 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentJet: A Flexible Swarm Training Framework for Agentic Reinforcement Learning
Jun 03, 2026We present AgentJet, a distributed swarm training framework for large language model (LLM) agent reinforcement learning. Unlike centralized frameworks that tightly couple agent rollouts with model optimization, AgentJet adopts a decoupled multi-node architecture in which swarm server nodes host trainable models and run optimization on GPU clusters, whereas swarm client nodes execute arbitrary agents on arbitrary devices. This design provides capabilities that are difficult to support in centralized frameworks: (1) heterogeneous multi-model reinforcement learning, enabling the training of heterogeneous multi-agent teams with multiple LLM as brains; (2) multi-task cocktail training with isolated agent runtimes; (3) fault-tolerant execution that prevents external environment failures from interrupting the training process; and (4) live code iteration, which allows agents to be edited during training by replacing swarm client nodes. To support efficient RL in multi-model, multi-turn, and multi-agent settings, AgentJet introduces a context tracking module with timeline merging, which consolidates redundant context and achieves a 1.5-10x training speedup. Finally, AgentJet introduces an automated research system that takes a research topic as input and autonomously conducts long-horizon, multi-day RL studies on large-scale clusters. By leveraging the swarm architecture, this system reproduces key exploratory workflows of RL researchers without human intervention during execution.
SeeUPO: Sequence-Level Agentic-RL with Convergence Guarantees
Feb 06, 2026Reinforcement learning (RL) has emerged as the predominant paradigm for training large language model (LLM)-based AI agents. However, existing backbone RL algorithms lack verified convergence guarantees in agentic scenarios, especially in multi-turn settings, which can lead to training instability and failure to converge to optimal policies. In this paper, we systematically analyze how different combinations of policy update mechanisms and advantage estimation methods affect convergence properties in single/multi-turn scenarios. We find that REINFORCE with Group Relative Advantage Estimation (GRAE) can converge to the globally optimal under undiscounted conditions, but the combination of PPO & GRAE breaks PPO's original monotonic improvement property. Furthermore, we demonstrate that mainstream backbone RL algorithms cannot simultaneously achieve both critic-free and convergence guarantees in multi-turn scenarios. To address this, we propose SeeUPO (Sequence-level Sequential Update Policy Optimization), a critic-free approach with convergence guarantees for multi-turn interactions. SeeUPO models multi-turn interaction as sequentially executed multi-agent bandit problems. Through turn-by-turn sequential policy updates in reverse execution order, it ensures monotonic improvement and convergence to global optimal solution via backward induction. Experiments on AppWorld and BFCL v4 demonstrate SeeUPO's substantial improvements over existing backbone algorithms: relative gains of 43.3%-54.6% on Qwen3-14B and 24.1%-41.9% on Qwen2.5-14B (averaged across benchmarks), along with superior training stability.
AgentEvolver: Towards Efficient Self-Evolving Agent System
Nov 13, 2025Autonomous agents powered by large language models (LLMs) have the potential to significantly enhance human productivity by reasoning, using tools, and executing complex tasks in diverse environments. However, current approaches to developing such agents remain costly and inefficient, as they typically require manually constructed task datasets and reinforcement learning (RL) pipelines with extensive random exploration. These limitations lead to prohibitively high data-construction costs, low exploration efficiency, and poor sample utilization. To address these challenges, we present AgentEvolver, a self-evolving agent system that leverages the semantic understanding and reasoning capabilities of LLMs to drive autonomous agent learning. AgentEvolver introduces three synergistic mechanisms: (i) self-questioning, which enables curiosity-driven task generation in novel environments, reducing dependence on handcrafted datasets; (ii) self-navigating, which improves exploration efficiency through experience reuse and hybrid policy guidance; and (iii) self-attributing, which enhances sample efficiency by assigning differentiated rewards to trajectory states and actions based on their contribution. By integrating these mechanisms into a unified framework, AgentEvolver enables scalable, cost-effective, and continual improvement of agent capabilities. Preliminary experiments indicate that AgentEvolver achieves more efficient exploration, better sample utilization, and faster adaptation compared to traditional RL-based baselines.
Unreal-MAP: Unreal-Engine-Based General Platform for Multi-Agent Reinforcement Learning
Mar 20, 2025In this paper, we propose Unreal Multi-Agent Playground (Unreal-MAP), an MARL general platform based on the Unreal-Engine (UE). Unreal-MAP allows users to freely create multi-agent tasks using the vast visual and physical resources available in the UE community, and deploy state-of-the-art (SOTA) MARL algorithms within them. Unreal-MAP is user-friendly in terms of deployment, modification, and visualization, and all its components are open-source. We also develop an experimental framework compatible with algorithms ranging from rule-based to learning-based provided by third-party frameworks. Lastly, we deploy several SOTA algorithms in example tasks developed via Unreal-MAP, and conduct corresponding experimental analyses. We believe Unreal-MAP can play an important role in the MARL field by closely integrating existing algorithms with user-customized tasks, thus advancing the field of MARL.
Prioritized League Reinforcement Learning for Large-Scale Heterogeneous Multiagent Systems
Mar 26, 2024Large-scale heterogeneous multiagent systems feature various realistic factors in the real world, such as agents with diverse abilities and overall system cost. In comparison to homogeneous systems, heterogeneous systems offer significant practical advantages. Nonetheless, they also present challenges for multiagent reinforcement learning, including addressing the non-stationary problem and managing an imbalanced number of agents with different types. We propose a Prioritized Heterogeneous League Reinforcement Learning (PHLRL) method to address large-scale heterogeneous cooperation problems. PHLRL maintains a record of various policies that agents have explored during their training and establishes a heterogeneous league consisting of diverse policies to aid in future policy optimization. Furthermore, we design a prioritized policy gradient approach to compensate for the gap caused by differences in the number of different types of agents. Next, we use Unreal Engine to design a large-scale heterogeneous cooperation benchmark named Large-Scale Multiagent Operation (LSMO), which is a complex two-team competition scenario that requires collaboration from both ground and airborne agents. We use experiments to show that PHLRL outperforms state-of-the-art methods, including QTRAN and QPLEX in LSMO.
Self-Clustering Hierarchical Multi-Agent Reinforcement Learning with Extensible Cooperation Graph
Mar 26, 2024



Multi-Agent Reinforcement Learning (MARL) has been successful in solving many cooperative challenges. However, classic non-hierarchical MARL algorithms still cannot address various complex multi-agent problems that require hierarchical cooperative behaviors. The cooperative knowledge and policies learned in non-hierarchical algorithms are implicit and not interpretable, thereby restricting the integration of existing knowledge. This paper proposes a novel hierarchical MARL model called Hierarchical Cooperation Graph Learning (HCGL) for solving general multi-agent problems. HCGL has three components: a dynamic Extensible Cooperation Graph (ECG) for achieving self-clustering cooperation; a group of graph operators for adjusting the topology of ECG; and an MARL optimizer for training these graph operators. HCGL's key distinction from other MARL models is that the behaviors of agents are guided by the topology of ECG instead of policy neural networks. ECG is a three-layer graph consisting of an agent node layer, a cluster node layer, and a target node layer. To manipulate the ECG topology in response to changing environmental conditions, four graph operators are trained to adjust the edge connections of ECG dynamically. The hierarchical feature of ECG provides a unique approach to merge primitive actions (actions executed by the agents) and cooperative actions (actions executed by the clusters) into a unified action space, allowing us to integrate fundamental cooperative knowledge into an extensible interface. In our experiments, the HCGL model has shown outstanding performance in multi-agent benchmarks with sparse rewards. We also verify that HCGL can easily be transferred to large-scale scenarios with high zero-shot transfer success rates.
Learning Heterogeneous Agent Cooperation via Multiagent League Training
Nov 13, 2022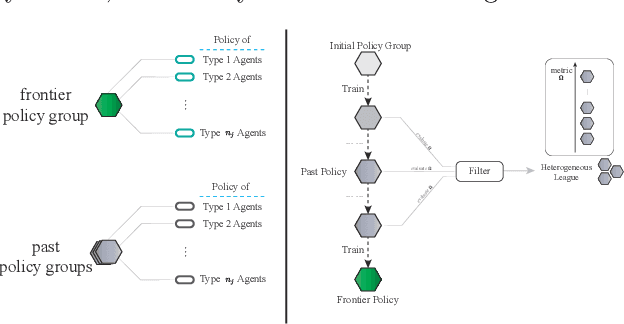
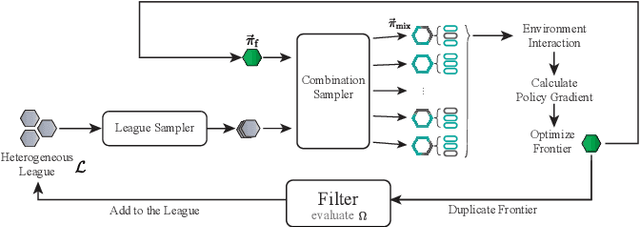
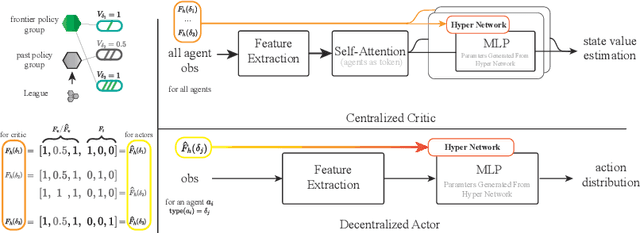
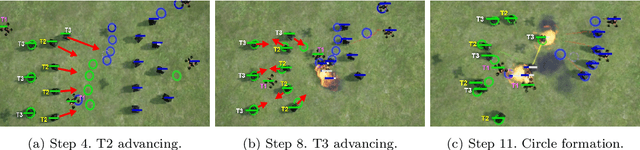
Many multiagent systems in the real world include multiple types of agents with different abilities and functionality. Such heterogeneous multiagent systems have significant practical advantages. However, they also come with challenges compared with homogeneous systems for multiagent reinforcement learning, such as the non-stationary problem and the policy version iteration issue. This work proposes a general-purpose reinforcement learning algorithm named as Heterogeneous League Training (HLT) to address heterogeneous multiagent problems. HLT keeps track of a pool of policies that agents have explored during training, gathering a league of heterogeneous policies to facilitate future policy optimization. Moreover, a hyper-network is introduced to increase the diversity of agent behaviors when collaborating with teammates having different levels of cooperation skills. We use heterogeneous benchmark tasks to demonstrate that (1) HLT promotes the success rate in cooperative heterogeneous tasks; (2) HLT is an effective approach to solving the policy version iteration problem; (3) HLT provides a practical way to assess the difficulty of learning each role in a heterogeneous team.
Solving the Diffusion of Responsibility Problem in Multiagent Reinforcement Learning with a Policy Resonance Approach
Aug 19, 2022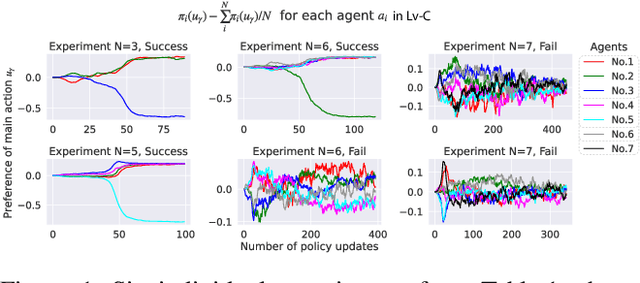
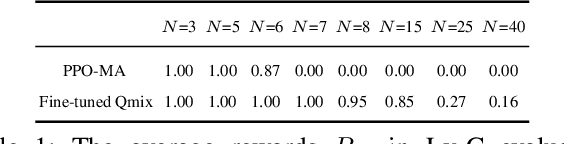
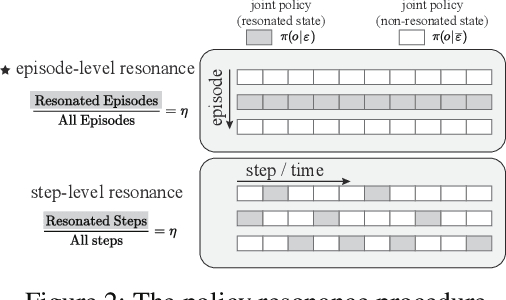
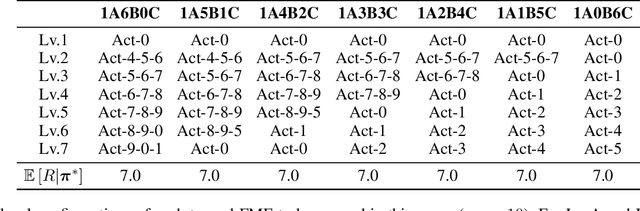
SOTA multiagent reinforcement algorithms distinguish themselves in many ways from their single-agent equivalences, except that they still totally inherit the single-agent exploration-exploitation strategy. We report that naively inheriting this strategy from single-agent algorithms causes potential collaboration failures, in which the agents blindly follow mainstream behaviors and reject taking minority responsibility. We named this problem the diffusion of responsibility (DR) as it shares similarities with a same-name social psychology effect. In this work, we start by theoretically analyzing the cause of the DR problem, emphasizing it is not relevant to the reward crafting or the credit assignment problems. We propose a Policy Resonance approach to address the DR problem by modifying the multiagent exploration-exploitation strategy. Next, we show that most SOTA algorithms can equip this approach to promote collaborative agent performance in complex cooperative tasks. Experiments are performed in multiple test benchmark tasks to illustrate the effectiveness of this approach.
A Cooperation Graph Approach for Multiagent Sparse Reward Reinforcement Learning
Aug 05, 2022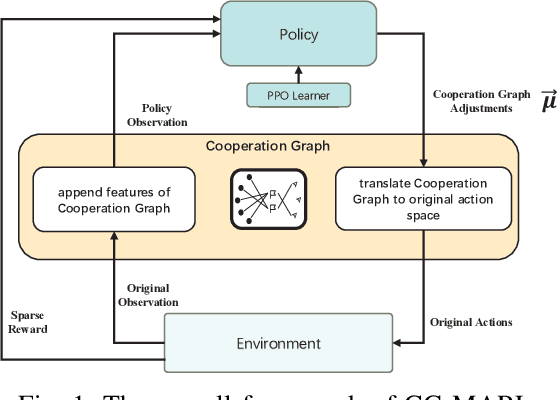
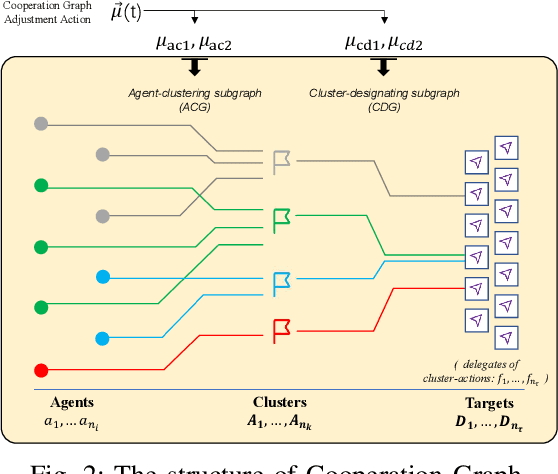
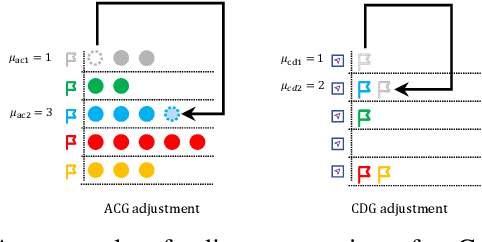
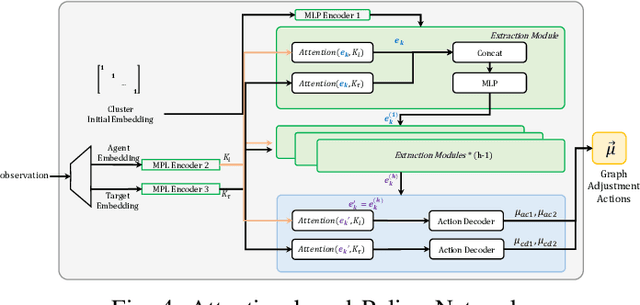
Multiagent reinforcement learning (MARL) can solve complex cooperative tasks. However, the efficiency of existing MARL methods relies heavily on well-defined reward functions. Multiagent tasks with sparse reward feedback are especially challenging not only because of the credit distribution problem, but also due to the low probability of obtaining positive reward feedback. In this paper, we design a graph network called Cooperation Graph (CG). The Cooperation Graph is the combination of two simple bipartite graphs, namely, the Agent Clustering subgraph (ACG) and the Cluster Designating subgraph (CDG). Next, based on this novel graph structure, we propose a Cooperation Graph Multiagent Reinforcement Learning (CG-MARL) algorithm, which can efficiently deal with the sparse reward problem in multiagent tasks. In CG-MARL, agents are directly controlled by the Cooperation Graph. And a policy neural network is trained to manipulate this Cooperation Graph, guiding agents to achieve cooperation in an implicit way. This hierarchical feature of CG-MARL provides space for customized cluster-actions, an extensible interface for introducing fundamental cooperation knowledge. In experiments, CG-MARL shows state-of-the-art performance in sparse reward multiagent benchmarks, including the anti-invasion interception task and the multi-cargo delivery task.
Concentration Network for Reinforcement Learning of Large-Scale Multi-Agent Systems
Apr 07, 2022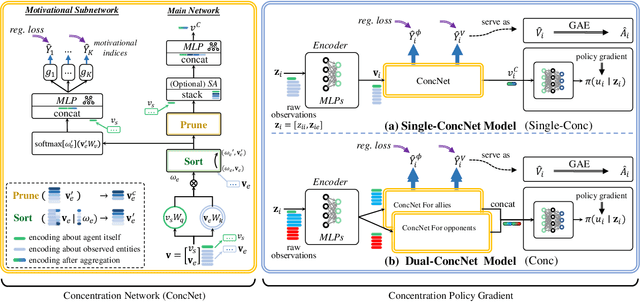
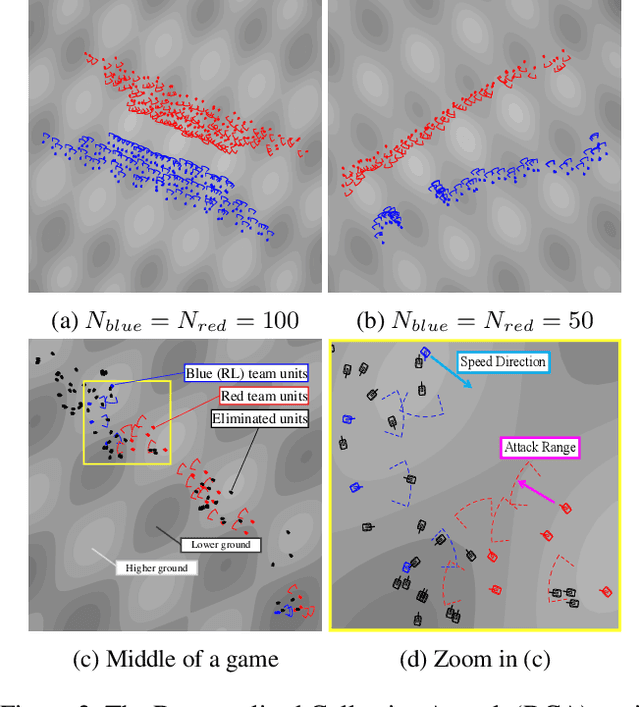

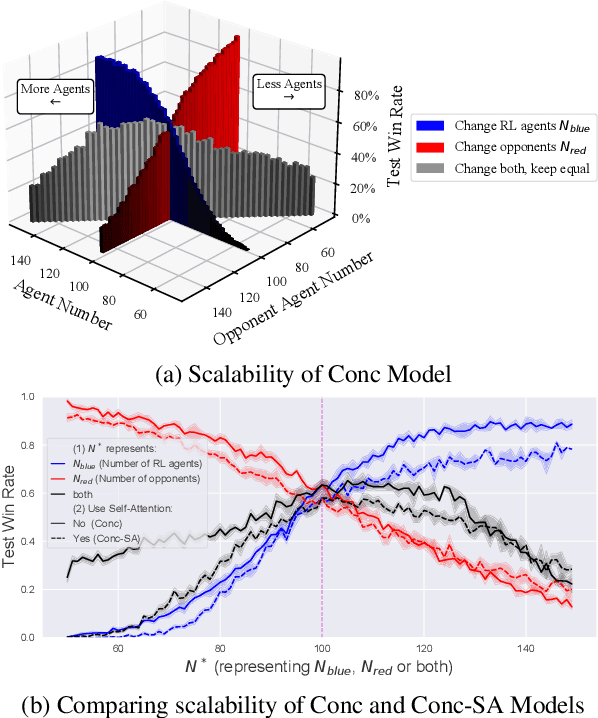
When dealing with a series of imminent issues, humans can naturally concentrate on a subset of these concerning issues by prioritizing them according to their contributions to motivational indices, e.g., the probability of winning a game. This idea of concentration offers insights into reinforcement learning of sophisticated Large-scale Multi-Agent Systems (LMAS) participated by hundreds of agents. In such an LMAS, each agent receives a long series of entity observations at each step, which can overwhelm existing aggregation networks such as graph attention networks and cause inefficiency. In this paper, we propose a concentration network called ConcNet. First, ConcNet scores the observed entities considering several motivational indices, e.g., expected survival time and state value of the agents, and then ranks, prunes, and aggregates the encodings of observed entities to extract features. Second, distinct from the well-known attention mechanism, ConcNet has a unique motivational subnetwork to explicitly consider the motivational indices when scoring the observed entities. Furthermore, we present a concentration policy gradient architecture that can learn effective policies in LMAS from scratch. Extensive experiments demonstrate that the presented architecture has excellent scalability and flexibility, and significantly outperforms existing methods on LMAS benchmarks.