 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing Before Saying: LLM Representations Encode Information About Chain-of-Thought Success Before Completion
May 30, 2025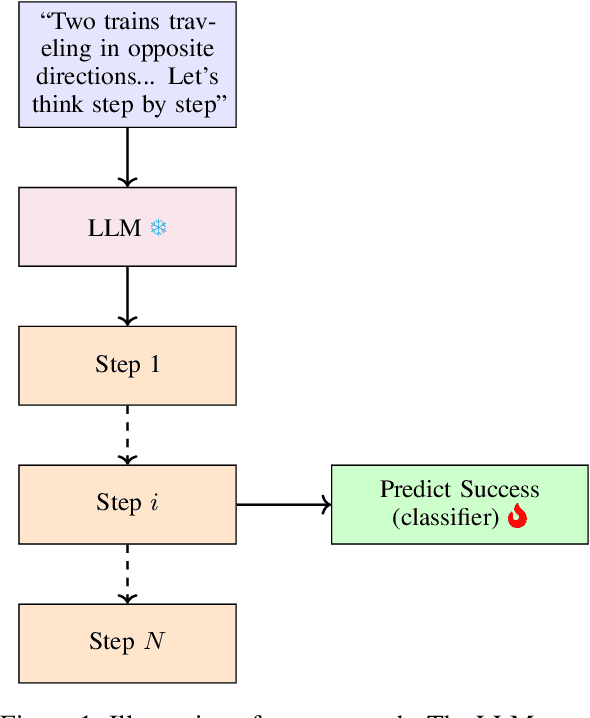
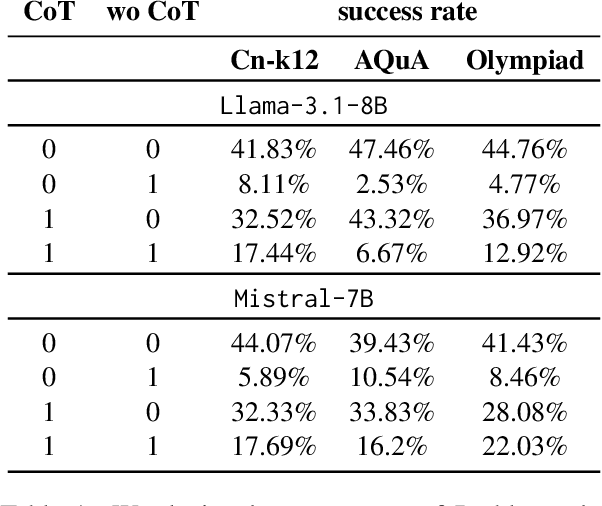
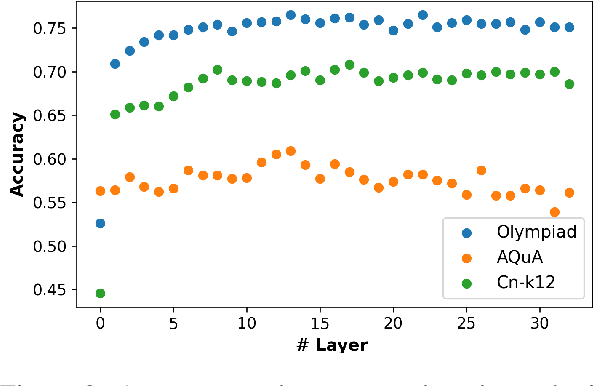
We investigate whether the success of a zero-shot Chain-of-Thought (CoT) process can be predicted before completion. We discover that a probing classifier, based on LLM representations, performs well \emph{even before a single token is generated}, suggesting that crucial information about the reasoning process is already present in the initial steps representations. In contrast, a strong BERT-based baseline, which relies solely on the generated tokens, performs worse, likely because it depends on shallow linguistic cues rather than deeper reasoning dynamics. Surprisingly, using later reasoning steps does not always improve classification. When additional context is unhelpful, earlier representations resemble later ones more, suggesting LLMs encode key information early. This implies reasoning can often stop early without loss. To test this, we conduct early stopping experiments, showing that truncating CoT reasoning still improves performance over not using CoT at all, though a gap remains compared to full reasoning. However, approaches like supervised learning or reinforcement learning designed to shorten CoT chains could leverage our classifier's guidance to identify when early stopping is effective. Our findings provide insights that may support such methods, helping to optimize CoT's efficiency while preserving its benefits.\footnote{Code and data is available at \href{https://github.com/anum94/CoTpred}{\texttt{github.com/anum94/CoTpred}}.
JaccDiv: A Metric and Benchmark for Quantifying Diversity of Generated Marketing Text in the Music Industry
Apr 29, 2025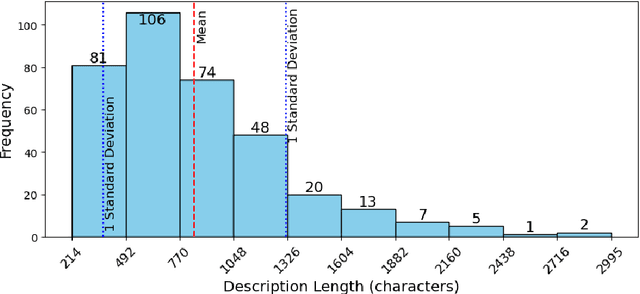
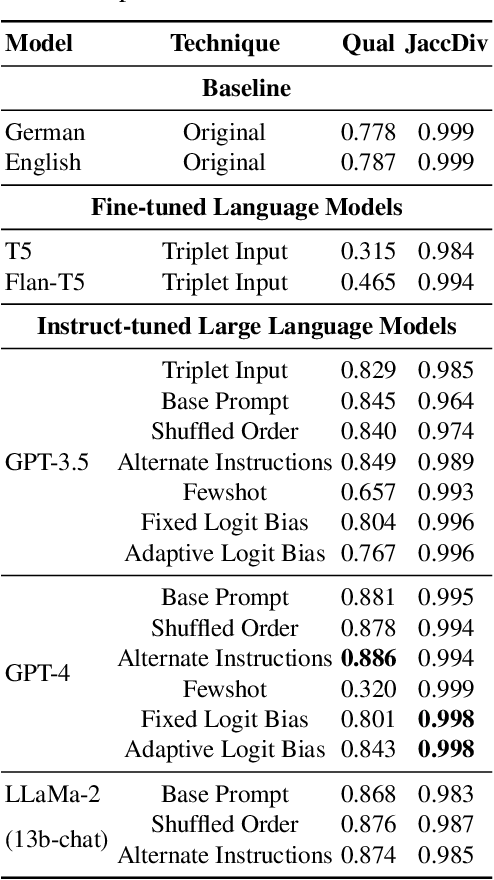


Online platforms are increasingly interested in using Data-to-Text technologies to generate content and help their users. Unfortunately, traditional generative methods often fall into repetitive patterns, resulting in monotonous galleries of texts after only a few iterations. In this paper, we investigate LLM-based data-to-text approaches to automatically generate marketing texts that are of sufficient quality and diverse enough for broad adoption. We leverage Language Models such as T5, GPT-3.5, GPT-4, and LLaMa2 in conjunction with fine-tuning, few-shot, and zero-shot approaches to set a baseline for diverse marketing texts. We also introduce a metric JaccDiv to evaluate the diversity of a set of texts. This research extends its relevance beyond the music industry, proving beneficial in various fields where repetitive automated content generation is prevalent.
Towards Optimizing a Retrieval Augmented Generation using Large Language Model on Academic Data
Nov 13, 2024



Given the growing trend of many organizations integrating Retrieval Augmented Generation (RAG) into their operations, we assess RAG on domain-specific data and test state-of-the-art models across various optimization techniques. We incorporate four optimizations; Multi-Query, Child-Parent-Retriever, Ensemble Retriever, and In-Context-Learning, to enhance the functionality and performance in the academic domain. We focus on data retrieval, specifically targeting various study programs at a large technical university. We additionally introduce a novel evaluation approach, the RAG Confusion Matrix designed to assess the effectiveness of various configurations within the RAG framework. By exploring the integration of both open-source (e.g., Llama2, Mistral) and closed-source (GPT-3.5 and GPT-4) Large Language Models, we offer valuable insights into the application and optimization of RAG frameworks in domain-specific contexts. Our experiments show a significant performance increase when including multi-query in the retrieval phase.
AdaptEval: Evaluating Large Language Models on Domain Adaptation for Text Summarization
Jul 16, 2024



Despite the advances in the abstractive summarization task using Large Language Models (LLM), there is a lack of research that asses their abilities to easily adapt to different domains. We evaluate the domain adaptation abilities of a wide range of LLMs on the summarization task across various domains in both fine-tuning and in-context learning settings. We also present AdaptEval, the first domain adaptation evaluation suite. AdaptEval includes a domain benchmark and a set of metrics to facilitate the analysis of domain adaptation. Our results demonstrate that LLMs exhibit comparable performance in the in-context learning setting, regardless of their parameter scale.
Towards Optimizing and Evaluating a Retrieval Augmented QA Chatbot using LLMs with Human in the Loop
Jul 08, 2024


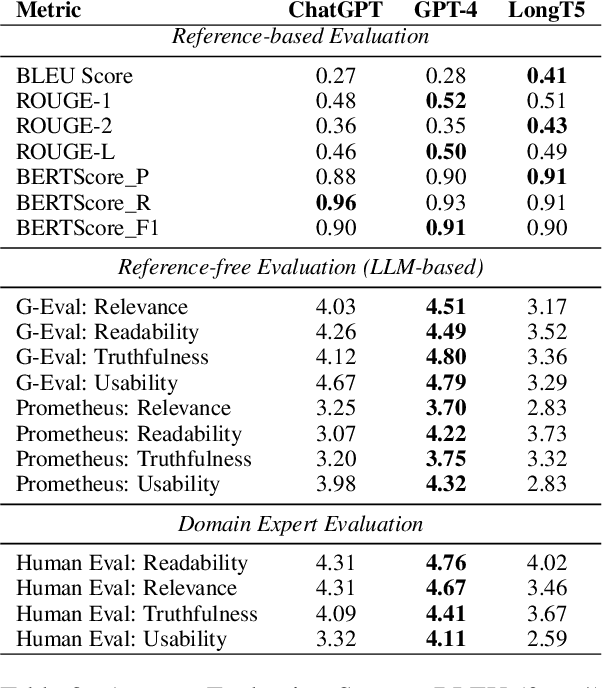
Large Language Models have found application in various mundane and repetitive tasks including Human Resource (HR) support. We worked with the domain experts of SAP SE to develop an HR support chatbot as an efficient and effective tool for addressing employee inquiries. We inserted a human-in-the-loop in various parts of the development cycles such as dataset collection, prompt optimization, and evaluation of generated output. By enhancing the LLM-driven chatbot's response quality and exploring alternative retrieval methods, we have created an efficient, scalable, and flexible tool for HR professionals to address employee inquiries effectively. Our experiments and evaluation conclude that GPT-4 outperforms other models and can overcome inconsistencies in data through internal reasoning capabilities. Additionally, through expert analysis, we infer that reference-free evaluation metrics such as G-Eval and Prometheus demonstrate reliability closely aligned with that of human evaluation.
Challenges in Domain-Specific Abstractive Summarization and How to Overcome them
Jul 03, 2023Large Language Models work quite well with general-purpose data and many tasks in Natural Language Processing. However, they show several limitations when used for a task such as domain-specific abstractive text summarization. This paper identifies three of those limitations as research problems in the context of abstractive text summarization: 1) Quadratic complexity of transformer-based models with respect to the input text length; 2) Model Hallucination, which is a model's ability to generate factually incorrect text; and 3) Domain Shift, which happens when the distribution of the model's training and test corpus is not the same. Along with a discussion of the open research questions, this paper also provides an assessment of existing state-of-the-art techniques relevant to domain-specific text summarization to address the research gaps.
Investigating Conversational Search Behavior For Domain Exploration
Jan 10, 2023Conversational search has evolved as a new information retrieval paradigm, marking a shift from traditional search systems towards interactive dialogues with intelligent search agents. This change especially affects exploratory information-seeking contexts, where conversational search systems can guide the discovery of unfamiliar domains. In these scenarios, users find it often difficult to express their information goals due to insufficient background knowledge. Conversational interfaces can provide assistance by eliciting information needs and narrowing down the search space. However, due to the complexity of information-seeking behavior, the design of conversational interfaces for retrieving information remains a great challenge. Although prior work has employed user studies to empirically ground the system design, most existing studies are limited to well-defined search tasks or known domains, thus being less exploratory in nature. Therefore, we conducted a laboratory study to investigate open-ended search behavior for navigation through unknown information landscapes. The study comprised of 26 participants who were restricted in their search to a text chat interface. Based on the collected dialogue transcripts, we applied statistical analyses and process mining techniques to uncover general information-seeking patterns across five different domains. We not only identify core dialogue acts and their interrelations that enable users to discover domain knowledge, but also derive design suggestions for conversational search systems.