 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHASM: Unveiling Covert Advertisements on Chinese Social Media
Apr 22, 2026Current benchmarks for evaluating large language models (LLMs) in social media moderation completely overlook a serious threat: covert advertisements, which disguise themselves as regular posts to deceive and mislead consumers into making purchases, leading to significant ethical and legal concerns. In this paper, we present the CHASM, a first-of-its-kind dataset designed to evaluate the capability of Multimodal Large Language Models (MLLMs) in detecting covert advertisements on social media. CHASM is a high-quality, anonymized, manually curated dataset consisting of 4,992 instances, based on real-world scenarios from the Chinese social media platform Rednote. The dataset was collected and annotated under strict privacy protection and quality control protocols. It includes many product experience sharing posts that closely resemble covert advertisements, making the dataset particularly challenging.The results show that under both zero-shot and in-context learning settings, none of the current MLLMs are sufficiently reliable for detecting covert advertisements.Our further experiments revealed that fine-tuning open-source MLLMs on our dataset yielded noticeable performance gains. However, significant challenges persist, such as detecting subtle cues in comments and differences in visual and textual structures.We provide in-depth error analysis and outline future research directions. We hope our study can serve as a call for the research community and platform moderators to develop more precise defenses against this emerging threat.
SeeUPO: Sequence-Level Agentic-RL with Convergence Guarantees
Feb 06, 2026Reinforcement learning (RL) has emerged as the predominant paradigm for training large language model (LLM)-based AI agents. However, existing backbone RL algorithms lack verified convergence guarantees in agentic scenarios, especially in multi-turn settings, which can lead to training instability and failure to converge to optimal policies. In this paper, we systematically analyze how different combinations of policy update mechanisms and advantage estimation methods affect convergence properties in single/multi-turn scenarios. We find that REINFORCE with Group Relative Advantage Estimation (GRAE) can converge to the globally optimal under undiscounted conditions, but the combination of PPO & GRAE breaks PPO's original monotonic improvement property. Furthermore, we demonstrate that mainstream backbone RL algorithms cannot simultaneously achieve both critic-free and convergence guarantees in multi-turn scenarios. To address this, we propose SeeUPO (Sequence-level Sequential Update Policy Optimization), a critic-free approach with convergence guarantees for multi-turn interactions. SeeUPO models multi-turn interaction as sequentially executed multi-agent bandit problems. Through turn-by-turn sequential policy updates in reverse execution order, it ensures monotonic improvement and convergence to global optimal solution via backward induction. Experiments on AppWorld and BFCL v4 demonstrate SeeUPO's substantial improvements over existing backbone algorithms: relative gains of 43.3%-54.6% on Qwen3-14B and 24.1%-41.9% on Qwen2.5-14B (averaged across benchmarks), along with superior training stability.
DIVERGE: Diversity-Enhanced RAG for Open-Ended Information Seeking
Jan 30, 2026Existing retrieval-augmented generation (RAG) systems are primarily designed under the assumption that each query has a single correct answer. This overlooks common information-seeking scenarios with multiple plausible answers, where diversity is essential to avoid collapsing to a single dominant response, thereby constraining creativity and compromising fair and inclusive information access. Our analysis reveals a commonly overlooked limitation of standard RAG systems: they underutilize retrieved context diversity, such that increasing retrieval diversity alone does not yield diverse generations. To address this limitation, we propose DIVERGE, a plug-and-play agentic RAG framework with novel reflection-guided generation and memory-augmented iterative refinement, which promotes diverse viewpoints while preserving answer quality. We introduce novel metrics tailored to evaluating the diversity-quality trade-off in open-ended questions, and show that they correlate well with human judgments. We demonstrate that DIVERGE achieves the best diversity-quality trade-off compared to competitive baselines and previous state-of-the-art methods on the real-world Infinity-Chat dataset, substantially improving diversity while maintaining quality. More broadly, our results reveal a systematic limitation of current LLM-based systems for open-ended information-seeking and show that explicitly modeling diversity can mitigate it. Our code is available at: https://github.com/au-clan/Diverge
Less Noise, More Voice: Reinforcement Learning for Reasoning via Instruction Purification
Jan 29, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has advanced LLM reasoning, but remains constrained by inefficient exploration under limited rollout budgets, leading to low sampling success and unstable training in complex tasks. We find that many exploration failures arise not from problem difficulty, but from a small number of prompt tokens that introduce interference. Building on this insight, we propose the Less Noise Sampling Framework (LENS), which first prompts by identifying and removing interference tokens. then transfers successful rollouts from the purification process to supervise policy optimization on the original noisy prompts, enabling the model to learn to ignore interference in the real-world, noisy prompting settings. Experimental results show that LENS significantly outperforms GRPO, delivering higher performance and faster convergence, with a 3.88% average gain and over 1.6$\times$ speedup. Our work highlights the critical role of pruning interference tokens in improving rollout efficiency, offering a new perspective for RLVR research.
JADE: Bridging the Strategic-Operational Gap in Dynamic Agentic RAG
Jan 29, 2026The evolution of Retrieval-Augmented Generation (RAG) has shifted from static retrieval pipelines to dynamic, agentic workflows where a central planner orchestrates multi-turn reasoning. However, existing paradigms face a critical dichotomy: they either optimize modules jointly within rigid, fixed-graph architectures, or empower dynamic planning while treating executors as frozen, black-box tools. We identify that this \textit{decoupled optimization} creates a ``strategic-operational mismatch,'' where sophisticated planning strategies fail to materialize due to unadapted local executors, often leading to negative performance gains despite increased system complexity. In this paper, we propose \textbf{JADE} (\textbf{J}oint \textbf{A}gentic \textbf{D}ynamic \textbf{E}xecution), a unified framework for the joint optimization of planning and execution within dynamic, multi-turn workflows. By modeling the system as a cooperative multi-agent team unified under a single shared backbone, JADE enables end-to-end learning driven by outcome-based rewards. This approach facilitates \textit{co-adaptation}: the planner learns to operate within the capability boundaries of the executors, while the executors evolve to align with high-level strategic intent. Empirical results demonstrate that JADE transforms disjoint modules into a synergistic system, yielding remarkable performance improvements via joint optimization and enabling a flexible balance between efficiency and effectiveness through dynamic workflow orchestration.
Heterogeneity in Multi-Agent Reinforcement Learning
Dec 28, 2025Heterogeneity is a fundamental property in multi-agent reinforcement learning (MARL), which is closely related not only to the functional differences of agents, but also to policy diversity and environmental interactions. However, the MARL field currently lacks a rigorous definition and deeper understanding of heterogeneity. This paper systematically discusses heterogeneity in MARL from the perspectives of definition, quantification, and utilization. First, based on an agent-level modeling of MARL, we categorize heterogeneity into five types and provide mathematical definitions. Second, we define the concept of heterogeneity distance and propose a practical quantification method. Third, we design a heterogeneity-based multi-agent dynamic parameter sharing algorithm as an example of the application of our methodology. Case studies demonstrate that our method can effectively identify and quantify various types of agent heterogeneity. Experimental results show that the proposed algorithm, compared to other parameter sharing baselines, has better interpretability and stronger adaptability. The proposed methodology will help the MARL community gain a more comprehensive and profound understanding of heterogeneity, and further promote the development of practical algorithms.
Do LLMs Understand Wine Descriptors Across Cultures? A Benchmark for Cultural Adaptations of Wine Reviews
Sep 16, 2025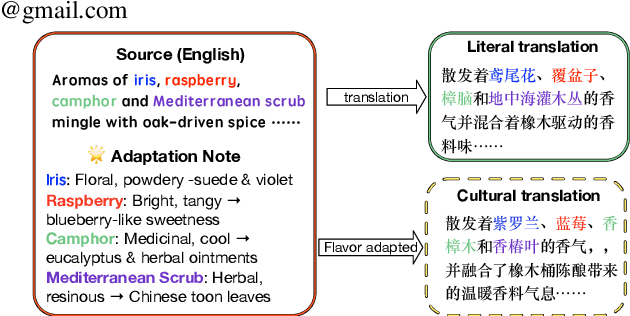
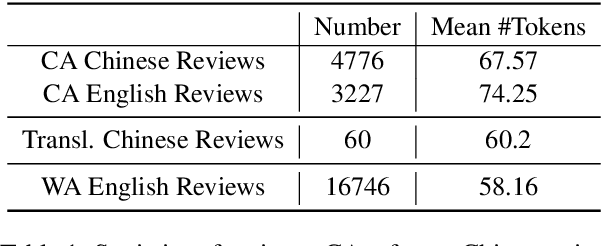
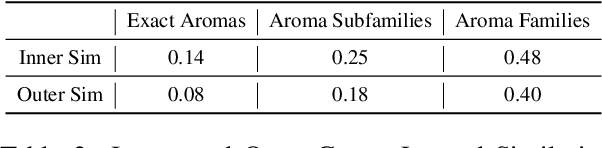
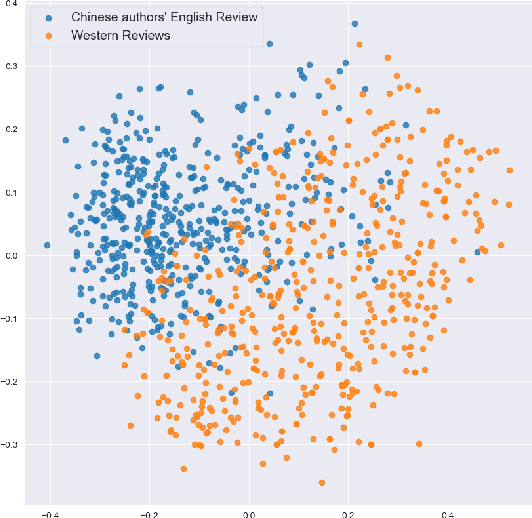
Recent advances in large language models (LLMs) have opened the door to culture-aware language tasks. We introduce the novel problem of adapting wine reviews across Chinese and English, which goes beyond literal translation by incorporating regional taste preferences and culture-specific flavor descriptors. In a case study on cross-cultural wine review adaptation, we compile the first parallel corpus of professional reviews, containing 8k Chinese and 16k Anglophone reviews. We benchmark both neural-machine-translation baselines and state-of-the-art LLMs with automatic metrics and human evaluation. For the latter, we propose three culture-oriented criteria -- Cultural Proximity, Cultural Neutrality, and Cultural Genuineness -- to assess how naturally a translated review resonates with target-culture readers. Our analysis shows that current models struggle to capture cultural nuances, especially in translating wine descriptions across different cultures. This highlights the challenges and limitations of translation models in handling cultural content.
Will You Be Aware? Eye Tracking-Based Modeling of Situational Awareness in Augmented Reality
Aug 07, 2025Augmented Reality (AR) systems, while enhancing task performance through real-time guidance, pose risks of inducing cognitive tunneling-a hyperfocus on virtual content that compromises situational awareness (SA) in safety-critical scenarios. This paper investigates SA in AR-guided cardiopulmonary resuscitation (CPR), where responders must balance effective compressions with vigilance to unpredictable hazards (e.g., patient vomiting). We developed an AR app on a Magic Leap 2 that overlays real-time CPR feedback (compression depth and rate) and conducted a user study with simulated unexpected incidents (e.g., bleeding) to evaluate SA, in which SA metrics were collected via observation and questionnaires administered during freeze-probe events. Eye tracking analysis revealed that higher SA levels were associated with greater saccadic amplitude and velocity, and with reduced proportion and frequency of fixations on virtual content. To predict SA, we propose FixGraphPool, a graph neural network that structures gaze events (fixations, saccades) into spatiotemporal graphs, effectively capturing dynamic attentional patterns. Our model achieved 83.0% accuracy (F1=81.0%), outperforming feature-based machine learning and state-of-the-art time-series models by leveraging domain knowledge and spatial-temporal information encoded in ET data. These findings demonstrate the potential of eye tracking for SA modeling in AR and highlight its utility in designing AR systems that ensure user safety and situational awareness.
Culinary Crossroads: A RAG Framework for Enhancing Diversity in Cross-Cultural Recipe Adaptation
Jul 29, 2025In cross-cultural recipe adaptation, the goal is not only to ensure cultural appropriateness and retain the original dish's essence, but also to provide diverse options for various dietary needs and preferences. Retrieval Augmented Generation (RAG) is a promising approach, combining the retrieval of real recipes from the target cuisine for cultural adaptability with large language models (LLMs) for relevance. However, it remains unclear whether RAG can generate diverse adaptation results. Our analysis shows that RAG tends to overly rely on a limited portion of the context across generations, failing to produce diverse outputs even when provided with varied contextual inputs. This reveals a key limitation of RAG in creative tasks with multiple valid answers: it fails to leverage contextual diversity for generating varied responses. To address this issue, we propose CARRIAGE, a plug-and-play RAG framework for cross-cultural recipe adaptation that enhances diversity in both retrieval and context organization. To our knowledge, this is the first RAG framework that explicitly aims to generate highly diverse outputs to accommodate multiple user preferences. Our experiments show that CARRIAGE achieves Pareto efficiency in terms of diversity and quality of recipe adaptation compared to closed-book LLMs.
Evaluation Hallucination in Multi-Round Incomplete Information Lateral-Driven Reasoning Tasks
May 28, 2025


Multi-round incomplete information tasks are crucial for evaluating the lateral thinking capabilities of large language models (LLMs). Currently, research primarily relies on multiple benchmarks and automated evaluation metrics to assess these abilities. However, our study reveals novel insights into the limitations of existing methods, as they often yield misleading results that fail to uncover key issues, such as shortcut-taking behaviors, rigid patterns, and premature task termination. These issues obscure the true reasoning capabilities of LLMs and undermine the reliability of evaluations. To address these limitations, we propose a refined set of evaluation standards, including inspection of reasoning paths, diversified assessment metrics, and comparative analyses with human performance.