 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAG: Dual-Stream Video-Action Generation for Embodied Data Synthesis
Apr 10, 2026Recent advances in robot foundation models trained on large-scale human teleoperation data have enabled robots to perform increasingly complex real-world tasks. However, scaling these systems remains difficult because collecting task-specific demonstrations is expensive and labor-intensive. Synthetic data, especially generated videos, offer a promising direction, but existing World Models (WMs) are not directly suitable for policy learning since they do not provide paired action trajectories. World-Action (WA) models partially address this by predicting actions with visual outputs, yet often lack strong video-action alignment, while two-stage pipelines that generate video first and then infer actions introduce inefficiency and error accumulation. To address these limitations, we propose VAG, a unified flow-matching-based dual-stream framework that jointly generates video and action under visual and language conditioning. By synchronizing denoising in both branches and using an adaptive 3D pooling mechanism to transfer compact global video context to the action branch, VAG improves cross-modal consistency during generation. Across both simulated and real-world settings, VAG produces aligned video-action pairs with competitive prediction quality, supports executable trajectory replay, and provides useful synthetic pretraining data that improves downstream policy generalization, indicating its potential as a practical world-action model for embodied data synthesis.
EgoFlow: Gradient-Guided Flow Matching for Egocentric 6DoF Object Motion Generation
Apr 01, 2026Understanding and predicting object motion from egocentric video is fundamental to embodied perception and interaction. However, generating physically consistent 6DoF trajectories remains challenging due to occlusions, fast motion, and the lack of explicit physical reasoning in existing generative models. We present EgoFlow, a flow-matching framework that synthesizes realistic and physically plausible trajectories conditioned on multimodal egocentric observations. EgoFlow employs a hybrid Mamba-Transformer-Perceiver architecture to jointly model temporal dynamics, scene geometry, and semantic intent, while a gradient-guided inference process enforces differentiable physical constraints such as collision avoidance and motion smoothness. This combination yields coherent and controllable motion generation without post-hoc filtering or additional supervision. Experiments on real-world datasets HD-EPIC, EgoExo4D, and HOT3D show that EgoFlow outperforms diffusion-based and transformer baselines in accuracy, generalization, and physical realism, reducing collision rates by up to 79%, and strong generalization to unseen scenes. Our results highlight the promise of flow-based generative modeling for scalable and physically grounded egocentric motion understanding.
Enhancing Vision-Language Navigation with Multimodal Event Knowledge from Real-World Indoor Tour Videos
Feb 27, 2026Vision-Language Navigation (VLN) agents often struggle with long-horizon reasoning in unseen environments, particularly when facing ambiguous, coarse-grained instructions. While recent advances use knowledge graph to enhance reasoning, the potential of multimodal event knowledge inspired by human episodic memory remains underexplored. In this work, we propose an event-centric knowledge enhancement strategy for automated process knowledge mining and feature fusion to solve coarse-grained instruction and long-horizon reasoning in VLN task. First, we construct YE-KG, the first large-scale multimodal spatiotemporal knowledge graph, with over 86k nodes and 83k edges, derived from real-world indoor videos. By leveraging multimodal large language models (i.e., LLaVa, GPT4), we extract unstructured video streams into structured semantic-action-effect events to serve as explicit episodic memory. Second, we introduce STE-VLN, which integrates the above graph into VLN models via a Coarse-to-Fine Hierarchical Retrieval mechanism. This allows agents to retrieve causal event sequences and dynamically fuse them with egocentric visual observations. Experiments on REVERIE, R2R, and R2R-CE benchmarks demonstrate the efficiency of our event-centric strategy, outperforming state-of-the-art approaches across diverse action spaces. Our data and code are available on the project website https://sites.google.com/view/y-event-kg/.
FlowHOI: Flow-based Semantics-Grounded Generation of Hand-Object Interactions for Dexterous Robot Manipulation
Feb 13, 2026Recent vision-language-action (VLA) models can generate plausible end-effector motions, yet they often fail in long-horizon, contact-rich tasks because the underlying hand-object interaction (HOI) structure is not explicitly represented. An embodiment-agnostic interaction representation that captures this structure would make manipulation behaviors easier to validate and transfer across robots. We propose FlowHOI, a two-stage flow-matching framework that generates semantically grounded, temporally coherent HOI sequences, comprising hand poses, object poses, and hand-object contact states, conditioned on an egocentric observation, a language instruction, and a 3D Gaussian splatting (3DGS) scene reconstruction. We decouple geometry-centric grasping from semantics-centric manipulation, conditioning the latter on compact 3D scene tokens and employing a motion-text alignment loss to semantically ground the generated interactions in both the physical scene layout and the language instruction. To address the scarcity of high-fidelity HOI supervision, we introduce a reconstruction pipeline that recovers aligned hand-object trajectories and meshes from large-scale egocentric videos, yielding an HOI prior for robust generation. Across the GRAB and HOT3D benchmarks, FlowHOI achieves the highest action recognition accuracy and a 1.7$\times$ higher physics simulation success rate than the strongest diffusion-based baseline, while delivering a 40$\times$ inference speedup. We further demonstrate real-robot execution on four dexterous manipulation tasks, illustrating the feasibility of retargeting generated HOI representations to real-robot execution pipelines.
MonoTher-Depth: Enhancing Thermal Depth Estimation via Confidence-Aware Distillation
Apr 21, 2025Monocular depth estimation (MDE) from thermal images is a crucial technology for robotic systems operating in challenging conditions such as fog, smoke, and low light. The limited availability of labeled thermal data constrains the generalization capabilities of thermal MDE models compared to foundational RGB MDE models, which benefit from datasets of millions of images across diverse scenarios. To address this challenge, we introduce a novel pipeline that enhances thermal MDE through knowledge distillation from a versatile RGB MDE model. Our approach features a confidence-aware distillation method that utilizes the predicted confidence of the RGB MDE to selectively strengthen the thermal MDE model, capitalizing on the strengths of the RGB model while mitigating its weaknesses. Our method significantly improves the accuracy of the thermal MDE, independent of the availability of labeled depth supervision, and greatly expands its applicability to new scenarios. In our experiments on new scenarios without labeled depth, the proposed confidence-aware distillation method reduces the absolute relative error of thermal MDE by 22.88\% compared to the baseline without distillation.
* 8 Pages; The code will be available at https://github.com/ZuoJiaxing/monother_depth
L2COcc: Lightweight Camera-Centric Semantic Scene Completion via Distillation of LiDAR Model
Mar 16, 2025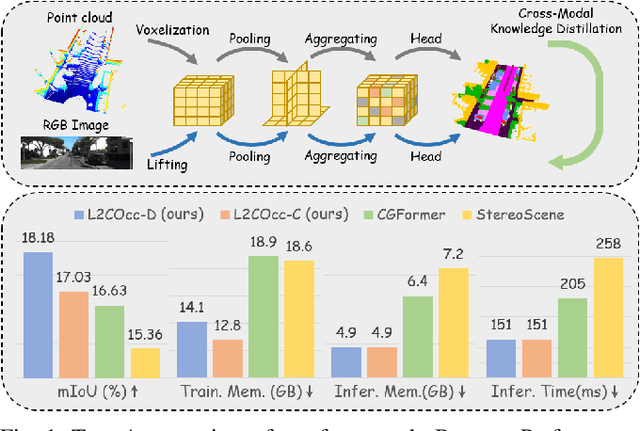
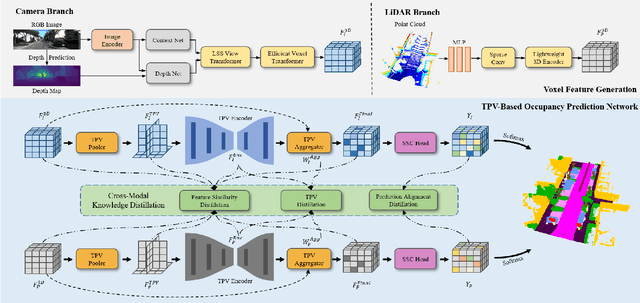
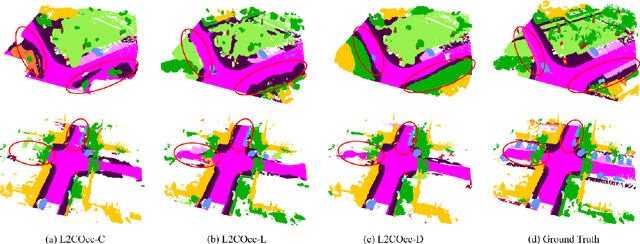
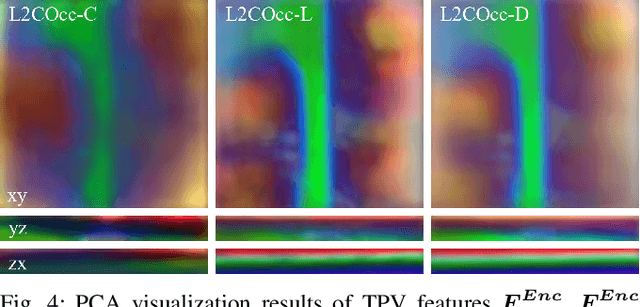
Semantic Scene Completion (SSC) constitutes a pivotal element in autonomous driving perception systems, tasked with inferring the 3D semantic occupancy of a scene from sensory data. To improve accuracy, prior research has implemented various computationally demanding and memory-intensive 3D operations, imposing significant computational requirements on the platform during training and testing. This paper proposes L2COcc, a lightweight camera-centric SSC framework that also accommodates LiDAR inputs. With our proposed efficient voxel transformer (EVT) and cross-modal knowledge modules, including feature similarity distillation (FSD), TPV distillation (TPVD) and prediction alignment distillation (PAD), our method substantially reduce computational burden while maintaining high accuracy. The experimental evaluations demonstrate that our proposed method surpasses the current state-of-the-art vision-based SSC methods regarding accuracy on both the SemanticKITTI and SSCBench-KITTI-360 benchmarks, respectively. Additionally, our method is more lightweight, exhibiting a reduction in both memory consumption and inference time by over 23% compared to the current state-of-the-arts method. Code is available at our project page:https://studyingfufu.github.io/L2COcc/.
PG-SLAM: Photo-realistic and Geometry-aware RGB-D SLAM in Dynamic Environments
Nov 24, 2024



Simultaneous localization and mapping (SLAM) has achieved impressive performance in static environments. However, SLAM in dynamic environments remains an open question. Many methods directly filter out dynamic objects, resulting in incomplete scene reconstruction and limited accuracy of camera localization. The other works express dynamic objects by point clouds, sparse joints, or coarse meshes, which fails to provide a photo-realistic representation. To overcome the above limitations, we propose a photo-realistic and geometry-aware RGB-D SLAM method by extending Gaussian splatting. Our method is composed of three main modules to 1) map the dynamic foreground including non-rigid humans and rigid items, 2) reconstruct the static background, and 3) localize the camera. To map the foreground, we focus on modeling the deformations and/or motions. We consider the shape priors of humans and exploit geometric and appearance constraints of humans and items. For background mapping, we design an optimization strategy between neighboring local maps by integrating appearance constraint into geometric alignment. As to camera localization, we leverage both static background and dynamic foreground to increase the observations for noise compensation. We explore the geometric and appearance constraints by associating 3D Gaussians with 2D optical flows and pixel patches. Experiments on various real-world datasets demonstrate that our method outperforms state-of-the-art approaches in terms of camera localization and scene representation. Source codes will be publicly available upon paper acceptance.
LiCROcc: Teach Radar for Accurate Semantic Occupancy Prediction using LiDAR and Camera
Jul 23, 2024



Semantic Scene Completion (SSC) is pivotal in autonomous driving perception, frequently confronted with the complexities of weather and illumination changes. The long-term strategy involves fusing multi-modal information to bolster the system's robustness. Radar, increasingly utilized for 3D target detection, is gradually replacing LiDAR in autonomous driving applications, offering a robust sensing alternative. In this paper, we focus on the potential of 3D radar in semantic scene completion, pioneering cross-modal refinement techniques for improved robustness against weather and illumination changes, and enhancing SSC performance.Regarding model architecture, we propose a three-stage tight fusion approach on BEV to realize a fusion framework for point clouds and images. Based on this foundation, we designed three cross-modal distillation modules-CMRD, BRD, and PDD. Our approach enhances the performance in both radar-only (R-LiCROcc) and radar-camera (RC-LiCROcc) settings by distilling to them the rich semantic and structural information of the fused features of LiDAR and camera. Finally, our LC-Fusion (teacher model), R-LiCROcc and RC-LiCROcc achieve the best performance on the nuScenes-Occupancy dataset, with mIOU exceeding the baseline by 22.9%, 44.1%, and 15.5%, respectively. The project page is available at https://hr-zju.github.io/LiCROcc/.
Gaussian-LIC: Photo-realistic LiDAR-Inertial-Camera SLAM with 3D Gaussian Splatting
Apr 10, 2024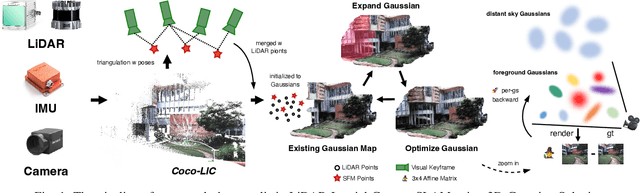
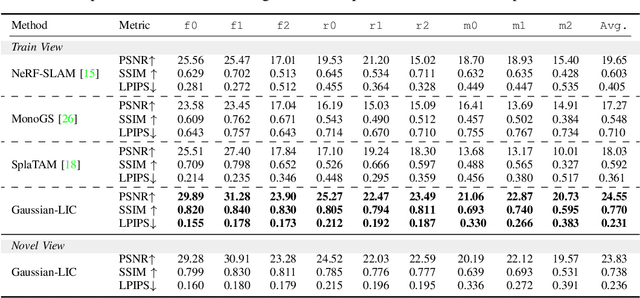
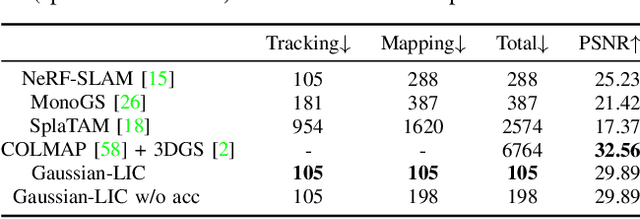

We present a real-time LiDAR-Inertial-Camera SLAM system with 3D Gaussian Splatting as the mapping backend. Leveraging robust pose estimates from our LiDAR-Inertial-Camera odometry, Coco-LIC, an incremental photo-realistic mapping system is proposed in this paper. We initialize 3D Gaussians from colorized LiDAR points and optimize them using differentiable rendering powered by 3D Gaussian Splatting. Meticulously designed strategies are employed to incrementally expand the Gaussian map and adaptively control its density, ensuring high-quality mapping with real-time capability. Experiments conducted in diverse scenarios demonstrate the superior performance of our method compared to existing radiance-field-based SLAM systems.
SC-Diff: 3D Shape Completion with Latent Diffusion Models
Mar 19, 2024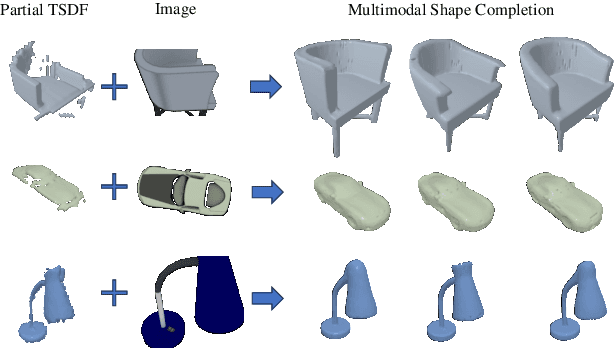
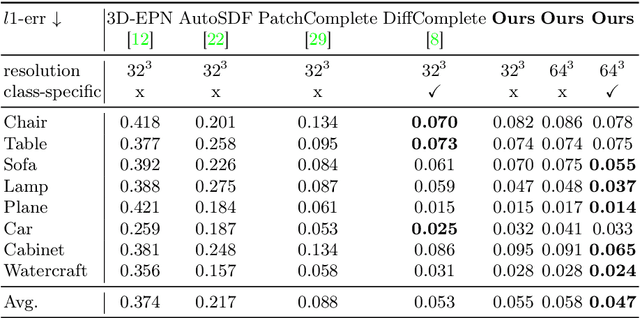
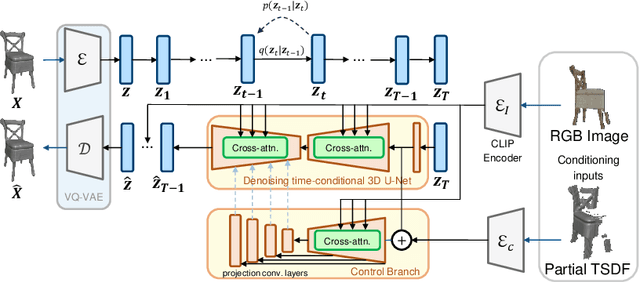
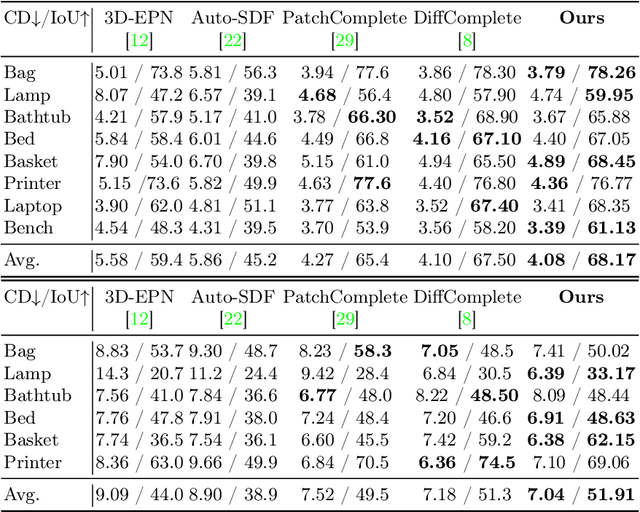
This paper introduces a 3D shape completion approach using a 3D latent diffusion model optimized for completing shapes, represented as Truncated Signed Distance Functions (TSDFs), from partial 3D scans. Our method combines image-based conditioning through cross-attention and spatial conditioning through the integration of 3D features from captured partial scans. This dual guidance enables high-fidelity, realistic shape completions at superior resolutions. At the core of our approach is the compression of 3D data into a low-dimensional latent space using an auto-encoder inspired by 2D latent diffusion models. This compression facilitates the processing of higher-resolution shapes and allows us to apply our model across multiple object classes, a significant improvement over other existing diffusion-based shape completion methods, which often require a separate diffusion model for each class. We validated our approach against two common benchmarks in the field of shape completion, demonstrating competitive performance in terms of accuracy and realism and performing on par with state-of-the-art methods despite operating at a higher resolution with a single model for all object classes. We present a comprehensive evaluation of our model, showcasing its efficacy in handling diverse shape completion challenges, even on unseen object classes. The code will be released upon acceptance.