 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Test-Time Compute Can Hurt: Overestimation Bias in LLM Beam Search
Mar 17, 2026Wider beam search should improve LLM reasoning, but when should you stop widening? Prior work on beam width selection has focused on inference efficiency \citep{qin2025dsbd, freitag2017beam}, without analyzing whether wider search can \emph{hurt} output quality. We present an analysis, grounded in Extreme Value Theory, that answers this question. Beam selection over noisy scorer outputs introduces a systematic overestimation bias that grows with the candidate pool size, and we derive a maximum useful beam width $\hat{k}$ beyond which search degrades performance. This critical width depends on the signal-to-noise ratio of the scorer: $\hat{k}$ grows exponentially with $(Δ/σ)^2$, where $Δ> 0$ is the quality advantage of correct paths over incorrect ones and $σ$ is the scorer noise. We validate this theory by comparing perplexity-guided and PRM-guided beam search across three 7B-parameter models and ten domains on MR-BEN (5,975 questions). Perplexity scoring, with its high noise, yields $\hat{k} = 1$: search provides no benefit at any width tested. PRM scoring, with lower noise, yields $\hat{k} \geq 4$, with gains of up to 8.9 percentage points. The same model, the same algorithm, but different scorers place $\hat{k}$ at opposite ends of the beam width range. Our analysis identifies the scorer's signal-to-noise ratio as the key quantity governing beam width selection, and we propose diagnostic indicators for choosing the beam width in practice.
Spanning the Visual Analogy Space with a Weight Basis of LoRAs
Feb 17, 2026Visual analogy learning enables image manipulation through demonstration rather than textual description, allowing users to specify complex transformations difficult to articulate in words. Given a triplet $\{\mathbf{a}$, $\mathbf{a}'$, $\mathbf{b}\}$, the goal is to generate $\mathbf{b}'$ such that $\mathbf{a} : \mathbf{a}' :: \mathbf{b} : \mathbf{b}'$. Recent methods adapt text-to-image models to this task using a single Low-Rank Adaptation (LoRA) module, but they face a fundamental limitation: attempting to capture the diverse space of visual transformations within a fixed adaptation module constrains generalization capabilities. Inspired by recent work showing that LoRAs in constrained domains span meaningful, interpolatable semantic spaces, we propose LoRWeB, a novel approach that specializes the model for each analogy task at inference time through dynamic composition of learned transformation primitives, informally, choosing a point in a "space of LoRAs". We introduce two key components: (1) a learnable basis of LoRA modules, to span the space of different visual transformations, and (2) a lightweight encoder that dynamically selects and weighs these basis LoRAs based on the input analogy pair. Comprehensive evaluations demonstrate our approach achieves state-of-the-art performance and significantly improves generalization to unseen visual transformations. Our findings suggest that LoRA basis decompositions are a promising direction for flexible visual manipulation. Code and data are in https://research.nvidia.com/labs/par/lorweb
Fast Autoregressive Video Diffusion and World Models with Temporal Cache Compression and Sparse Attention
Feb 02, 2026Autoregressive video diffusion models enable streaming generation, opening the door to long-form synthesis, video world models, and interactive neural game engines. However, their core attention layers become a major bottleneck at inference time: as generation progresses, the KV cache grows, causing both increasing latency and escalating GPU memory, which in turn restricts usable temporal context and harms long-range consistency. In this work, we study redundancy in autoregressive video diffusion and identify three persistent sources: near-duplicate cached keys across frames, slowly evolving (largely semantic) queries/keys that make many attention computations redundant, and cross-attention over long prompts where only a small subset of tokens matters per frame. Building on these observations, we propose a unified, training-free attention framework for autoregressive diffusion: TempCache compresses the KV cache via temporal correspondence to bound cache growth; AnnCA accelerates cross-attention by selecting frame-relevant prompt tokens using fast approximate nearest neighbor (ANN) matching; and AnnSA sparsifies self-attention by restricting each query to semantically matched keys, also using a lightweight ANN. Together, these modules reduce attention, compute, and memory and are compatible with existing autoregressive diffusion backbones and world models. Experiments demonstrate up to x5--x10 end-to-end speedups while preserving near-identical visual quality and, crucially, maintaining stable throughput and nearly constant peak GPU memory usage over long rollouts, where prior methods progressively slow down and suffer from increasing memory usage.
LR-DWM: Efficient Watermarking for Diffusion Language Models
Jan 18, 2026Watermarking (WM) is a critical mechanism for detecting and attributing AI-generated content. Current WM methods for Large Language Models (LLMs) are predominantly tailored for autoregressive (AR) models: They rely on tokens being generated sequentially, and embed stable signals within the generated sequence based on the previously sampled text. Diffusion Language Models (DLMs) generate text via non-sequential iterative denoising, which requires significant modification to use WM methods designed for AR models. Recent work proposed to watermark DLMs by inverting the process when needed, but suffers significant computational or memory overhead. We introduce Left-Right Diffusion Watermarking (LR-DWM), a scheme that biases the generated token based on both left and right neighbors, when they are available. LR-DWM incurs minimal runtime and memory overhead, remaining close to the non-watermarked baseline DLM while enabling reliable statistical detection under standard evaluation settings. Our results demonstrate that DLMs can be watermarked efficiently, achieving high detectability with negligible computational and memory overhead.
Per-Query Visual Concept Learning
Aug 12, 2025Visual concept learning, also known as Text-to-image personalization, is the process of teaching new concepts to a pretrained model. This has numerous applications from product placement to entertainment and personalized design. Here we show that many existing methods can be substantially augmented by adding a personalization step that is (1) specific to the prompt and noise seed, and (2) using two loss terms based on the self- and cross- attention, capturing the identity of the personalized concept. Specifically, we leverage PDM features -- previously designed to capture identity -- and show how they can be used to improve personalized semantic similarity. We evaluate the benefit that our method gains on top of six different personalization methods, and several base text-to-image models (both UNet- and DiT-based). We find significant improvements even over previous per-query personalization methods.
Knowing Before Saying: LLM Representations Encode Information About Chain-of-Thought Success Before Completion
May 30, 2025
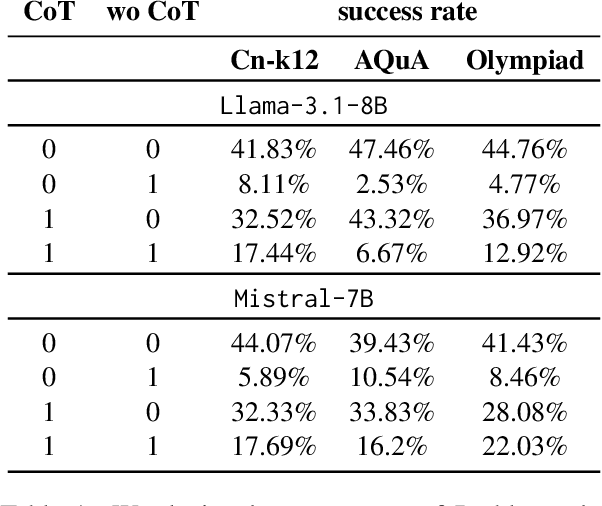
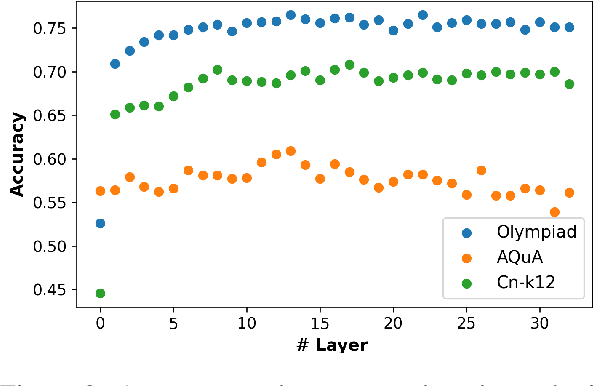
We investigate whether the success of a zero-shot Chain-of-Thought (CoT) process can be predicted before completion. We discover that a probing classifier, based on LLM representations, performs well \emph{even before a single token is generated}, suggesting that crucial information about the reasoning process is already present in the initial steps representations. In contrast, a strong BERT-based baseline, which relies solely on the generated tokens, performs worse, likely because it depends on shallow linguistic cues rather than deeper reasoning dynamics. Surprisingly, using later reasoning steps does not always improve classification. When additional context is unhelpful, earlier representations resemble later ones more, suggesting LLMs encode key information early. This implies reasoning can often stop early without loss. To test this, we conduct early stopping experiments, showing that truncating CoT reasoning still improves performance over not using CoT at all, though a gap remains compared to full reasoning. However, approaches like supervised learning or reinforcement learning designed to shorten CoT chains could leverage our classifier's guidance to identify when early stopping is effective. Our findings provide insights that may support such methods, helping to optimize CoT's efficiency while preserving its benefits.\footnote{Code and data is available at \href{https://github.com/anum94/CoTpred}{\texttt{github.com/anum94/CoTpred}}.
Policy Optimized Text-to-Image Pipeline Design
May 27, 2025Text-to-image generation has evolved beyond single monolithic models to complex multi-component pipelines. These combine fine-tuned generators, adapters, upscaling blocks and even editing steps, leading to significant improvements in image quality. However, their effective design requires substantial expertise. Recent approaches have shown promise in automating this process through large language models (LLMs), but they suffer from two critical limitations: extensive computational requirements from generating images with hundreds of predefined pipelines, and poor generalization beyond memorized training examples. We introduce a novel reinforcement learning-based framework that addresses these inefficiencies. Our approach first trains an ensemble of reward models capable of predicting image quality scores directly from prompt-workflow combinations, eliminating the need for costly image generation during training. We then implement a two-phase training strategy: initial workflow vocabulary training followed by GRPO-based optimization that guides the model toward higher-performing regions of the workflow space. Additionally, we incorporate a classifier-free guidance based enhancement technique that extrapolates along the path between the initial and GRPO-tuned models, further improving output quality. We validate our approach through a set of comparisons, showing that it can successfully create new flows with greater diversity and lead to superior image quality compared to existing baselines.
MaskedManipulator: Versatile Whole-Body Control for Loco-Manipulation
May 25, 2025Humans interact with their world while leveraging precise full-body control to achieve versatile goals. This versatility allows them to solve long-horizon, underspecified problems, such as placing a cup in a sink, by seamlessly sequencing actions like approaching the cup, grasping, transporting it, and finally placing it in the sink. Such goal-driven control can enable new procedural tools for animation systems, enabling users to define partial objectives while the system naturally ``fills in'' the intermediate motions. However, while current methods for whole-body dexterous manipulation in physics-based animation achieve success in specific interaction tasks, they typically employ control paradigms (e.g., detailed kinematic motion tracking, continuous object trajectory following, or direct VR teleoperation) that offer limited versatility for high-level goal specification across the entire coupled human-object system. To bridge this gap, we present MaskedManipulator, a unified and generative policy developed through a two-stage learning approach. First, our system trains a tracking controller to physically reconstruct complex human-object interactions from large-scale human mocap datasets. This tracking controller is then distilled into MaskedManipulator, which provides users with intuitive control over both the character's body and the manipulated object. As a result, MaskedManipulator enables users to specify complex loco-manipulation tasks through intuitive high-level objectives (e.g., target object poses, key character stances), and MaskedManipulator then synthesizes the necessary full-body actions for a physically simulated humanoid to achieve these goals, paving the way for more interactive and life-like virtual characters.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
May 18, 2025Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.
Efficient GNN Training Through Structure-Aware Randomized Mini-Batching
Apr 25, 2025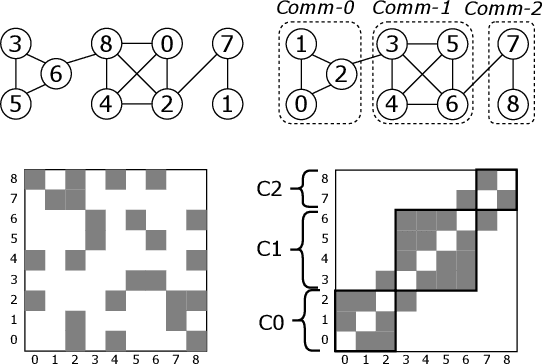

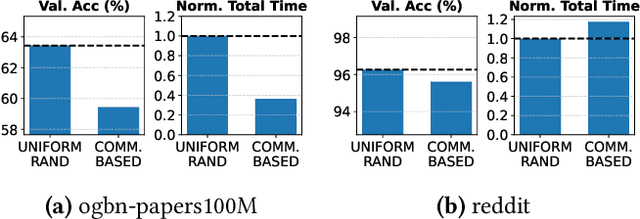
Graph Neural Networks (GNNs) enable learning on realworld graphs and mini-batch training has emerged as the de facto standard for training GNNs because it can scale to very large graphs and improve convergence. Current mini-batch construction policies largely ignore efficiency considerations of GNN training. Specifically, existing mini-batching techniques employ randomization schemes to improve accuracy and convergence. However, these randomization schemes are often agnostic to the structural properties of the graph (for eg. community structure), resulting in highly irregular memory access patterns during GNN training that make suboptimal use of on-chip GPU caches. On the other hand, while deterministic mini-batching based solely on graph structure delivers fast runtime performance, the lack of randomness compromises both the final model accuracy and training convergence speed. In this paper, we present Community-structure-aware Randomized Mini-batching (COMM-RAND), a novel methodology that bridges the gap between the above extremes. COMM-RAND allows practitioners to explore the space between pure randomness and pure graph structural awareness during mini-batch construction, leading to significantly more efficient GNN training with similar accuracy. We evaluated COMM-RAND across four popular graph learning benchmarks. COMM-RAND cuts down GNN training time by up to 2.76x (1.8x on average) while achieving an accuracy that is within 1.79% points (0.42% on average) compared to popular random mini-batching approaches.