 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
May 18, 2025Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.
MaskedMimic: Unified Physics-Based Character Control Through Masked Motion Inpainting
Sep 22, 2024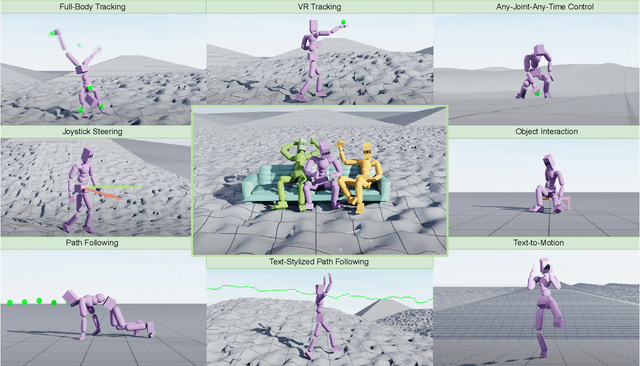
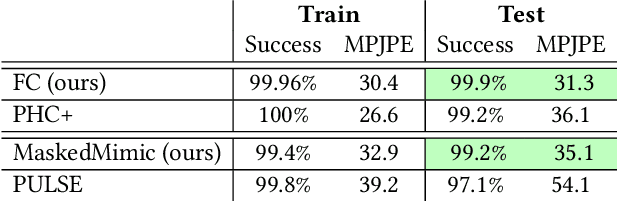

Crafting a single, versatile physics-based controller that can breathe life into interactive characters across a wide spectrum of scenarios represents an exciting frontier in character animation. An ideal controller should support diverse control modalities, such as sparse target keyframes, text instructions, and scene information. While previous works have proposed physically simulated, scene-aware control models, these systems have predominantly focused on developing controllers that each specializes in a narrow set of tasks and control modalities. This work presents MaskedMimic, a novel approach that formulates physics-based character control as a general motion inpainting problem. Our key insight is to train a single unified model to synthesize motions from partial (masked) motion descriptions, such as masked keyframes, objects, text descriptions, or any combination thereof. This is achieved by leveraging motion tracking data and designing a scalable training method that can effectively utilize diverse motion descriptions to produce coherent animations. Through this process, our approach learns a physics-based controller that provides an intuitive control interface without requiring tedious reward engineering for all behaviors of interest. The resulting controller supports a wide range of control modalities and enables seamless transitions between disparate tasks. By unifying character control through motion inpainting, MaskedMimic creates versatile virtual characters. These characters can dynamically adapt to complex scenes and compose diverse motions on demand, enabling more interactive and immersive experiences.
SuperPADL: Scaling Language-Directed Physics-Based Control with Progressive Supervised Distillation
Jul 15, 2024



Physically-simulated models for human motion can generate high-quality responsive character animations, often in real-time. Natural language serves as a flexible interface for controlling these models, allowing expert and non-expert users to quickly create and edit their animations. Many recent physics-based animation methods, including those that use text interfaces, train control policies using reinforcement learning (RL). However, scaling these methods beyond several hundred motions has remained challenging. Meanwhile, kinematic animation models are able to successfully learn from thousands of diverse motions by leveraging supervised learning methods. Inspired by these successes, in this work we introduce SuperPADL, a scalable framework for physics-based text-to-motion that leverages both RL and supervised learning to train controllers on thousands of diverse motion clips. SuperPADL is trained in stages using progressive distillation, starting with a large number of specialized experts using RL. These experts are then iteratively distilled into larger, more robust policies using a combination of reinforcement learning and supervised learning. Our final SuperPADL controller is trained on a dataset containing over 5000 skills and runs in real time on a consumer GPU. Moreover, our policy can naturally transition between skills, allowing for users to interactively craft multi-stage animations. We experimentally demonstrate that SuperPADL significantly outperforms RL-based baselines at this large data scale.
PACE: Human and Camera Motion Estimation from in-the-wild Videos
Oct 20, 2023



We present a method to estimate human motion in a global scene from moving cameras. This is a highly challenging task due to the coupling of human and camera motions in the video. To address this problem, we propose a joint optimization framework that disentangles human and camera motions using both foreground human motion priors and background scene features. Unlike existing methods that use SLAM as initialization, we propose to tightly integrate SLAM and human motion priors in an optimization that is inspired by bundle adjustment. Specifically, we optimize human and camera motions to match both the observed human pose and scene features. This design combines the strengths of SLAM and motion priors, which leads to significant improvements in human and camera motion estimation. We additionally introduce a motion prior that is suitable for batch optimization, making our approach significantly more efficient than existing approaches. Finally, we propose a novel synthetic dataset that enables evaluating camera motion in addition to human motion from dynamic videos. Experiments on the synthetic and real-world RICH datasets demonstrate that our approach substantially outperforms prior art in recovering both human and camera motions.
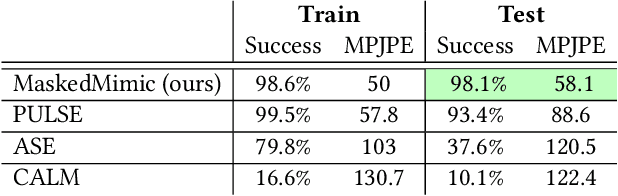
CALM: Conditional Adversarial Latent Models for Directable Virtual Characters
May 02, 2023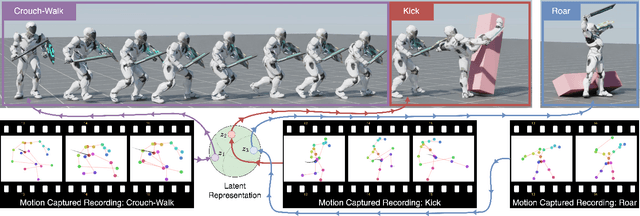
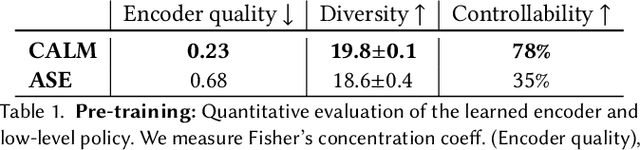
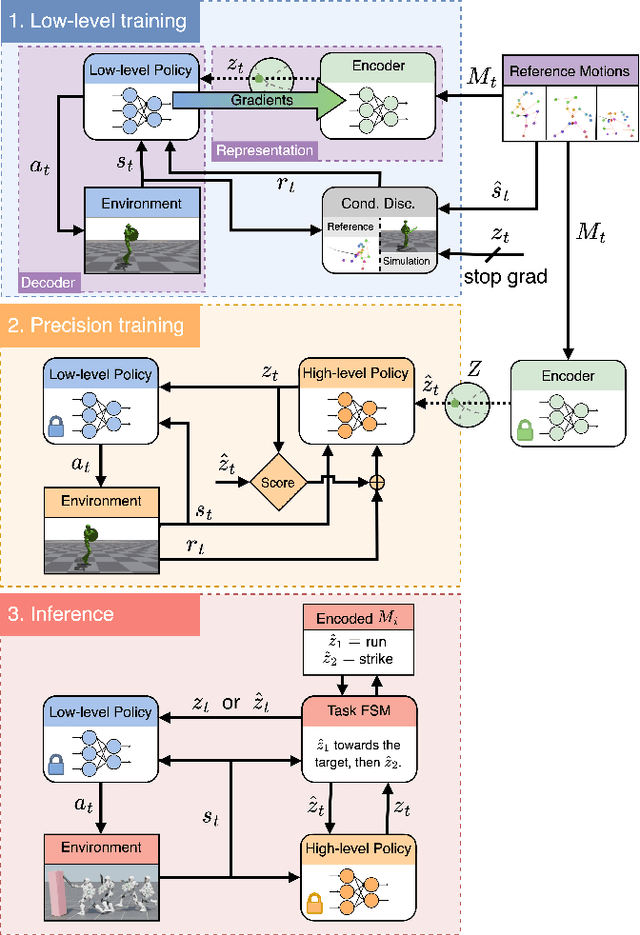
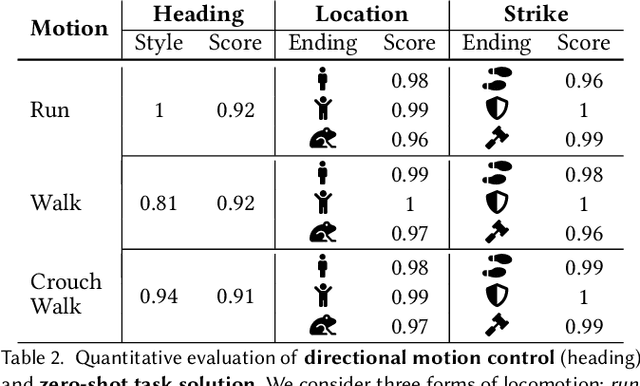
In this work, we present Conditional Adversarial Latent Models (CALM), an approach for generating diverse and directable behaviors for user-controlled interactive virtual characters. Using imitation learning, CALM learns a representation of movement that captures the complexity and diversity of human motion, and enables direct control over character movements. The approach jointly learns a control policy and a motion encoder that reconstructs key characteristics of a given motion without merely replicating it. The results show that CALM learns a semantic motion representation, enabling control over the generated motions and style-conditioning for higher-level task training. Once trained, the character can be controlled using intuitive interfaces, akin to those found in video games.
Synthesizing Physical Character-Scene Interactions
Feb 02, 2023Movement is how people interact with and affect their environment. For realistic character animation, it is necessary to synthesize such interactions between virtual characters and their surroundings. Despite recent progress in character animation using machine learning, most systems focus on controlling an agent's movements in fairly simple and homogeneous environments, with limited interactions with other objects. Furthermore, many previous approaches that synthesize human-scene interactions require significant manual labeling of the training data. In contrast, we present a system that uses adversarial imitation learning and reinforcement learning to train physically-simulated characters that perform scene interaction tasks in a natural and life-like manner. Our method learns scene interaction behaviors from large unstructured motion datasets, without manual annotation of the motion data. These scene interactions are learned using an adversarial discriminator that evaluates the realism of a motion within the context of a scene. The key novelty involves conditioning both the discriminator and the policy networks on scene context. We demonstrate the effectiveness of our approach through three challenging scene interaction tasks: carrying, sitting, and lying down, which require coordination of a character's movements in relation to objects in the environment. Our policies learn to seamlessly transition between different behaviors like idling, walking, and sitting. By randomizing the properties of the objects and their placements during training, our method is able to generalize beyond the objects and scenarios depicted in the training dataset, producing natural character-scene interactions for a wide variety of object shapes and placements. The approach takes physics-based character motion generation a step closer to broad applicability.
PADL: Language-Directed Physics-Based Character Control
Jan 31, 2023



Developing systems that can synthesize natural and life-like motions for simulated characters has long been a focus for computer animation. But in order for these systems to be useful for downstream applications, they need not only produce high-quality motions, but must also provide an accessible and versatile interface through which users can direct a character's behaviors. Natural language provides a simple-to-use and expressive medium for specifying a user's intent. Recent breakthroughs in natural language processing (NLP) have demonstrated effective use of language-based interfaces for applications such as image generation and program synthesis. In this work, we present PADL, which leverages recent innovations in NLP in order to take steps towards developing language-directed controllers for physics-based character animation. PADL allows users to issue natural language commands for specifying both high-level tasks and low-level skills that a character should perform. We present an adversarial imitation learning approach for training policies to map high-level language commands to low-level controls that enable a character to perform the desired task and skill specified by a user's commands. Furthermore, we propose a multi-task aggregation method that leverages a language-based multiple-choice question-answering approach to determine high-level task objectives from language commands. We show that our framework can be applied to effectively direct a simulated humanoid character to perform a diverse array of complex motor skills.
ORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
Jan 10, 2023



We present ORBIT, a unified and modular framework for robot learning powered by NVIDIA Isaac Sim. It offers a modular design to easily and efficiently create robotic environments with photo-realistic scenes and fast and accurate rigid and deformable body simulation. With ORBIT, we provide a suite of benchmark tasks of varying difficulty -- from single-stage cabinet opening and cloth folding to multi-stage tasks such as room reorganization. To support working with diverse observations and action spaces, we include fixed-arm and mobile manipulators with different physically-based sensors and motion generators. ORBIT allows training reinforcement learning policies and collecting large demonstration datasets from hand-crafted or expert solutions in a matter of minutes by leveraging GPU-based parallelization. In summary, we offer an open-sourced framework that readily comes with 16 robotic platforms, 4 sensor modalities, 10 motion generators, more than 20 benchmark tasks, and wrappers to 4 learning libraries. With this framework, we aim to support various research areas, including representation learning, reinforcement learning, imitation learning, and task and motion planning. We hope it helps establish interdisciplinary collaborations in these communities, and its modularity makes it easily extensible for more tasks and applications in the future. For videos, documentation, and code: https://isaac-orbit.github.io/.
Factory: Fast Contact for Robotic Assembly
May 07, 2022
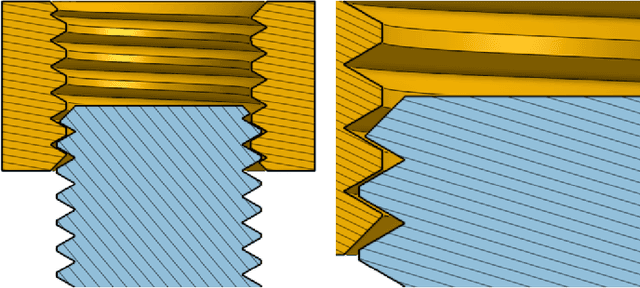


Robotic assembly is one of the oldest and most challenging applications of robotics. In other areas of robotics, such as perception and grasping, simulation has rapidly accelerated research progress, particularly when combined with modern deep learning. However, accurately, efficiently, and robustly simulating the range of contact-rich interactions in assembly remains a longstanding challenge. In this work, we present Factory, a set of physics simulation methods and robot learning tools for such applications. We achieve real-time or faster simulation of a wide range of contact-rich scenes, including simultaneous simulation of 1000 nut-and-bolt interactions. We provide $60$ carefully-designed part models, 3 robotic assembly environments, and 7 robot controllers for training and testing virtual robots. Finally, we train and evaluate proof-of-concept reinforcement learning policies for nut-and-bolt assembly. We aim for Factory to open the doors to using simulation for robotic assembly, as well as many other contact-rich applications in robotics. Please see https://sites.google.com/nvidia.com/factory for supplementary content, including videos.