 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Attribution for Video Generation
Jan 13, 2026Despite the rapid progress of video generation models, the role of data in influencing motion is poorly understood. We present Motive (MOTIon attribution for Video gEneration), a motion-centric, gradient-based data attribution framework that scales to modern, large, high-quality video datasets and models. We use this to study which fine-tuning clips improve or degrade temporal dynamics. Motive isolates temporal dynamics from static appearance via motion-weighted loss masks, yielding efficient and scalable motion-specific influence computation. On text-to-video models, Motive identifies clips that strongly affect motion and guides data curation that improves temporal consistency and physical plausibility. With Motive-selected high-influence data, our method improves both motion smoothness and dynamic degree on VBench, achieving a 74.1% human preference win rate compared with the pretrained base model. To our knowledge, this is the first framework to attribute motion rather than visual appearance in video generative models and to use it to curate fine-tuning data.
RadarGen: Automotive Radar Point Cloud Generation from Cameras
Dec 19, 2025



We present RadarGen, a diffusion model for synthesizing realistic automotive radar point clouds from multi-view camera imagery. RadarGen adapts efficient image-latent diffusion to the radar domain by representing radar measurements in bird's-eye-view form that encodes spatial structure together with radar cross section (RCS) and Doppler attributes. A lightweight recovery step reconstructs point clouds from the generated maps. To better align generation with the visual scene, RadarGen incorporates BEV-aligned depth, semantic, and motion cues extracted from pretrained foundation models, which guide the stochastic generation process toward physically plausible radar patterns. Conditioning on images makes the approach broadly compatible, in principle, with existing visual datasets and simulation frameworks, offering a scalable direction for multimodal generative simulation. Evaluations on large-scale driving data show that RadarGen captures characteristic radar measurement distributions and reduces the gap to perception models trained on real data, marking a step toward unified generative simulation across sensing modalities.
ChronoEdit: Towards Temporal Reasoning for Image Editing and World Simulation
Oct 05, 2025Recent advances in large generative models have significantly advanced image editing and in-context image generation, yet a critical gap remains in ensuring physical consistency, where edited objects must remain coherent. This capability is especially vital for world simulation related tasks. In this paper, we present ChronoEdit, a framework that reframes image editing as a video generation problem. First, ChronoEdit treats the input and edited images as the first and last frames of a video, allowing it to leverage large pretrained video generative models that capture not only object appearance but also the implicit physics of motion and interaction through learned temporal consistency. Second, ChronoEdit introduces a temporal reasoning stage that explicitly performs editing at inference time. Under this setting, the target frame is jointly denoised with reasoning tokens to imagine a plausible editing trajectory that constrains the solution space to physically viable transformations. The reasoning tokens are then dropped after a few steps to avoid the high computational cost of rendering a full video. To validate ChronoEdit, we introduce PBench-Edit, a new benchmark of image-prompt pairs for contexts that require physical consistency, and demonstrate that ChronoEdit surpasses state-of-the-art baselines in both visual fidelity and physical plausibility. Code and models for both the 14B and 2B variants of ChronoEdit will be released on the project page: https://research.nvidia.com/labs/toronto-ai/chronoedit
LuxDiT: Lighting Estimation with Video Diffusion Transformer
Sep 03, 2025Estimating scene lighting from a single image or video remains a longstanding challenge in computer vision and graphics. Learning-based approaches are constrained by the scarcity of ground-truth HDR environment maps, which are expensive to capture and limited in diversity. While recent generative models offer strong priors for image synthesis, lighting estimation remains difficult due to its reliance on indirect visual cues, the need to infer global (non-local) context, and the recovery of high-dynamic-range outputs. We propose LuxDiT, a novel data-driven approach that fine-tunes a video diffusion transformer to generate HDR environment maps conditioned on visual input. Trained on a large synthetic dataset with diverse lighting conditions, our model learns to infer illumination from indirect visual cues and generalizes effectively to real-world scenes. To improve semantic alignment between the input and the predicted environment map, we introduce a low-rank adaptation finetuning strategy using a collected dataset of HDR panoramas. Our method produces accurate lighting predictions with realistic angular high-frequency details, outperforming existing state-of-the-art techniques in both quantitative and qualitative evaluations.
UniRelight: Learning Joint Decomposition and Synthesis for Video Relighting
Jun 18, 2025We address the challenge of relighting a single image or video, a task that demands precise scene intrinsic understanding and high-quality light transport synthesis. Existing end-to-end relighting models are often limited by the scarcity of paired multi-illumination data, restricting their ability to generalize across diverse scenes. Conversely, two-stage pipelines that combine inverse and forward rendering can mitigate data requirements but are susceptible to error accumulation and often fail to produce realistic outputs under complex lighting conditions or with sophisticated materials. In this work, we introduce a general-purpose approach that jointly estimates albedo and synthesizes relit outputs in a single pass, harnessing the generative capabilities of video diffusion models. This joint formulation enhances implicit scene comprehension and facilitates the creation of realistic lighting effects and intricate material interactions, such as shadows, reflections, and transparency. Trained on synthetic multi-illumination data and extensive automatically labeled real-world videos, our model demonstrates strong generalization across diverse domains and surpasses previous methods in both visual fidelity and temporal consistency.
Align Your Flow: Scaling Continuous-Time Flow Map Distillation
Jun 17, 2025Diffusion- and flow-based models have emerged as state-of-the-art generative modeling approaches, but they require many sampling steps. Consistency models can distill these models into efficient one-step generators; however, unlike flow- and diffusion-based methods, their performance inevitably degrades when increasing the number of steps, which we show both analytically and empirically. Flow maps generalize these approaches by connecting any two noise levels in a single step and remain effective across all step counts. In this paper, we introduce two new continuous-time objectives for training flow maps, along with additional novel training techniques, generalizing existing consistency and flow matching objectives. We further demonstrate that autoguidance can improve performance, using a low-quality model for guidance during distillation, and an additional boost can be achieved by adversarial finetuning, with minimal loss in sample diversity. We extensively validate our flow map models, called Align Your Flow, on challenging image generation benchmarks and achieve state-of-the-art few-step generation performance on both ImageNet 64x64 and 512x512, using small and efficient neural networks. Finally, we show text-to-image flow map models that outperform all existing non-adversarially trained few-step samplers in text-conditioned synthesis.
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025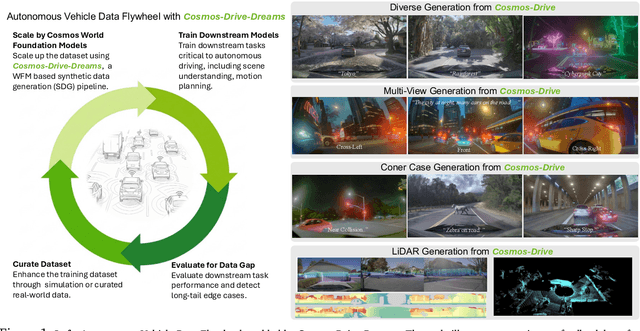
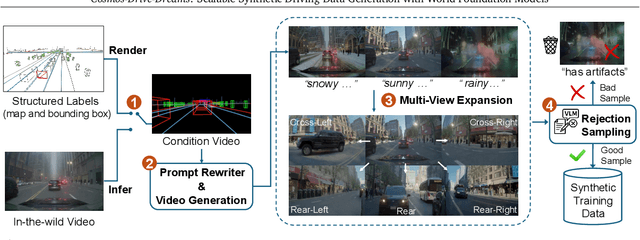
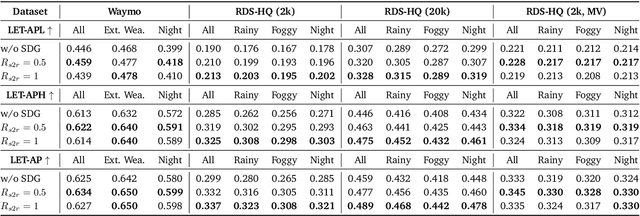
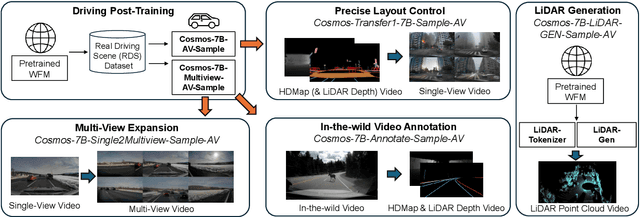
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
Socratic-MCTS: Test-Time Visual Reasoning by Asking the Right Questions
Jun 10, 2025Recent research in vision-language models (VLMs) has centered around the possibility of equipping them with implicit long-form chain-of-thought reasoning -- akin to the success observed in language models -- via distillation and reinforcement learning. But what about the non-reasoning models already trained and deployed across the internet? Should we simply abandon them, or is there hope for a search mechanism that can elicit hidden knowledge and induce long reasoning traces -- without any additional training or supervision? In this paper, we explore this possibility using a Monte Carlo Tree Search (MCTS)-inspired algorithm, which injects subquestion-subanswer pairs into the model's output stream. We show that framing reasoning as a search process -- where subquestions act as latent decisions within a broader inference trajectory -- helps the model "connect the dots" between fragmented knowledge and produce extended reasoning traces in non-reasoning models. We evaluate our method across three benchmarks and observe consistent improvements. Notably, our approach yields a 2% overall improvement on MMMU-PRO, including a significant 9% gain in Liberal Arts.
Controllable Weather Synthesis and Removal with Video Diffusion Models
May 01, 2025



Generating realistic and controllable weather effects in videos is valuable for many applications. Physics-based weather simulation requires precise reconstructions that are hard to scale to in-the-wild videos, while current video editing often lacks realism and control. In this work, we introduce WeatherWeaver, a video diffusion model that synthesizes diverse weather effects -- including rain, snow, fog, and clouds -- directly into any input video without the need for 3D modeling. Our model provides precise control over weather effect intensity and supports blending various weather types, ensuring both realism and adaptability. To overcome the scarcity of paired training data, we propose a novel data strategy combining synthetic videos, generative image editing, and auto-labeled real-world videos. Extensive evaluations show that our method outperforms state-of-the-art methods in weather simulation and removal, providing high-quality, physically plausible, and scene-identity-preserving results over various real-world videos.
LongPerceptualThoughts: Distilling System-2 Reasoning for System-1 Perception
Apr 21, 2025Recent reasoning models through test-time scaling have demonstrated that long chain-of-thoughts can unlock substantial performance boosts in hard reasoning tasks such as math and code. However, the benefit of such long thoughts for system-2 reasoning is relatively less explored in other domains such as perceptual tasks where shallower, system-1 reasoning seems sufficient. In this paper, we introduce LongPerceptualThoughts, a new synthetic dataset with 30K long-thought traces for perceptual tasks. The key challenges in synthesizing elaborate reasoning thoughts for perceptual tasks are that off-the-shelf models are not yet equipped with such thinking behavior and that it is not straightforward to build a reliable process verifier for perceptual tasks. Thus, we propose a novel three-stage data synthesis framework that first synthesizes verifiable multiple-choice questions from dense image descriptions, then extracts simple CoTs from VLMs for those verifiable problems, and finally expands those simple thoughts to elaborate long thoughts via frontier reasoning models. In controlled experiments with a strong instruction-tuned 7B model, we demonstrate notable improvements over existing visual reasoning data-generation methods. Our model, trained on the generated dataset, achieves an average +3.4 points improvement over 5 vision-centric benchmarks, including +11.8 points on V$^*$ Bench. Notably, despite being tuned for vision tasks, it also improves performance on the text reasoning benchmark, MMLU-Pro, by +2 points.