 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
Jun 02, 2026As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. In closed-loop simulation, the driving policy model actively interacts with the environment, where its actions dynamically update the simulator state and directly influence the next set of generated sensor observations. While recent reconstruction-based neural simulators offer photorealism, they are fundamentally constrained by their initial captured data and struggle to generalize to highly dynamic or novel scenes. To overcome these limitations, we introduce OmniDreams, a foundation generative world model mid- and post-trained from the Cosmos diffusion model to autoregressively generate action-conditioned videos in real time. By leveraging the rich visual priors of Cosmos and mid- and post-training on 21k hours of driving scenarios, OmniDreams synthesizes complex, unobserved phenomena that are hard for traditional simulators to capture, such as extreme weather and unpredictable dynamic agent behaviors. Crucially, it autoregressively conditions its photorealistic sensor generation on past frames, the current simulator state, and immediate driving actions. Deployed in a closed-loop system with the Alpamayo 1 policy model and AlpaSim orchestrator, OmniDreams acts as a highly responsive, reactive environment, providing a scalable and comprehensive solution for training and evaluating next-generation autonomous driving policies. We additionally show preliminary results indicating that a world-action model (WAM) post-trained from OmniDreams achieves strong performance on the Physical AI Autonomous Vehicles NuRec dataset, surpassing the VLA-based Alpamayo 1.5 research policy model while using only 1/5 the total parameters. These results highlight the potential for a real-time world model like OmniDreams to also serve as a backbone for policy architectures.
Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players
May 27, 2026World models for interactive video generation have largely focused on single-agent settings, where future observations are generated from a single control signal. However, many generated environments require multi-agent interaction: multiple players, robots, or embodied agents act simultaneously within a shared space. Scaling world models to such settings requires a principled multi-agent design: agents should remain independently controllable, permutation-symmetric, and support efficient inference while maintaining consistency across time and perspectives. In this paper, we present our generative multi-agent world model for interactive simulation. It introduces Simplex Rotary Agent Encoding, a parameter-free extension of 3D RoPE that represents agents as vertices of a regular simplex in rotary angle space. This gives each agent a distinct phase while making all agents permutation-equivalent, enabling scalable agent identity without learned per-slot identities or a fixed agent ordering. To avoid dense all-to-all attention across agents, we further propose Sparse Hub Attention, where learnable hub tokens mediate token interaction across agents, reducing cross-agent attention cost from quadratic to linear in the number of agents. For real-time rollout, we distill a full-context diffusion teacher into a causal student that generates temporal blocks sequentially with KV caching, enabling action-responsive generation at 24 FPS. Experiments in multiplayer virtual environments show that our model improves video fidelity, action controllability, and inter-agent consistency over slot-based and dense-attention baselines, while generalizing from two to four players without additional training.
Lyra 2.0: Explorable Generative 3D Worlds
Apr 14, 2026Recent advances in video generation enable a new paradigm for 3D scene creation: generating camera-controlled videos that simulate scene walkthroughs, then lifting them to 3D via feed-forward reconstruction techniques. This generative reconstruction approach combines the visual fidelity and creative capacity of video models with 3D outputs ready for real-time rendering and simulation. Scaling to large, complex environments requires 3D-consistent video generation over long camera trajectories with large viewpoint changes and location revisits, a setting where current video models degrade quickly. Existing methods for long-horizon generation are fundamentally limited by two forms of degradation: spatial forgetting and temporal drifting. As exploration proceeds, previously observed regions fall outside the model's temporal context, forcing the model to hallucinate structures when revisited. Meanwhile, autoregressive generation accumulates small synthesis errors over time, gradually distorting scene appearance and geometry. We present Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale. To address spatial forgetting, we maintain per-frame 3D geometry and use it solely for information routing -- retrieving relevant past frames and establishing dense correspondences with the target viewpoints -- while relying on the generative prior for appearance synthesis. To address temporal drifting, we train with self-augmented histories that expose the model to its own degraded outputs, teaching it to correct drift rather than propagate it. Together, these enable substantially longer and 3D-consistent video trajectories, which we leverage to fine-tune feed-forward reconstruction models that reliably recover high-quality 3D scenes.
MoRight: Motion Control Done Right
Apr 08, 2026Generating motion-controlled videos--where user-specified actions drive physically plausible scene dynamics under freely chosen viewpoints--demands two capabilities: (1) disentangled motion control, allowing users to separately control the object motion and adjust camera viewpoint; and (2) motion causality, ensuring that user-driven actions trigger coherent reactions from other objects rather than merely displacing pixels. Existing methods fall short on both fronts: they entangle camera and object motion into a single tracking signal and treat motion as kinematic displacement without modeling causal relationships between object motion. We introduce MoRight, a unified framework that addresses both limitations through disentangled motion modeling. Object motion is specified in a canonical static-view and transferred to an arbitrary target camera viewpoint via temporal cross-view attention, enabling disentangled camera and object control. We further decompose motion into active (user-driven) and passive (consequence) components, training the model to learn motion causality from data. At inference, users can either supply active motion and MoRight predicts consequences (forward reasoning), or specify desired passive outcomes and MoRight recovers plausible driving actions (inverse reasoning), all while freely adjusting the camera viewpoint. Experiments on three benchmarks demonstrate state-of-the-art performance in generation quality, motion controllability, and interaction awareness.
ArtiFixer: Enhancing and Extending 3D Reconstruction with Auto-Regressive Diffusion Models
Feb 28, 2026Per-scene optimization methods such as 3D Gaussian Splatting provide state-of-the-art novel view synthesis quality but extrapolate poorly to under-observed areas. Methods that leverage generative priors to correct artifacts in these areas hold promise but currently suffer from two shortcomings. The first is scalability, as existing methods use image diffusion models or bidirectional video models that are limited in the number of views they can generate in a single pass (and thus require a costly iterative distillation process for consistency). The second is quality itself, as generators used in prior work tend to produce outputs that are inconsistent with existing scene content and fail entirely in completely unobserved regions. To solve these, we propose a two-stage pipeline that leverages two key insights. First, we train a powerful bidirectional generative model with a novel opacity mixing strategy that encourages consistency with existing observations while retaining the model's ability to extrapolate novel content in unseen areas. Second, we distill it into a causal auto-regressive model that generates hundreds of frames in a single pass. This model can directly produce novel views or serve as pseudo-supervision to improve the underlying 3D representation in a simple and highly efficient manner. We evaluate our method extensively and demonstrate that it can generate plausible reconstructions in scenarios where existing approaches fail completely. When measured on commonly benchmarked datasets, we outperform existing all existing baselines by a wide margin, exceeding prior state-of-the-art methods by 1-3 dB PSNR.
Depth Completion as Parameter-Efficient Test-Time Adaptation
Feb 16, 2026We introduce CAPA, a parameter-efficient test-time optimization framework that adapts pre-trained 3D foundation models (FMs) for depth completion, using sparse geometric cues. Unlike prior methods that train task-specific encoders for auxiliary inputs, which often overfit and generalize poorly, CAPA freezes the FM backbone. Instead, it updates only a minimal set of parameters using Parameter-Efficient Fine-Tuning (e.g. LoRA or VPT), guided by gradients calculated directly from the sparse observations available at inference time. This approach effectively grounds the foundation model's geometric prior in the scene-specific measurements, correcting distortions and misplaced structures. For videos, CAPA introduces sequence-level parameter sharing, jointly adapting all frames to exploit temporal correlations, improve robustness, and enforce multi-frame consistency. CAPA is model-agnostic, compatible with any ViT-based FM, and achieves state-of-the-art results across diverse condition patterns on both indoor and outdoor datasets. Project page: research.nvidia.com/labs/dvl/projects/capa.
ChronoEdit: Towards Temporal Reasoning for Image Editing and World Simulation
Oct 05, 2025Recent advances in large generative models have significantly advanced image editing and in-context image generation, yet a critical gap remains in ensuring physical consistency, where edited objects must remain coherent. This capability is especially vital for world simulation related tasks. In this paper, we present ChronoEdit, a framework that reframes image editing as a video generation problem. First, ChronoEdit treats the input and edited images as the first and last frames of a video, allowing it to leverage large pretrained video generative models that capture not only object appearance but also the implicit physics of motion and interaction through learned temporal consistency. Second, ChronoEdit introduces a temporal reasoning stage that explicitly performs editing at inference time. Under this setting, the target frame is jointly denoised with reasoning tokens to imagine a plausible editing trajectory that constrains the solution space to physically viable transformations. The reasoning tokens are then dropped after a few steps to avoid the high computational cost of rendering a full video. To validate ChronoEdit, we introduce PBench-Edit, a new benchmark of image-prompt pairs for contexts that require physical consistency, and demonstrate that ChronoEdit surpasses state-of-the-art baselines in both visual fidelity and physical plausibility. Code and models for both the 14B and 2B variants of ChronoEdit will be released on the project page: https://research.nvidia.com/labs/toronto-ai/chronoedit
VideoMat: Extracting PBR Materials from Video Diffusion Models
Jun 11, 2025We leverage finetuned video diffusion models, intrinsic decomposition of videos, and physically-based differentiable rendering to generate high quality materials for 3D models given a text prompt or a single image. We condition a video diffusion model to respect the input geometry and lighting condition. This model produces multiple views of a given 3D model with coherent material properties. Secondly, we use a recent model to extract intrinsics (base color, roughness, metallic) from the generated video. Finally, we use the intrinsics alongside the generated video in a differentiable path tracer to robustly extract PBR materials directly compatible with common content creation tools.
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025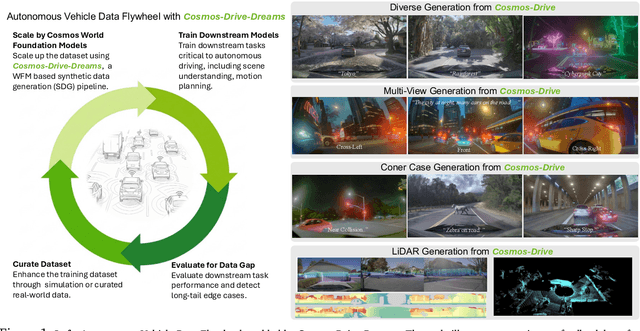
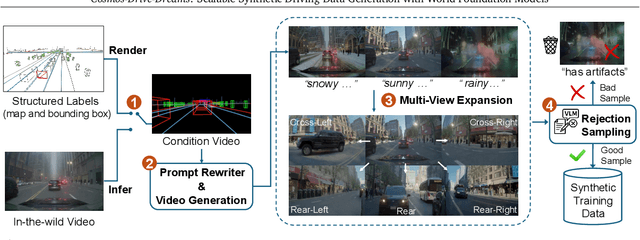
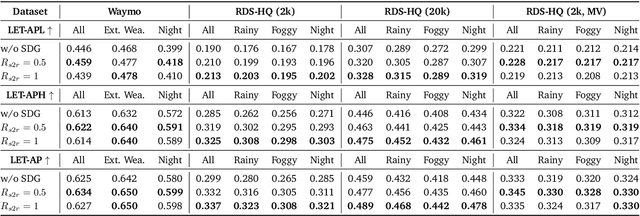
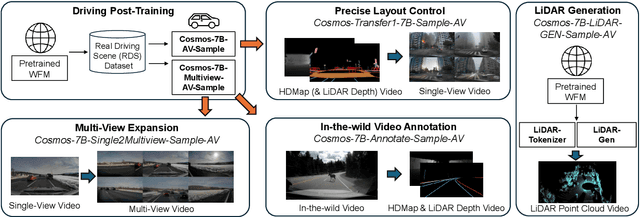
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.