 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMIF-AMIN: Adaptive Loss-Driven Multi-Scale Invertible Dense Network for Multimodal Medical Image Fusion
Aug 12, 2025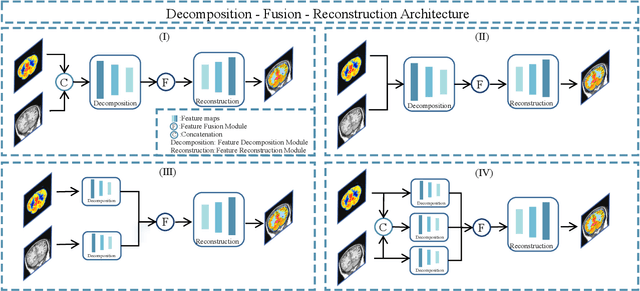
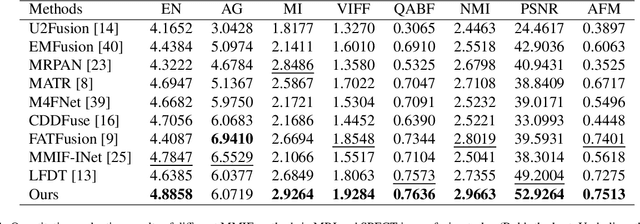
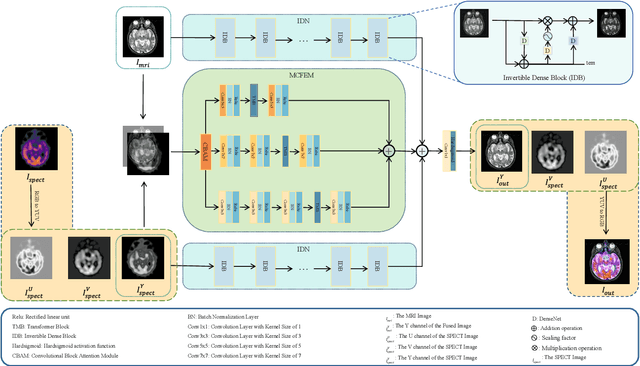
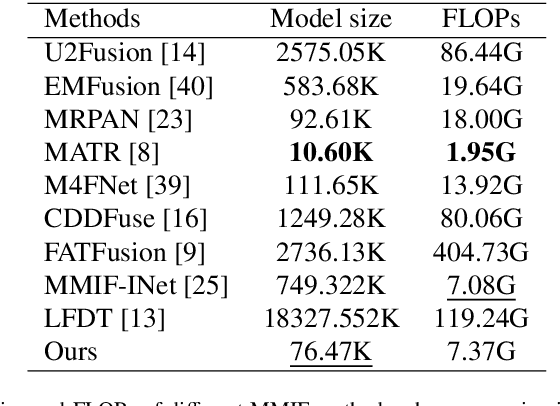
Multimodal medical image fusion (MMIF) aims to integrate images from different modalities to produce a comprehensive image that enhances medical diagnosis by accurately depicting organ structures, tissue textures, and metabolic information. Capturing both the unique and complementary information across multiple modalities simultaneously is a key research challenge in MMIF. To address this challenge, this paper proposes a novel image fusion method, MMIF-AMIN, which features a new architecture that can effectively extract these unique and complementary features. Specifically, an Invertible Dense Network (IDN) is employed for lossless feature extraction from individual modalities. To extract complementary information between modalities, a Multi-scale Complementary Feature Extraction Module (MCFEM) is designed, which incorporates a hybrid attention mechanism, convolutional layers of varying sizes, and Transformers. An adaptive loss function is introduced to guide model learning, addressing the limitations of traditional manually-designed loss functions and enhancing the depth of data mining. Extensive experiments demonstrate that MMIF-AMIN outperforms nine state-of-the-art MMIF methods, delivering superior results in both quantitative and qualitative analyses. Ablation experiments confirm the effectiveness of each component of the proposed method. Additionally, extending MMIF-AMIN to other image fusion tasks also achieves promising performance.
Corrections to "Computer Vision Aided mmWave Beam Alignment in V2X Communications"
Oct 08, 2024



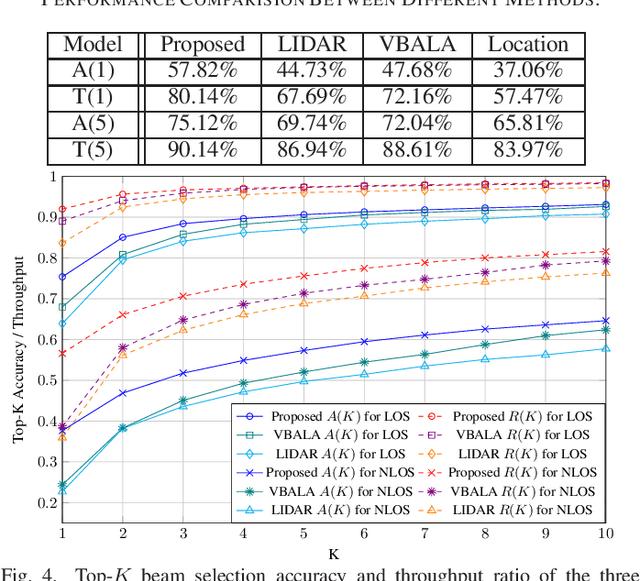
In this document, we revise the results of [1] based on more reasonable assumptions regarding data shuffling and parameter setup of deep neural networks (DNNs). Thus, the simulation results can now more reasonably demonstrate the performance of both the proposed and compared beam alignment methods. We revise the simulation steps and make moderate modifications to the design of the vehicle distribution feature (VDF) for the proposed vision based beam alignment when the MS location is available (VBALA). Specifically, we replace the 2D grids of the VDF with 3D grids and utilize the vehicle locations to expand the dimensions of the VDF. Then, we revise the simulation results of Fig. 11, Fig. 12, Fig. 13, Fig. 14, and Fig. 15 in [1] to reaffirm the validity of the conclusions.
LiCROcc: Teach Radar for Accurate Semantic Occupancy Prediction using LiDAR and Camera
Jul 23, 2024



Semantic Scene Completion (SSC) is pivotal in autonomous driving perception, frequently confronted with the complexities of weather and illumination changes. The long-term strategy involves fusing multi-modal information to bolster the system's robustness. Radar, increasingly utilized for 3D target detection, is gradually replacing LiDAR in autonomous driving applications, offering a robust sensing alternative. In this paper, we focus on the potential of 3D radar in semantic scene completion, pioneering cross-modal refinement techniques for improved robustness against weather and illumination changes, and enhancing SSC performance.Regarding model architecture, we propose a three-stage tight fusion approach on BEV to realize a fusion framework for point clouds and images. Based on this foundation, we designed three cross-modal distillation modules-CMRD, BRD, and PDD. Our approach enhances the performance in both radar-only (R-LiCROcc) and radar-camera (RC-LiCROcc) settings by distilling to them the rich semantic and structural information of the fused features of LiDAR and camera. Finally, our LC-Fusion (teacher model), R-LiCROcc and RC-LiCROcc achieve the best performance on the nuScenes-Occupancy dataset, with mIOU exceeding the baseline by 22.9%, 44.1%, and 15.5%, respectively. The project page is available at https://hr-zju.github.io/LiCROcc/.
Dynamic fault detection and diagnosis of industrial alkaline water electrolyzer process with variational Bayesian dictionary learning
Apr 15, 2024


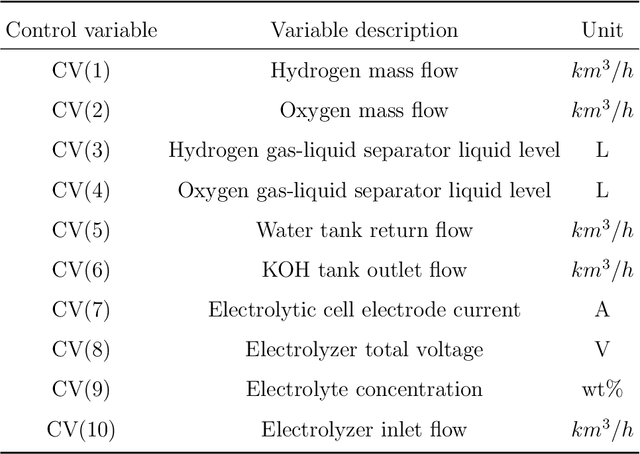
Alkaline Water Electrolysis (AWE) is one of the simplest green hydrogen production method using renewable energy. AWE system typically yields process variables that are serially correlated and contaminated by measurement uncertainty. A novel robust dynamic variational Bayesian dictionary learning (RDVDL) monitoring approach is proposed to improve the reliability and safety of AWE operation. RDVDL employs a sparse Bayesian dictionary learning to preserve the dynamic mechanism information of AWE process which allows the easy interpretation of fault detection results. To improve the robustness to measurement uncertainty, a low-rank vector autoregressive (VAR) method is derived to reliably extract the serial correlation from process variables. The effectiveness of the proposed approach is demonstrated with an industrial hydrogen production process, and RDVDL can efficiently detect and diagnose critical AWE faults.
Nonlinear sparse variational Bayesian learning based model predictive control with application to PEMFC temperature control
Apr 15, 2024The accuracy of the underlying model predictions is crucial for the success of model predictive control (MPC) applications. If the model is unable to accurately analyze the dynamics of the controlled system, the performance and stability guarantees provided by MPC may not be achieved. Learning-based MPC can learn models from data, improving the applicability and reliability of MPC. This study develops a nonlinear sparse variational Bayesian learning based MPC (NSVB-MPC) for nonlinear systems, where the model is learned by the developed NSVB method. Variational inference is used by NSVB-MPC to assess the predictive accuracy and make the necessary corrections to quantify system uncertainty. The suggested approach ensures input-to-state (ISS) and the feasibility of recursive constraints in accordance with the concept of an invariant terminal region. Finally, a PEMFC temperature control model experiment confirms the effectiveness of the NSVB-MPC method.
RIDERS: Radar-Infrared Depth Estimation for Robust Sensing
Feb 03, 2024Dense depth recovery is crucial in autonomous driving, serving as a foundational element for obstacle avoidance, 3D object detection, and local path planning. Adverse weather conditions, including haze, dust, rain, snow, and darkness, introduce significant challenges to accurate dense depth estimation, thereby posing substantial safety risks in autonomous driving. These challenges are particularly pronounced for traditional depth estimation methods that rely on short electromagnetic wave sensors, such as visible spectrum cameras and near-infrared LiDAR, due to their susceptibility to diffraction noise and occlusion in such environments. To fundamentally overcome this issue, we present a novel approach for robust metric depth estimation by fusing a millimeter-wave Radar and a monocular infrared thermal camera, which are capable of penetrating atmospheric particles and unaffected by lighting conditions. Our proposed Radar-Infrared fusion method achieves highly accurate and finely detailed dense depth estimation through three stages, including monocular depth prediction with global scale alignment, quasi-dense Radar augmentation by learning Radar-pixels correspondences, and local scale refinement of dense depth using a scale map learner. Our method achieves exceptional visual quality and accurate metric estimation by addressing the challenges of ambiguity and misalignment that arise from directly fusing multi-modal long-wave features. We evaluate the performance of our approach on the NTU4DRadLM dataset and our self-collected challenging ZJU-Multispectrum dataset. Especially noteworthy is the unprecedented robustness demonstrated by our proposed method in smoky scenarios. Our code will be released at \url{https://github.com/MMOCKING/RIDERS}.
Multi-User Matching and Resource Allocation in Vision Aided Communications
Apr 18, 2023Visual perception is an effective way to obtain the spatial characteristics of wireless channels and to reduce the overhead for communications system. A critical problem for the visual assistance is that the communications system needs to match the radio signal with the visual information of the corresponding user, i.e., to identify the visual user that corresponds to the target radio signal from all the environmental objects. In this paper, we propose a user matching method for environment with a variable number of objects. Specifically, we apply 3D detection to extract all the environmental objects from the images taken by multiple cameras. Then, we design a deep neural network (DNN) to estimate the location distribution of users by the images and beam pairs at multiple moments, and thereby identify the users from all the extracted environmental objects. Moreover, we present a resource allocation method based on the taken images to reduce the time and spectrum overhead compared to traditional resource allocation methods. Simulation results show that the proposed user matching method outperforms the existing methods, and the proposed resource allocation method can achieve $92\%$ transmission rate of the traditional resource allocation method but with the time and spectrum overhead significantly reduced.
Vision Aided Environment Semantics Extraction and Its Application in mmWave Beam Selection
Jan 21, 2023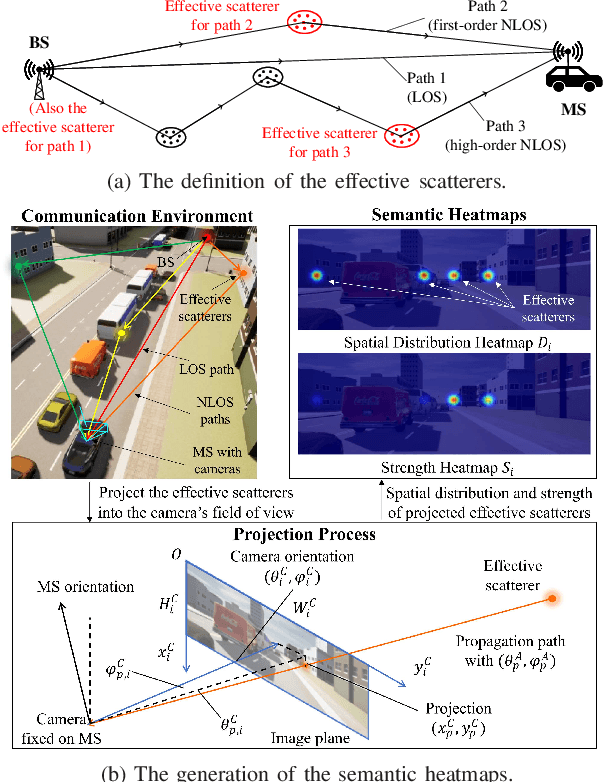
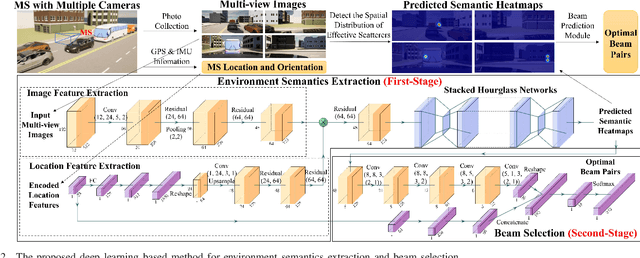
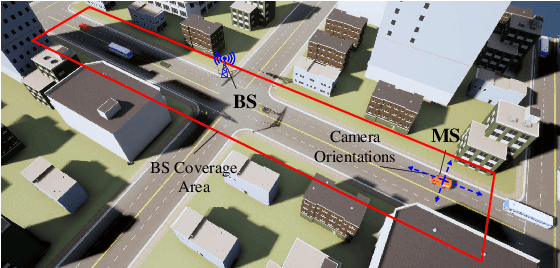
In this letter, we propose a novel mmWave beam selection method based on the environment semantics that are extracted from camera images taken at the user side. Specifically, we first define the environment semantics as the spatial distribution of the scatterers that affect the wireless propagation channels and utilize the keypoint detection technique to extract them from the input images. Then, we design a deep neural network with environment semantics as the input that can output the optimal beam pairs at UE and BS. Compared with the existing beam selection approaches that directly use images as the input, the proposed semantic-based method can explicitly obtain the environmental features that account for the propagation of wireless signals, and thus reduce the burden of storage and computation. Simulation results show that the proposed method can precisely estimate the location of the scatterers and outperform the existing image or LIDAR based works.
Vision-Aided Blockage Avoidance in UAV-assisted V2X Communications
Jul 26, 2022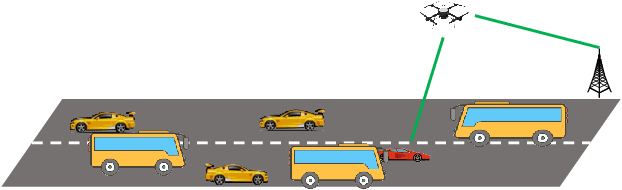
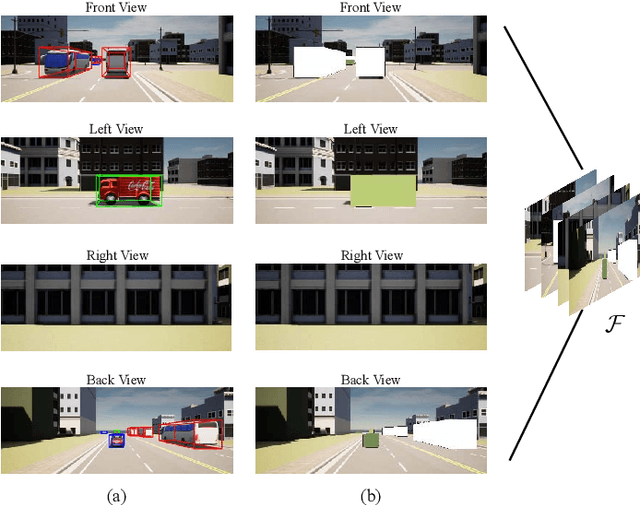
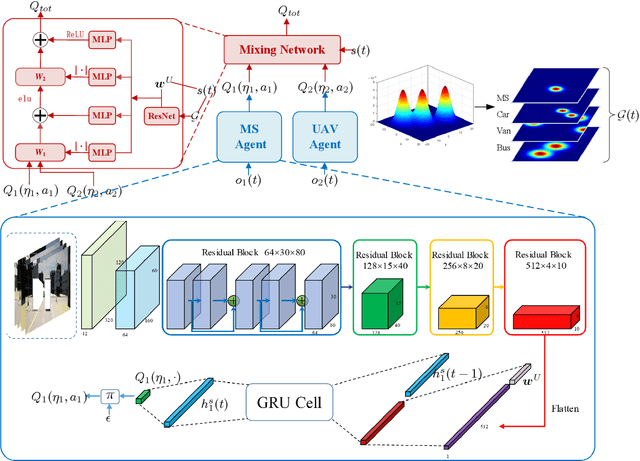
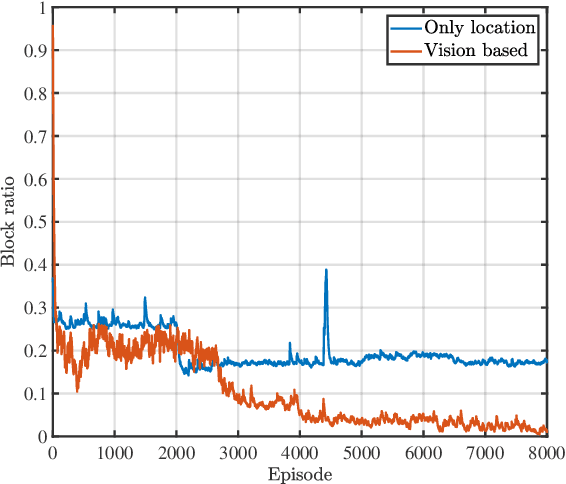
The blockage is a key challenge for millimeter wave communication systems, since these systems mainly work on line-of-sight (LOS) links, and the blockage can degrade the system performance significantly. It is recently found that visual information, easily obtained by cameras, can be utilized to extract the location and size information of the environmental objects, which can help to infer the communication parameters, such as blockage status. In this paper, we propose a novel vision-aided handover framework for UAV-assisted V2X system, which leverages the images taken by cameras at the mobile station (MS) to choose the direct link or UAV-assisted link to avoid blockage caused by the vehicles on the road. We propose a deep reinforcement learning algorithm to optimize the handover and UAV trajectory policy in order to improve the long-term throughput. Simulations results demonstrate the effectiveness of using visual information to deal with the blockage issues.
Computer Vision Aided mmWave Beam Alignment in V2X Communications
Jul 23, 2022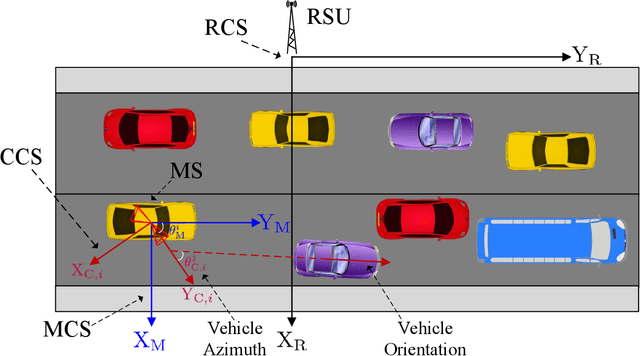

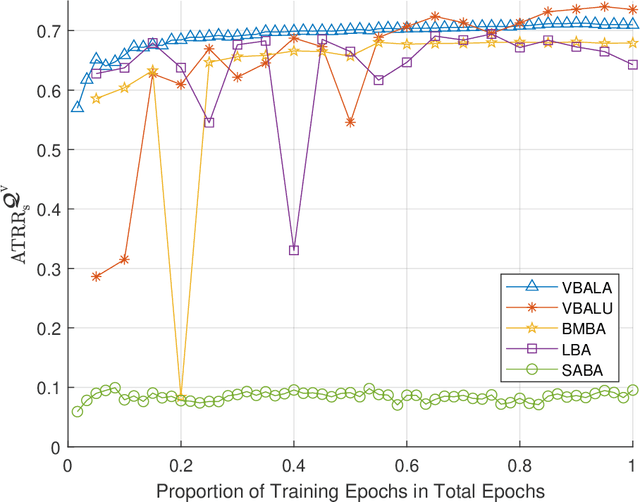

Visual information, captured for example by cameras, can effectively reflect the sizes and locations of the environmental scattering objects, and thereby can be used to infer communications parameters like propagation directions, receiver powers, as well as the blockage status. In this paper, we propose a novel beam alignment framework that leverages images taken by cameras installed at the mobile user. Specifically, we utilize 3D object detection techniques to extract the size and location information of the dynamic vehicles around the mobile user, and design a deep neural network (DNN) to infer the optimal beam pair for transceivers without any pilot signal overhead. Moreover, to avoid performing beam alignment too frequently or too slowly, a beam coherence time (BCT) prediction method is developed based on the vision information. This can effectively improve the transmission rate compared with the beam alignment approach with the fixed BCT. Simulation results show that the proposed vision based beam alignment methods outperform the existing LIDAR and vision based solutions, and demand for much lower hardware cost and communication overhead.