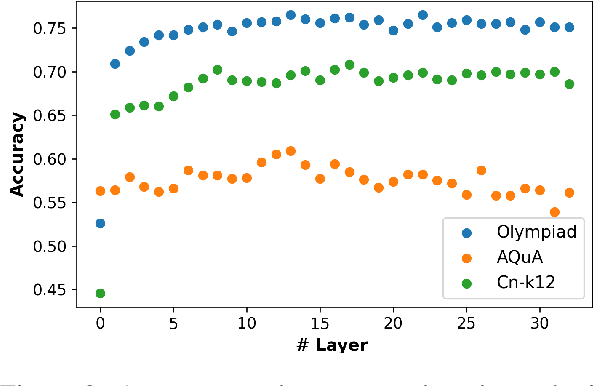
We investigate whether the success of a zero-shot Chain-of-Thought (CoT) process can be predicted before completion. We discover that a probing classifier, based on LLM representations, performs well \emph{even before a single token is generated}, suggesting that crucial information about the reasoning process is already present in the initial steps representations. In contrast, a strong BERT-based baseline, which relies solely on the generated tokens, performs worse, likely because it depends on shallow linguistic cues rather than deeper reasoning dynamics. Surprisingly, using later reasoning steps does not always improve classification. When additional context is unhelpful, earlier representations resemble later ones more, suggesting LLMs encode key information early. This implies reasoning can often stop early without loss. To test this, we conduct early stopping experiments, showing that truncating CoT reasoning still improves performance over not using CoT at all, though a gap remains compared to full reasoning. However, approaches like supervised learning or reinforcement learning designed to shorten CoT chains could leverage our classifier's guidance to identify when early stopping is effective. Our findings provide insights that may support such methods, helping to optimize CoT's efficiency while preserving its benefits.\footnote{Code and data is available at \href{https://github.com/anum94/CoTpred}{\texttt{github.com/anum94/CoTpred}}.