 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDéjà View: Looping Transformers for Multi-View 3D Reconstruction
May 28, 2026Recent feed-forward 3D reconstruction transformers have scaled to over a billion parameters, following the broader trend of increasing model capacity in computer vision. Yet emerging evidence suggests that contiguous transformer layers often behave like repeated applications of similar operations, and multi-view reconstruction transformers refine their predictions progressively across decoder depth. We posit that model depth partially buys iteration, paid for inefficiently in unique parameters, and instead make that iteration explicit in architecture. Our model, DéjàView, applies a single looped transformer block recurrently to per-view features for K refinement steps. Trained once, it exposes K as an inference-time compute knob, matching or outperforming substantially larger feed-forward baselines across five reconstruction benchmarks spanning indoor, outdoor, object-centric, and driving scenes, while using a fraction of their parameters and comparable or lower compute. Importantly, the same looped block formulation outperforms an otherwise identical variant with independent per-step parameters under matched training data and compute, suggesting that explicit iteration is not merely a compute-efficient substitute for capacity but a stronger inductive bias for multi-view 3D reconstruction.
Depth Completion as Parameter-Efficient Test-Time Adaptation
Feb 16, 2026We introduce CAPA, a parameter-efficient test-time optimization framework that adapts pre-trained 3D foundation models (FMs) for depth completion, using sparse geometric cues. Unlike prior methods that train task-specific encoders for auxiliary inputs, which often overfit and generalize poorly, CAPA freezes the FM backbone. Instead, it updates only a minimal set of parameters using Parameter-Efficient Fine-Tuning (e.g. LoRA or VPT), guided by gradients calculated directly from the sparse observations available at inference time. This approach effectively grounds the foundation model's geometric prior in the scene-specific measurements, correcting distortions and misplaced structures. For videos, CAPA introduces sequence-level parameter sharing, jointly adapting all frames to exploit temporal correlations, improve robustness, and enforce multi-frame consistency. CAPA is model-agnostic, compatible with any ViT-based FM, and achieves state-of-the-art results across diverse condition patterns on both indoor and outdoor datasets. Project page: research.nvidia.com/labs/dvl/projects/capa.
RadarGen: Automotive Radar Point Cloud Generation from Cameras
Dec 19, 2025



We present RadarGen, a diffusion model for synthesizing realistic automotive radar point clouds from multi-view camera imagery. RadarGen adapts efficient image-latent diffusion to the radar domain by representing radar measurements in bird's-eye-view form that encodes spatial structure together with radar cross section (RCS) and Doppler attributes. A lightweight recovery step reconstructs point clouds from the generated maps. To better align generation with the visual scene, RadarGen incorporates BEV-aligned depth, semantic, and motion cues extracted from pretrained foundation models, which guide the stochastic generation process toward physically plausible radar patterns. Conditioning on images makes the approach broadly compatible, in principle, with existing visual datasets and simulation frameworks, offering a scalable direction for multimodal generative simulation. Evaluations on large-scale driving data show that RadarGen captures characteristic radar measurement distributions and reduces the gap to perception models trained on real data, marking a step toward unified generative simulation across sensing modalities.
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025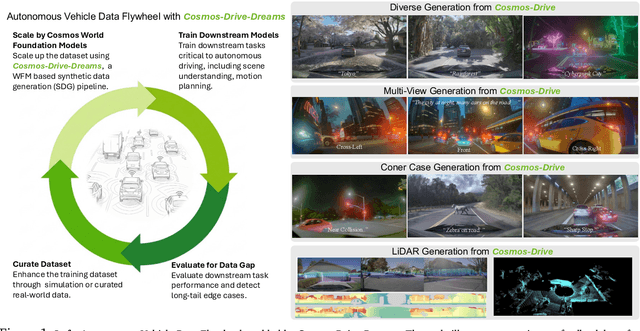
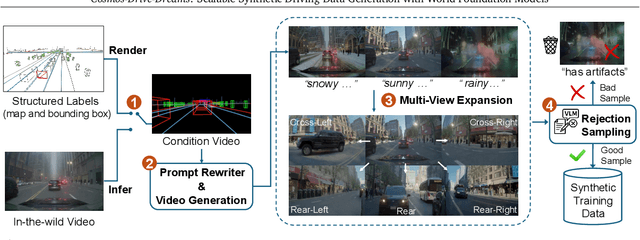
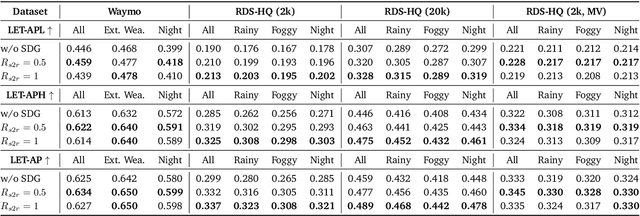
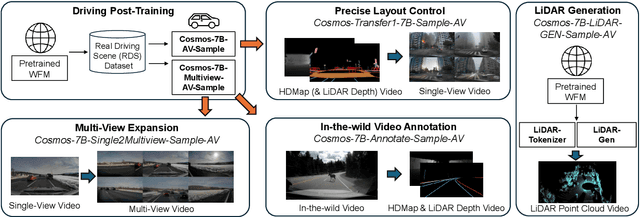
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
Rectified Point Flow: Generic Point Cloud Pose Estimation
Jun 05, 2025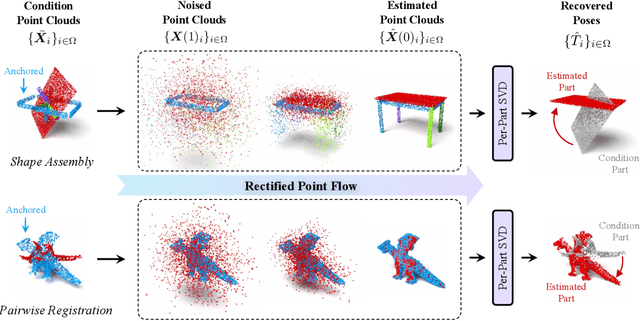
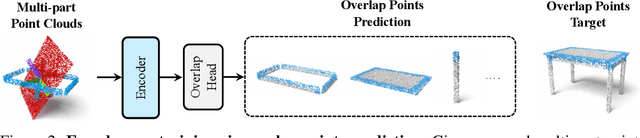
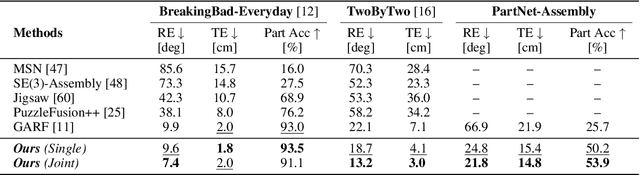
We introduce Rectified Point Flow, a unified parameterization that formulates pairwise point cloud registration and multi-part shape assembly as a single conditional generative problem. Given unposed point clouds, our method learns a continuous point-wise velocity field that transports noisy points toward their target positions, from which part poses are recovered. In contrast to prior work that regresses part-wise poses with ad-hoc symmetry handling, our method intrinsically learns assembly symmetries without symmetry labels. Together with a self-supervised encoder focused on overlapping points, our method achieves a new state-of-the-art performance on six benchmarks spanning pairwise registration and shape assembly. Notably, our unified formulation enables effective joint training on diverse datasets, facilitating the learning of shared geometric priors and consequently boosting accuracy. Project page: https://rectified-pointflow.github.io/.
Cross-modal feature fusion for robust point cloud registration with ambiguous geometry
May 19, 2025



Point cloud registration has seen significant advancements with the application of deep learning techniques. However, existing approaches often overlook the potential of integrating radiometric information from RGB images. This limitation reduces their effectiveness in aligning point clouds pairs, especially in regions where geometric data alone is insufficient. When used effectively, radiometric information can enhance the registration process by providing context that is missing from purely geometric data. In this paper, we propose CoFF, a novel Cross-modal Feature Fusion method that utilizes both point cloud geometry and RGB images for pairwise point cloud registration. Assuming that the co-registration between point clouds and RGB images is available, CoFF explicitly addresses the challenges where geometric information alone is unclear, such as in regions with symmetric similarity or planar structures, through a two-stage fusion of 3D point cloud features and 2D image features. It incorporates a cross-modal feature fusion module that assigns pixel-wise image features to 3D input point clouds to enhance learned 3D point features, and integrates patch-wise image features with superpoint features to improve the quality of coarse matching. This is followed by a coarse-to-fine matching module that accurately establishes correspondences using the fused features. We extensively evaluate CoFF on four common datasets: 3DMatch, 3DLoMatch, IndoorLRS, and the recently released ScanNet++ datasets. In addition, we assess CoFF on specific subset datasets containing geometrically ambiguous cases. Our experimental results demonstrate that CoFF achieves state-of-the-art registration performance across all benchmarks, including remarkable registration recalls of 95.9% and 81.6% on the widely-used 3DMatch and 3DLoMatch datasets, respectively...(Truncated to fit arXiv abstract length)
Marigold: Affordable Adaptation of Diffusion-Based Image Generators for Image Analysis
May 14, 2025The success of deep learning in computer vision over the past decade has hinged on large labeled datasets and strong pretrained models. In data-scarce settings, the quality of these pretrained models becomes crucial for effective transfer learning. Image classification and self-supervised learning have traditionally been the primary methods for pretraining CNNs and transformer-based architectures. Recently, the rise of text-to-image generative models, particularly those using denoising diffusion in a latent space, has introduced a new class of foundational models trained on massive, captioned image datasets. These models' ability to generate realistic images of unseen content suggests they possess a deep understanding of the visual world. In this work, we present Marigold, a family of conditional generative models and a fine-tuning protocol that extracts the knowledge from pretrained latent diffusion models like Stable Diffusion and adapts them for dense image analysis tasks, including monocular depth estimation, surface normals prediction, and intrinsic decomposition. Marigold requires minimal modification of the pre-trained latent diffusion model's architecture, trains with small synthetic datasets on a single GPU over a few days, and demonstrates state-of-the-art zero-shot generalization. Project page: https://marigoldcomputervision.github.io
Video Depth without Video Models
Nov 28, 2024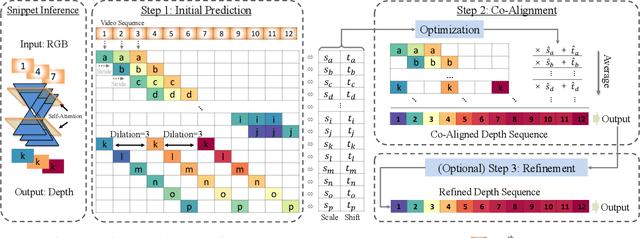
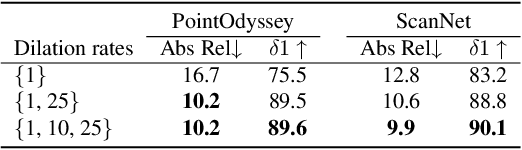
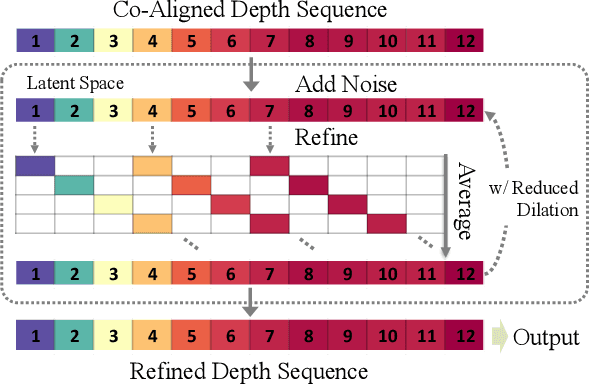
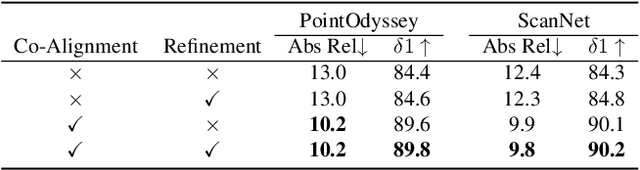
Video depth estimation lifts monocular video clips to 3D by inferring dense depth at every frame. Recent advances in single-image depth estimation, brought about by the rise of large foundation models and the use of synthetic training data, have fueled a renewed interest in video depth. However, naively applying a single-image depth estimator to every frame of a video disregards temporal continuity, which not only leads to flickering but may also break when camera motion causes sudden changes in depth range. An obvious and principled solution would be to build on top of video foundation models, but these come with their own limitations; including expensive training and inference, imperfect 3D consistency, and stitching routines for the fixed-length (short) outputs. We take a step back and demonstrate how to turn a single-image latent diffusion model (LDM) into a state-of-the-art video depth estimator. Our model, which we call RollingDepth, has two main ingredients: (i) a multi-frame depth estimator that is derived from a single-image LDM and maps very short video snippets (typically frame triplets) to depth snippets. (ii) a robust, optimization-based registration algorithm that optimally assembles depth snippets sampled at various different frame rates back into a consistent video. RollingDepth is able to efficiently handle long videos with hundreds of frames and delivers more accurate depth videos than both dedicated video depth estimators and high-performing single-frame models. Project page: rollingdepth.github.io.
LoopSplat: Loop Closure by Registering 3D Gaussian Splats
Aug 20, 2024



Simultaneous Localization and Mapping (SLAM) based on 3D Gaussian Splats (3DGS) has recently shown promise towards more accurate, dense 3D scene maps. However, existing 3DGS-based methods fail to address the global consistency of the scene via loop closure and/or global bundle adjustment. To this end, we propose LoopSplat, which takes RGB-D images as input and performs dense mapping with 3DGS submaps and frame-to-model tracking. LoopSplat triggers loop closure online and computes relative loop edge constraints between submaps directly via 3DGS registration, leading to improvements in efficiency and accuracy over traditional global-to-local point cloud registration. It uses a robust pose graph optimization formulation and rigidly aligns the submaps to achieve global consistency. Evaluation on the synthetic Replica and real-world TUM-RGBD, ScanNet, and ScanNet++ datasets demonstrates competitive or superior tracking, mapping, and rendering compared to existing methods for dense RGB-D SLAM. Code is available at loopsplat.github.io.
Living Scenes: Multi-object Relocalization and Reconstruction in Changing 3D Environments
Dec 14, 2023



Research into dynamic 3D scene understanding has primarily focused on short-term change tracking from dense observations, while little attention has been paid to long-term changes with sparse observations. We address this gap with MoRE, a novel approach for multi-object relocalization and reconstruction in evolving environments. We view these environments as "living scenes" and consider the problem of transforming scans taken at different points in time into a 3D reconstruction of the object instances, whose accuracy and completeness increase over time. At the core of our method lies an SE(3)-equivariant representation in a single encoder-decoder network, trained on synthetic data. This representation enables us to seamlessly tackle instance matching, registration, and reconstruction. We also introduce a joint optimization algorithm that facilitates the accumulation of point clouds originating from the same instance across multiple scans taken at different points in time. We validate our method on synthetic and real-world data and demonstrate state-of-the-art performance in both end-to-end performance and individual subtasks.