 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtualHome: Simulating Household Activities via Programs
Jun 19, 2018

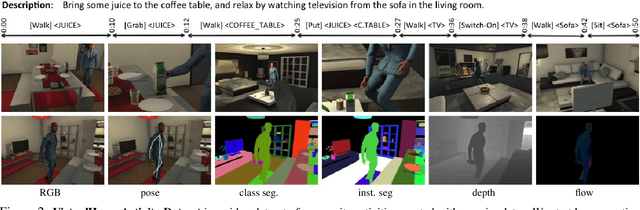

In this paper, we are interested in modeling complex activities that occur in a typical household. We propose to use programs, i.e., sequences of atomic actions and interactions, as a high level representation of complex tasks. Programs are interesting because they provide a non-ambiguous representation of a task, and allow agents to execute them. However, nowadays, there is no database providing this type of information. Towards this goal, we first crowd-source programs for a variety of activities that happen in people's homes, via a game-like interface used for teaching kids how to code. Using the collected dataset, we show how we can learn to extract programs directly from natural language descriptions or from videos. We then implement the most common atomic (inter)actions in the Unity3D game engine, and use our programs to "drive" an artificial agent to execute tasks in a simulated household environment. Our VirtualHome simulator allows us to create a large activity video dataset with rich ground-truth, enabling training and testing of video understanding models. We further showcase examples of our agent performing tasks in our VirtualHome based on language descriptions.
Learning a Hierarchical Compositional Shape Vocabulary for Multi-class Object Representation
Aug 23, 2014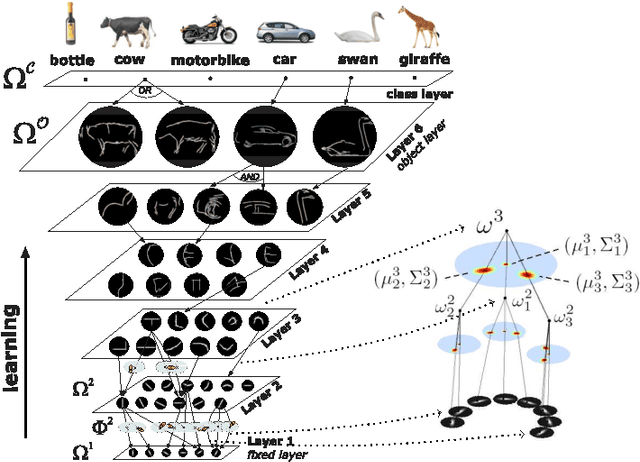
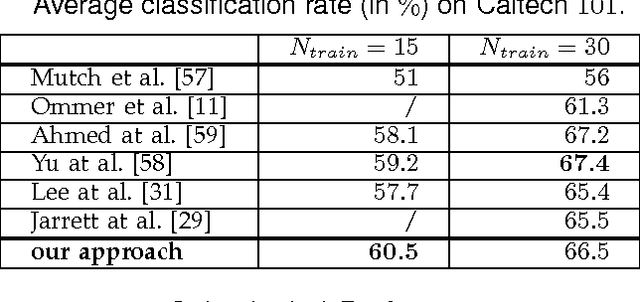
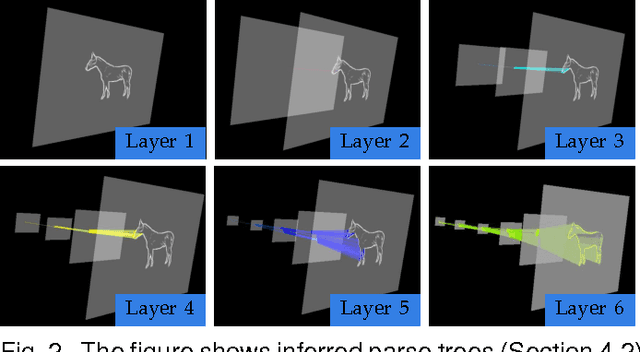
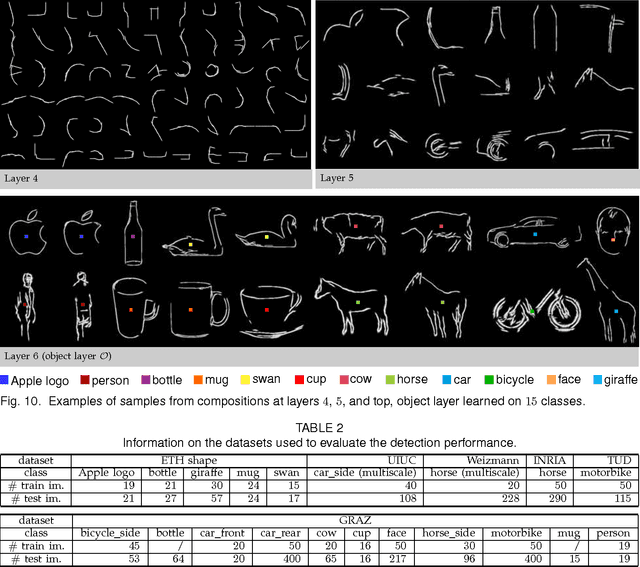
Hierarchies allow feature sharing between objects at multiple levels of representation, can code exponential variability in a very compact way and enable fast inference. This makes them potentially suitable for learning and recognizing a higher number of object classes. However, the success of the hierarchical approaches so far has been hindered by the use of hand-crafted features or predetermined grouping rules. This paper presents a novel framework for learning a hierarchical compositional shape vocabulary for representing multiple object classes. The approach takes simple contour fragments and learns their frequent spatial configurations. These are recursively combined into increasingly more complex and class-specific shape compositions, each exerting a high degree of shape variability. At the top-level of the vocabulary, the compositions are sufficiently large and complex to represent the whole shapes of the objects. We learn the vocabulary layer after layer, by gradually increasing the size of the window of analysis and reducing the spatial resolution at which the shape configurations are learned. The lower layers are learned jointly on images of all classes, whereas the higher layers of the vocabulary are learned incrementally, by presenting the algorithm with one object class after another. The experimental results show that the learned multi-class object representation scales favorably with the number of object classes and achieves a state-of-the-art detection performance at both, faster inference as well as shorter training times.