 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeam Squint Assisted User Localization in Near-Field Integrated Sensing and Communications Systems
Sep 25, 2023Integrated sensing and communication (ISAC) has been regarded as a key technology for 6G wireless communications, in which large-scale multiple input and multiple output (MIMO) array with higher and wider frequency bands will be adopted. However, recent studies show that the beam squint phenomenon can not be ignored in wideband MIMO system, which generally deteriorates the communications performance. In this paper, we find that with the aid of true-time-delay lines (TTDs), the range and trajectory of the beam squint in near-field communications systems can be freely controlled, and hence it is possible to reversely utilize the beam squint for user localization. We derive the trajectory equation for near-field beam squint points and design a way to control such trajectory. With the proposed design, beamforming from different subcarriers would purposely point to different angles and different distances, such that users from different positions would receive the maximum power at different subcarriers. Hence, one can simply localize multiple users from the beam squint effect in frequency domain, and thus reduce the beam sweeping overhead as compared to the conventional time domain beam search based approach. Furthermore, we utilize the phase difference of the maximum power subcarriers received by the user at different frequencies in several times beam sweeping to obtain a more accurate distance estimation result, ultimately realizing high accuracy and low beam sweeping overhead user localization. Simulation results demonstrate the effectiveness of the proposed schemes.
Hierarchical Codebook Design for Near-Field MmWave MIMO Communications Systems
Dec 15, 2022Communications system with analog or hybrid analog/digital architectures usually relies on a pre-defined codebook to perform beamforming. With the increase in the size of the antenna array, the characteristics of the spherical wavefront in the near-field situation are not negligible. Therefore, it is necessary to design a codebook that is adaptive to near-field scenarios. In this letter, we investigate the hierarchical codebook design method in the near-field situation. We develop a steering beam gain calculation method and design the lower-layer codebook to satisfy the coverage of the Fresnel region. For the upper-layer codebook, we propose beam rotation and beam relocation methods to place an arbitrary beam pattern at target locations. The simulation results show the superiority of the proposed near-field hierarchical codebook design.
Learning Heterogeneous Agent Cooperation via Multiagent League Training
Nov 13, 2022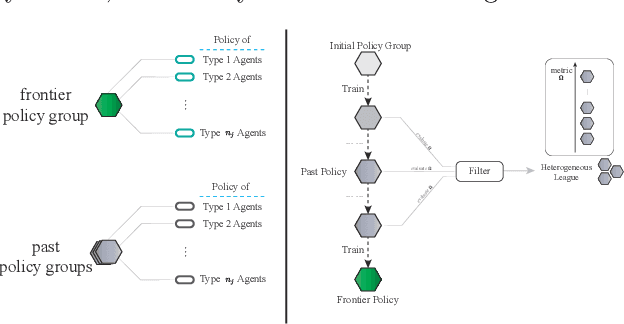
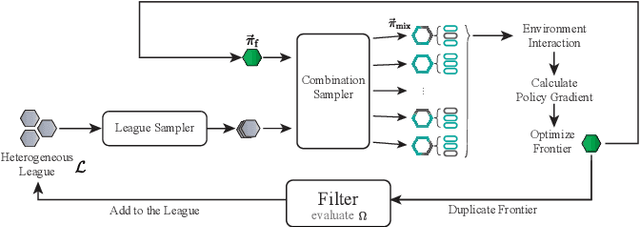
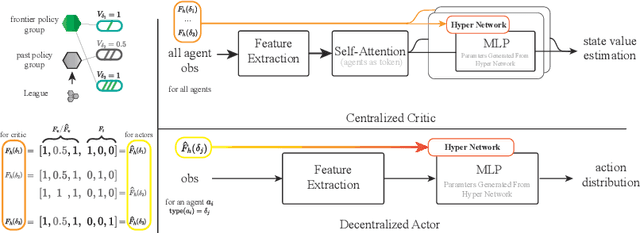
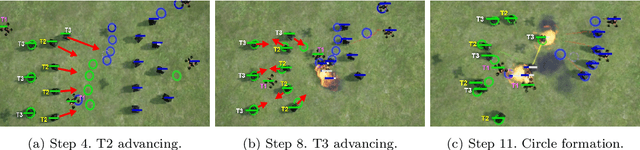
Many multiagent systems in the real world include multiple types of agents with different abilities and functionality. Such heterogeneous multiagent systems have significant practical advantages. However, they also come with challenges compared with homogeneous systems for multiagent reinforcement learning, such as the non-stationary problem and the policy version iteration issue. This work proposes a general-purpose reinforcement learning algorithm named as Heterogeneous League Training (HLT) to address heterogeneous multiagent problems. HLT keeps track of a pool of policies that agents have explored during training, gathering a league of heterogeneous policies to facilitate future policy optimization. Moreover, a hyper-network is introduced to increase the diversity of agent behaviors when collaborating with teammates having different levels of cooperation skills. We use heterogeneous benchmark tasks to demonstrate that (1) HLT promotes the success rate in cooperative heterogeneous tasks; (2) HLT is an effective approach to solving the policy version iteration problem; (3) HLT provides a practical way to assess the difficulty of learning each role in a heterogeneous team.
Solving the Diffusion of Responsibility Problem in Multiagent Reinforcement Learning with a Policy Resonance Approach
Aug 19, 2022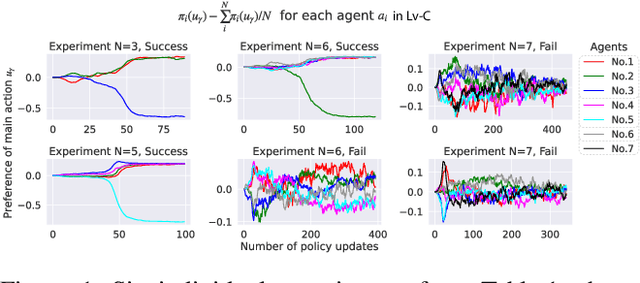
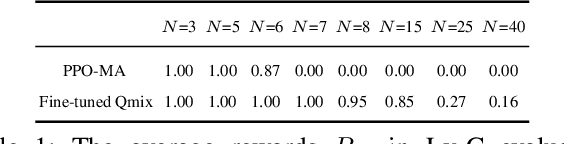
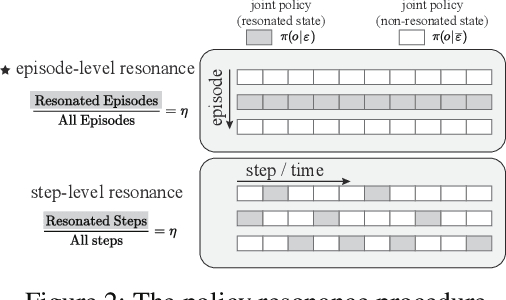
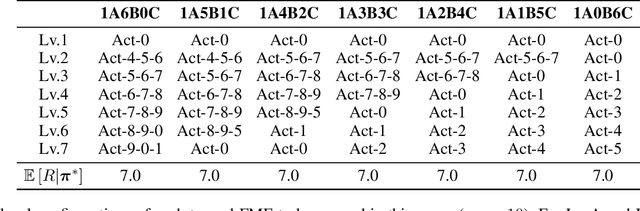
SOTA multiagent reinforcement algorithms distinguish themselves in many ways from their single-agent equivalences, except that they still totally inherit the single-agent exploration-exploitation strategy. We report that naively inheriting this strategy from single-agent algorithms causes potential collaboration failures, in which the agents blindly follow mainstream behaviors and reject taking minority responsibility. We named this problem the diffusion of responsibility (DR) as it shares similarities with a same-name social psychology effect. In this work, we start by theoretically analyzing the cause of the DR problem, emphasizing it is not relevant to the reward crafting or the credit assignment problems. We propose a Policy Resonance approach to address the DR problem by modifying the multiagent exploration-exploitation strategy. Next, we show that most SOTA algorithms can equip this approach to promote collaborative agent performance in complex cooperative tasks. Experiments are performed in multiple test benchmark tasks to illustrate the effectiveness of this approach.
A Cooperation Graph Approach for Multiagent Sparse Reward Reinforcement Learning
Aug 05, 2022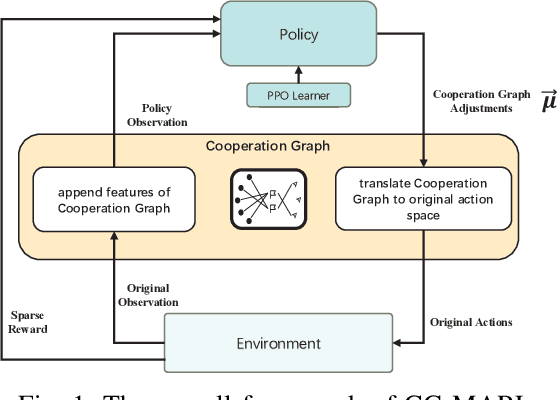
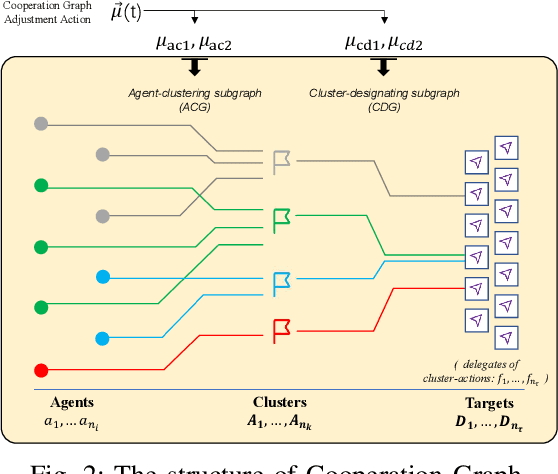
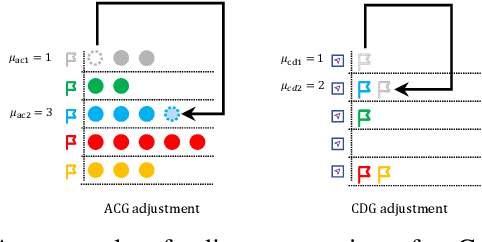
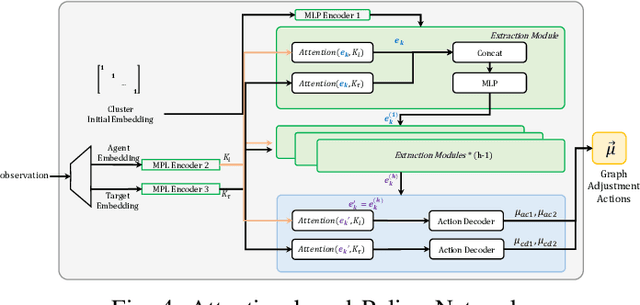
Multiagent reinforcement learning (MARL) can solve complex cooperative tasks. However, the efficiency of existing MARL methods relies heavily on well-defined reward functions. Multiagent tasks with sparse reward feedback are especially challenging not only because of the credit distribution problem, but also due to the low probability of obtaining positive reward feedback. In this paper, we design a graph network called Cooperation Graph (CG). The Cooperation Graph is the combination of two simple bipartite graphs, namely, the Agent Clustering subgraph (ACG) and the Cluster Designating subgraph (CDG). Next, based on this novel graph structure, we propose a Cooperation Graph Multiagent Reinforcement Learning (CG-MARL) algorithm, which can efficiently deal with the sparse reward problem in multiagent tasks. In CG-MARL, agents are directly controlled by the Cooperation Graph. And a policy neural network is trained to manipulate this Cooperation Graph, guiding agents to achieve cooperation in an implicit way. This hierarchical feature of CG-MARL provides space for customized cluster-actions, an extensible interface for introducing fundamental cooperation knowledge. In experiments, CG-MARL shows state-of-the-art performance in sparse reward multiagent benchmarks, including the anti-invasion interception task and the multi-cargo delivery task.
Vision-Aided Blockage Avoidance in UAV-assisted V2X Communications
Jul 26, 2022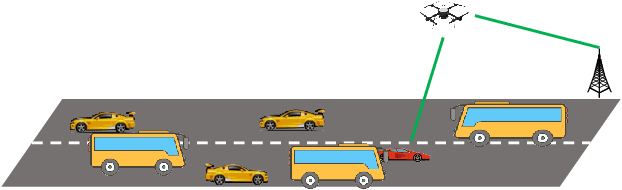
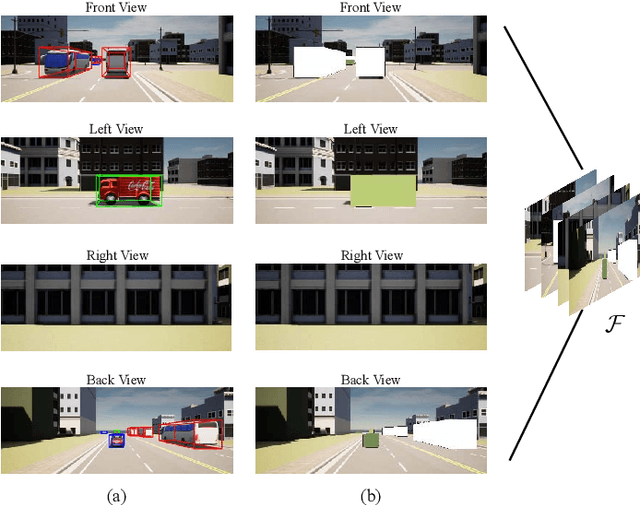
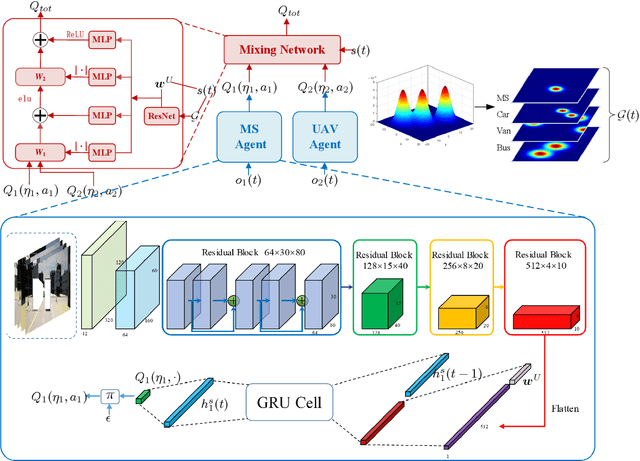
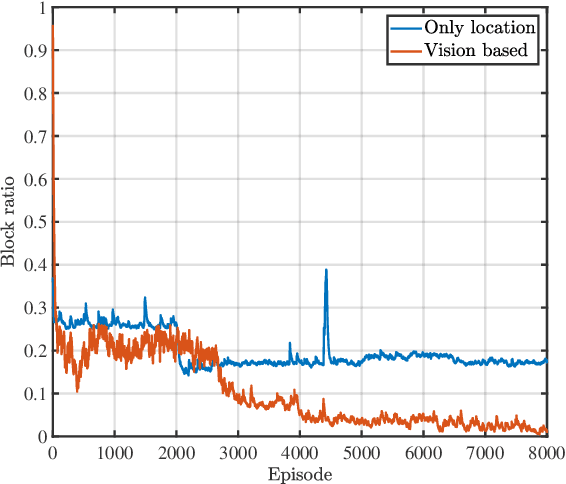
The blockage is a key challenge for millimeter wave communication systems, since these systems mainly work on line-of-sight (LOS) links, and the blockage can degrade the system performance significantly. It is recently found that visual information, easily obtained by cameras, can be utilized to extract the location and size information of the environmental objects, which can help to infer the communication parameters, such as blockage status. In this paper, we propose a novel vision-aided handover framework for UAV-assisted V2X system, which leverages the images taken by cameras at the mobile station (MS) to choose the direct link or UAV-assisted link to avoid blockage caused by the vehicles on the road. We propose a deep reinforcement learning algorithm to optimize the handover and UAV trajectory policy in order to improve the long-term throughput. Simulations results demonstrate the effectiveness of using visual information to deal with the blockage issues.