 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors
Jun 03, 2026Scaling humanoid loco-manipulation requires robot-compatible demonstrations across diverse objects, whole-body motions, and scene geometries, but teleoperation and motion capture are difficult to scale because each collection depends on physical setups, instrumented actors, and robot operation. We present GRAIL, a digital generation pipeline that remains fully virtual until deployment: it composes 3D assets, simulator-ready scenes, and priors from video foundation models (VFMs) to synthesize interactions without rebuilding physical environments or teleoperating the robot. Rather than reconstructing unconstrained in-the-wild videos, GRAIL starts from fully specified 3D configurations in which object geometry, camera parameters, metric scale, environment depth, and a robot-proportioned character are known before video generation and reused during reconstruction. This privileged setup better conditions 4D recovery, allowing model-based object tracking, human motion estimation, and interaction-aware optimization to reconstruct metric 4D human-object interaction (HOI) trajectories with reduced depth ambiguity and morphology mismatch. We retarget the recovered motions to a humanoid robot and train complementary task-general trackers: an object-aware latent adaptor for manipulation and a scene-aware tracker for terrain traversal. GRAIL produces over 20,000 sequences spanning pick-up, object manipulation, sitting, and terrain traversal. Using only GRAIL-generated data, we train egocentric visual policies through a sim-to-real pipeline and deploy them on a Unitree G1 humanoid, achieving 84\% real-world success on diverse object pick-up and 90\% success on stair-climbing.
MotionBricks: Scalable Real-Time Motions with Modular Latent Generative Model and Smart Primitives
Apr 27, 2026Despite transformative advances in generative motion synthesis, real-time interactive motion control remains dominated by traditional techniques. In this work, we identify two key challenges in bridging research and production: 1) Real-time scalability: Industry applications demand real-time generation of a vast repertoire of motion skills, while generative methods exhibit significant degradation in quality and scalability under real-time computation constraints, and 2) Integration: Industry applications demand fine-grained multi-modal control involving velocity commands, style selection, and precise keyframes, a need largely unmet by existing text- or tag-driven models. To overcome these limitations, we introduce MotionBricks: a large-scale, real-time generative framework with a two-fold solution. First, we propose a large-scale modular latent generative backbone tailored for robust real-time motion generation, effectively modeling a dataset of over 350,000 motion clips with a single model. Second, we introduce smart primitives that provide a unified, robust, and intuitive interface for authoring both navigation and object interaction. Applications can be designed in a plug-and-play manner like assembling bricks without expert animation knowledge. Quantitatively, we show that MotionBricks produces state-of-the-art motion quality on open-source and proprietary datasets of various scales, while also achieving a real-time throughput of 15,000 FPS with 2ms latency. We demonstrate the flexibility and robustness of MotionBricks in a complete production-level animation demo, covering navigation and object-scene interaction across various styles with a unified model. To showcase our framework's application beyond animation, we deploy MotionBricks on the Unitree G1 humanoid robot to demonstrate its flexibility and generalization for real-time robotic control.
Kimodo: Scaling Controllable Human Motion Generation
Mar 16, 2026High-quality human motion data is becoming increasingly important for applications in robotics, simulation, and entertainment. Recent generative models offer a potential data source, enabling human motion synthesis through intuitive inputs like text prompts or kinematic constraints on poses. However, the small scale of public mocap datasets has limited the motion quality, control accuracy, and generalization of these models. In this work, we introduce Kimodo, an expressive and controllable kinematic motion diffusion model trained on 700 hours of optical motion capture data. Our model generates high-quality motions while being easily controlled through text and a comprehensive suite of kinematic constraints including full-body keyframes, sparse joint positions/rotations, 2D waypoints, and dense 2D paths. This is enabled through a carefully designed motion representation and two-stage denoiser architecture that decomposes root and body prediction to minimize motion artifacts while allowing for flexible constraint conditioning. Experiments on the large-scale mocap dataset justify key design decisions and analyze how the scaling of dataset size and model size affect performance.
CHIP: Adaptive Compliance for Humanoid Control through Hindsight Perturbation
Dec 16, 2025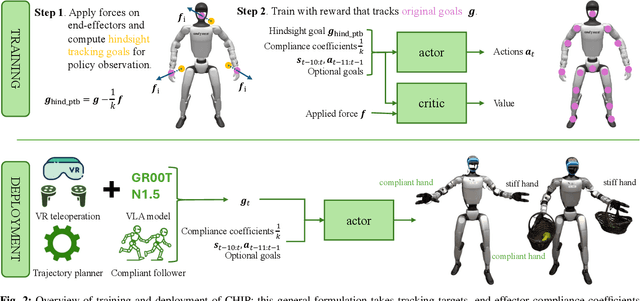
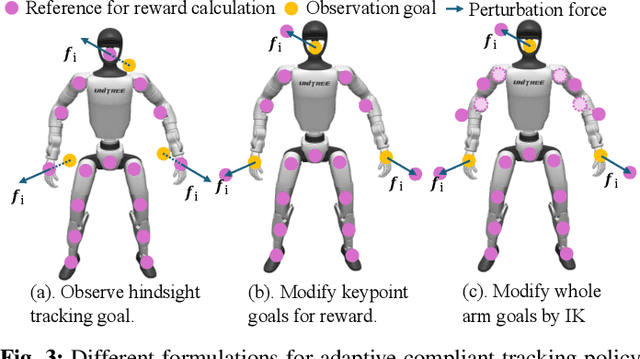
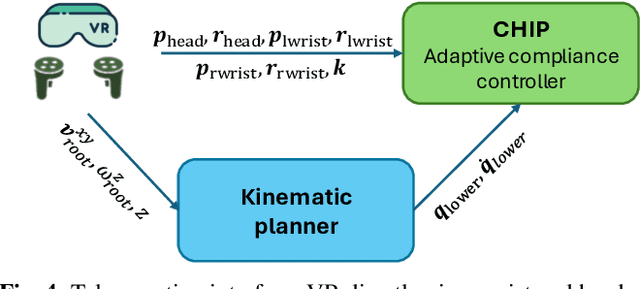

Recent progress in humanoid robots has unlocked agile locomotion skills, including backflipping, running, and crawling. Yet it remains challenging for a humanoid robot to perform forceful manipulation tasks such as moving objects, wiping, and pushing a cart. We propose adaptive Compliance Humanoid control through hIsight Perturbation (CHIP), a plug-and-play module that enables controllable end-effector stiffness while preserving agile tracking of dynamic reference motions. CHIP is easy to implement and requires neither data augmentation nor additional reward tuning. We show that a generalist motion-tracking controller trained with CHIP can perform a diverse set of forceful manipulation tasks that require different end-effector compliance, such as multi-robot collaboration, wiping, box delivery, and door opening.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Nov 11, 2025Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited behavior set, and are trained on a handful of GPUs over several days. We show that scaling up model capacity, data, and compute yields a generalist humanoid controller capable of creating natural and robust whole-body movements. Specifically, we posit motion tracking as a natural and scalable task for humanoid control, leverageing dense supervision from diverse motion-capture data to acquire human motion priors without manual reward engineering. We build a foundation model for motion tracking by scaling along three axes: network size (from 1.2M to 42M parameters), dataset volume (over 100M frames, 700 hours of high-quality motion data), and compute (9k GPU hours). Beyond demonstrating the benefits of scale, we show the practical utility of our model through two mechanisms: (1) a real-time universal kinematic planner that bridges motion tracking to downstream task execution, enabling natural and interactive control, and (2) a unified token space that supports various motion input interfaces, such as VR teleoperation devices, human videos, and vision-language-action (VLA) models, all using the same policy. Scaling motion tracking exhibits favorable properties: performance improves steadily with increased compute and data diversity, and learned representations generalize to unseen motions, establishing motion tracking at scale as a practical foundation for humanoid control.
Synthesizing Physical Character-Scene Interactions
Feb 02, 2023Movement is how people interact with and affect their environment. For realistic character animation, it is necessary to synthesize such interactions between virtual characters and their surroundings. Despite recent progress in character animation using machine learning, most systems focus on controlling an agent's movements in fairly simple and homogeneous environments, with limited interactions with other objects. Furthermore, many previous approaches that synthesize human-scene interactions require significant manual labeling of the training data. In contrast, we present a system that uses adversarial imitation learning and reinforcement learning to train physically-simulated characters that perform scene interaction tasks in a natural and life-like manner. Our method learns scene interaction behaviors from large unstructured motion datasets, without manual annotation of the motion data. These scene interactions are learned using an adversarial discriminator that evaluates the realism of a motion within the context of a scene. The key novelty involves conditioning both the discriminator and the policy networks on scene context. We demonstrate the effectiveness of our approach through three challenging scene interaction tasks: carrying, sitting, and lying down, which require coordination of a character's movements in relation to objects in the environment. Our policies learn to seamlessly transition between different behaviors like idling, walking, and sitting. By randomizing the properties of the objects and their placements during training, our method is able to generalize beyond the objects and scenarios depicted in the training dataset, producing natural character-scene interactions for a wide variety of object shapes and placements. The approach takes physics-based character motion generation a step closer to broad applicability.
Physics-based Human Motion Estimation and Synthesis from Videos
Sep 21, 2021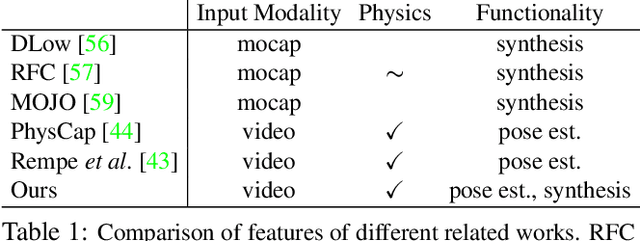
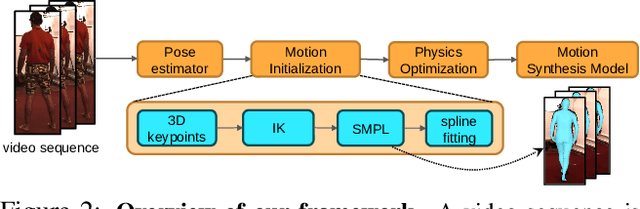


Human motion synthesis is an important problem with applications in graphics, gaming and simulation environments for robotics. Existing methods require accurate motion capture data for training, which is costly to obtain. Instead, we propose a framework for training generative models of physically plausible human motion directly from monocular RGB videos, which are much more widely available. At the core of our method is a novel optimization formulation that corrects imperfect image-based pose estimations by enforcing physics constraints and reasons about contacts in a differentiable way. This optimization yields corrected 3D poses and motions, as well as their corresponding contact forces. Results show that our physically-corrected motions significantly outperform prior work on pose estimation. We can then use these to train a generative model to synthesize future motion. We demonstrate both qualitatively and quantitatively significantly improved motion estimation, synthesis quality and physical plausibility achieved by our method on the large scale Human3.6m dataset \cite{h36m_pami} as compared to prior kinematic and physics-based methods. By enabling learning of motion synthesis from video, our method paves the way for large-scale, realistic and diverse motion synthesis.
UniCon: Universal Neural Controller For Physics-based Character Motion
Nov 30, 2020
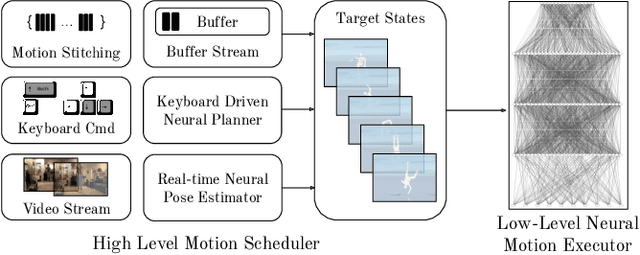

The field of physics-based animation is gaining importance due to the increasing demand for realism in video games and films, and has recently seen wide adoption of data-driven techniques, such as deep reinforcement learning (RL), which learn control from (human) demonstrations. While RL has shown impressive results at reproducing individual motions and interactive locomotion, existing methods are limited in their ability to generalize to new motions and their ability to compose a complex motion sequence interactively. In this paper, we propose a physics-based universal neural controller (UniCon) that learns to master thousands of motions with different styles by learning on large-scale motion datasets. UniCon is a two-level framework that consists of a high-level motion scheduler and an RL-powered low-level motion executor, which is our key innovation. By systematically analyzing existing multi-motion RL frameworks, we introduce a novel objective function and training techniques which make a significant leap in performance. Once trained, our motion executor can be combined with different high-level schedulers without the need for retraining, enabling a variety of real-time interactive applications. We show that UniCon can support keyboard-driven control, compose motion sequences drawn from a large pool of locomotion and acrobatics skills and teleport a person captured on video to a physics-based virtual avatar. Numerical and qualitative results demonstrate a significant improvement in efficiency, robustness and generalizability of UniCon over prior state-of-the-art, showcasing transferability to unseen motions, unseen humanoid models and unseen perturbation.
Learning to Generate Diverse Dance Motions with Transformer
Aug 18, 2020
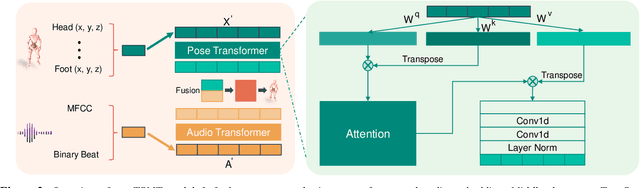

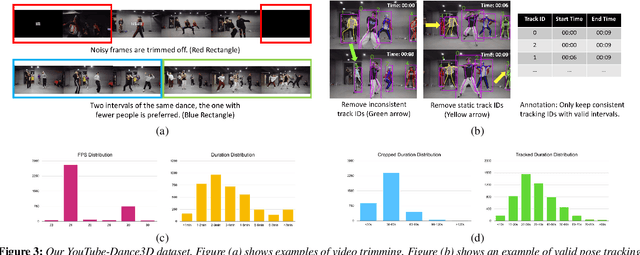
With the ongoing pandemic, virtual concerts and live events using digitized performances of musicians are getting traction on massive multiplayer online worlds. However, well choreographed dance movements are extremely complex to animate and would involve an expensive and tedious production process. In addition to the use of complex motion capture systems, it typically requires a collaborative effort between animators, dancers, and choreographers. We introduce a complete system for dance motion synthesis, which can generate complex and highly diverse dance sequences given an input music sequence. As motion capture data is limited for the range of dance motions and styles, we introduce a massive dance motion data set that is created from YouTube videos. We also present a novel two-stream motion transformer generative model, which can generate motion sequences with high flexibility. We also introduce new evaluation metrics for the quality of synthesized dance motions, and demonstrate that our system can outperform state-of-the-art methods. Our system provides high-quality animations suitable for large crowds for virtual concerts and can also be used as reference for professional animation pipelines. Most importantly, we show that vast online videos can be effective in training dance motion models.
Benchmarking Model-Based Reinforcement Learning
Jul 03, 2019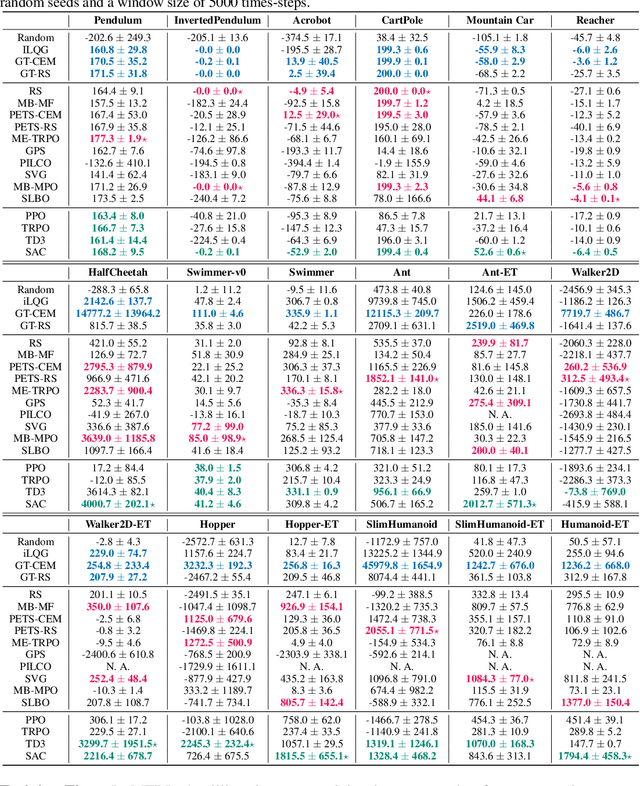
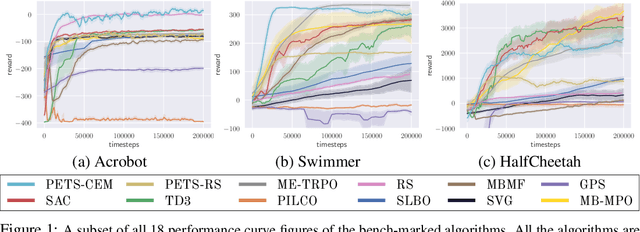
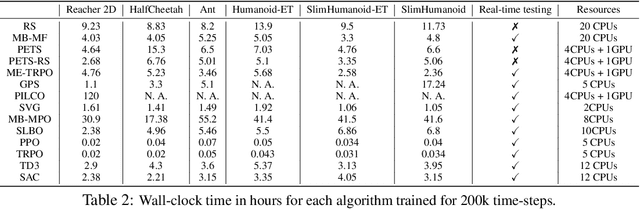
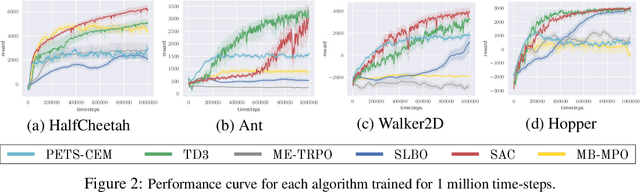
Model-based reinforcement learning (MBRL) is widely seen as having the potential to be significantly more sample efficient than model-free RL. However, research in model-based RL has not been very standardized. It is fairly common for authors to experiment with self-designed environments, and there are several separate lines of research, which are sometimes closed-sourced or not reproducible. Accordingly, it is an open question how these various existing MBRL algorithms perform relative to each other. To facilitate research in MBRL, in this paper we gather a wide collection of MBRL algorithms and propose over 18 benchmarking environments specially designed for MBRL. We benchmark these algorithms with unified problem settings, including noisy environments. Beyond cataloguing performance, we explore and unify the underlying algorithmic differences across MBRL algorithms. We characterize three key research challenges for future MBRL research: the dynamics bottleneck, the planning horizon dilemma, and the early-termination dilemma. Finally, to maximally facilitate future research on MBRL, we open-source our benchmark in http://www.cs.toronto.edu/~tingwuwang/mbrl.html.