 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinMMDocR: Benchmarking Financial Multimodal Reasoning with Scenario Awareness, Document Understanding, and Multi-Step Computation
Dec 31, 2025We introduce FinMMDocR, a novel bilingual multimodal benchmark for evaluating multimodal large language models (MLLMs) on real-world financial numerical reasoning. Compared to existing benchmarks, our work delivers three major advancements. (1) Scenario Awareness: 57.9% of 1,200 expert-annotated problems incorporate 12 types of implicit financial scenarios (e.g., Portfolio Management), challenging models to perform expert-level reasoning based on assumptions; (2) Document Understanding: 837 Chinese/English documents spanning 9 types (e.g., Company Research) average 50.8 pages with rich visual elements, significantly surpassing existing benchmarks in both breadth and depth of financial documents; (3) Multi-Step Computation: Problems demand 11-step reasoning on average (5.3 extraction + 5.7 calculation steps), with 65.0% requiring cross-page evidence (2.4 pages average). The best-performing MLLM achieves only 58.0% accuracy, and different retrieval-augmented generation (RAG) methods show significant performance variations on this task. We expect FinMMDocR to drive improvements in MLLMs and reasoning-enhanced methods on complex multimodal reasoning tasks in real-world scenarios.
RETuning: Upgrading Inference-Time Scaling for Stock Movement Prediction with Large Language Models
Oct 24, 2025Recently, large language models (LLMs) have demonstrated outstanding reasoning capabilities on mathematical and coding tasks. However, their application to financial tasks-especially the most fundamental task of stock movement prediction-remains underexplored. We study a three-class classification problem (up, hold, down) and, by analyzing existing reasoning responses, observe that: (1) LLMs follow analysts' opinions rather than exhibit a systematic, independent analytical logic (CoTs). (2) LLMs list summaries from different sources without weighing adversarial evidence, yet such counterevidence is crucial for reliable prediction. It shows that the model does not make good use of its reasoning ability to complete the task. To address this, we propose Reflective Evidence Tuning (RETuning), a cold-start method prior to reinforcement learning, to enhance prediction ability. While generating CoT, RETuning encourages dynamically constructing an analytical framework from diverse information sources, organizing and scoring evidence for price up or down based on that framework-rather than on contextual viewpoints-and finally reflecting to derive the prediction. This approach maximally aligns the model with its learned analytical framework, ensuring independent logical reasoning and reducing undue influence from context. We also build a large-scale dataset spanning all of 2024 for 5,123 A-share stocks, with long contexts (32K tokens) and over 200K samples. In addition to price and news, it incorporates analysts' opinions, quantitative reports, fundamental data, macroeconomic indicators, and similar stocks. Experiments show that RETuning successfully unlocks the model's reasoning ability in the financial domain. Inference-time scaling still works even after 6 months or on out-of-distribution stocks, since the models gain valuable insights about stock movement prediction.
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Oct 14, 2025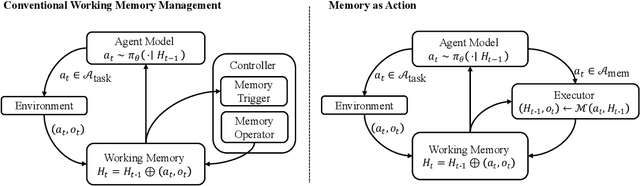
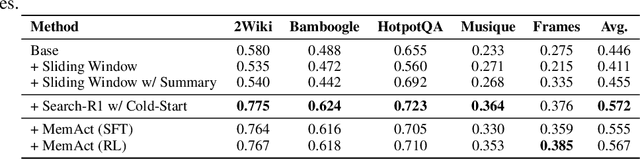
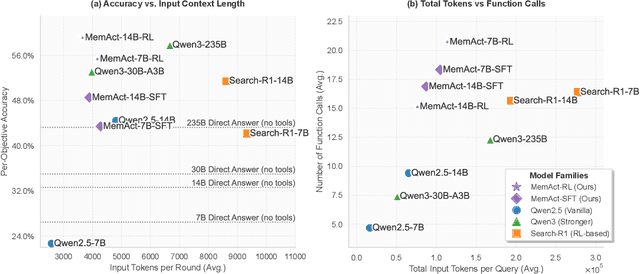
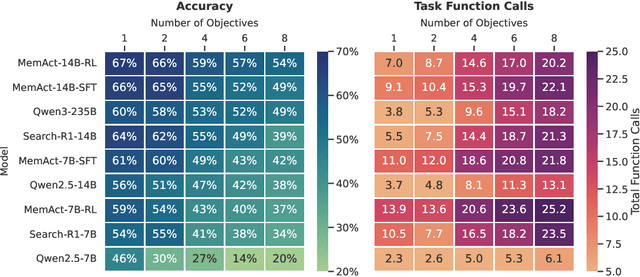
Large Language Models face challenges in long-horizon agentic tasks as their constrained memory is easily overwhelmed by distracting or irrelevant context. Existing working memory methods typically rely on external, heuristic mechanisms that are decoupled from the agent's core policy. In this work, we reframe working memory management as a learnable, intrinsic capability. We propose a novel framework, Memory-as-Action, where an agent actively manages its working memory by executing explicit editing operations as part of a unified policy. This formulation allows an agent, trained via reinforcement learning, to balance memory curation against long-term task objectives under given resource constraints. However, such memory editing actions break the standard assumption of a continuously growing prefix in LLM interactions, leading to what we call trajectory fractures. These non-prefix changes disrupt the causal continuity required by standard policy gradient methods, making those methods inapplicable. To address this, we propose a new algorithm, Dynamic Context Policy Optimization, which enables stable end-to-end reinforcement learning by segmenting trajectories at memory action points and applying trajectory-level advantages to the resulting action segments. Our results demonstrate that jointly optimizing for task reasoning and memory management in an end-to-end fashion not only reduces overall computational consumption but also improves task performance, driven by adaptive context curation strategies tailored to the model's intrinsic capabilities.
GraphSearch: An Agentic Deep Searching Workflow for Graph Retrieval-Augmented Generation
Sep 26, 2025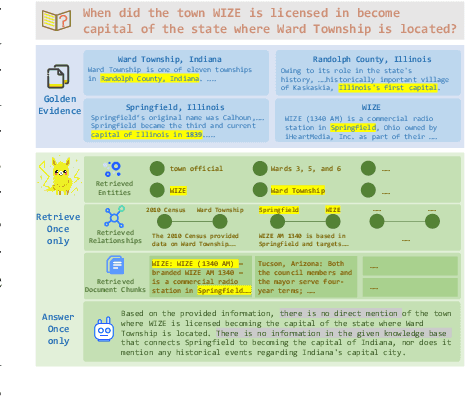
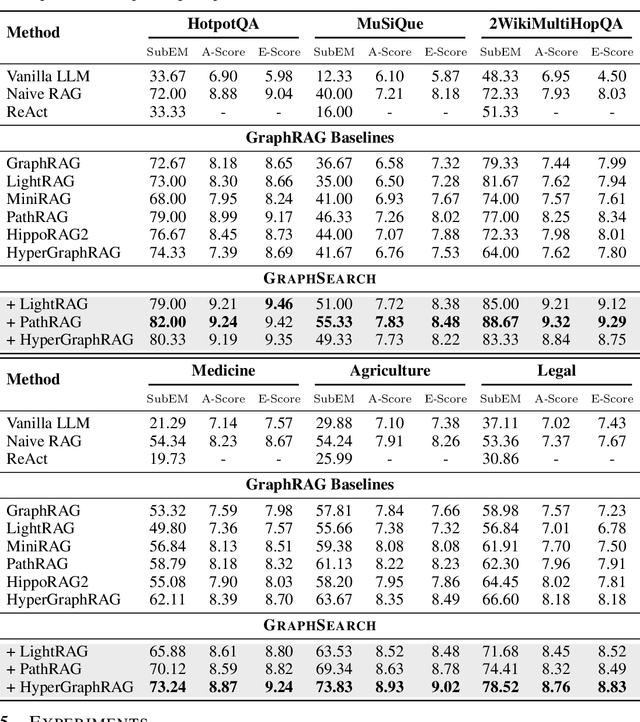

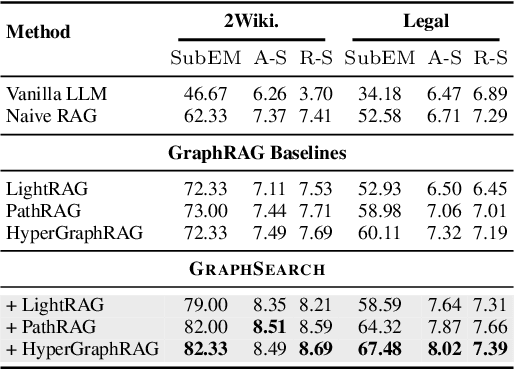
Graph Retrieval-Augmented Generation (GraphRAG) enhances factual reasoning in LLMs by structurally modeling knowledge through graph-based representations. However, existing GraphRAG approaches face two core limitations: shallow retrieval that fails to surface all critical evidence, and inefficient utilization of pre-constructed structural graph data, which hinders effective reasoning from complex queries. To address these challenges, we propose \textsc{GraphSearch}, a novel agentic deep searching workflow with dual-channel retrieval for GraphRAG. \textsc{GraphSearch} organizes the retrieval process into a modular framework comprising six modules, enabling multi-turn interactions and iterative reasoning. Furthermore, \textsc{GraphSearch} adopts a dual-channel retrieval strategy that issues semantic queries over chunk-based text data and relational queries over structural graph data, enabling comprehensive utilization of both modalities and their complementary strengths. Experimental results across six multi-hop RAG benchmarks demonstrate that \textsc{GraphSearch} consistently improves answer accuracy and generation quality over the traditional strategy, confirming \textsc{GraphSearch} as a promising direction for advancing graph retrieval-augmented generation.
Select2Reason: Efficient Instruction-Tuning Data Selection for Long-CoT Reasoning
May 22, 2025A practical approach to activate long chain-of-thoughts reasoning ability in pre-trained large language models is to perform supervised fine-tuning on instruction datasets synthesized by strong Large Reasoning Models such as DeepSeek-R1, offering a cost-effective alternative to reinforcement learning. However, large-scale instruction sets with more than 100k samples incur significant training overhead, while effective strategies for automatic long-CoT instruction selection still remain unexplored. In this work, we propose Select2Reason, a novel and efficient instruction-tuning data selection framework for long-CoT reasoning. From the perspective of emergence of rethinking behaviors like self-correction and backtracking, we investigate common metrics that may determine the quality of long-CoT reasoning instructions. Select2Reason leverages a quantifier to estimate difficulty of question and jointly incorporates a reasoning trace length-based heuristic through a weighted scheme for ranking to prioritize high-utility examples. Empirical results on OpenR1-Math-220k demonstrate that fine-tuning LLM on only 10% of the data selected by Select2Reason achieves performance competitive with or superior to full-data tuning and open-source baseline OpenR1-Qwen-7B across three competition-level and six comprehensive mathematical benchmarks. Further experiments highlight the scalability in varying data size, efficiency during inference, and its adaptability to other instruction pools with minimal cost.
LongFaith: Enhancing Long-Context Reasoning in LLMs with Faithful Synthetic Data
Feb 18, 2025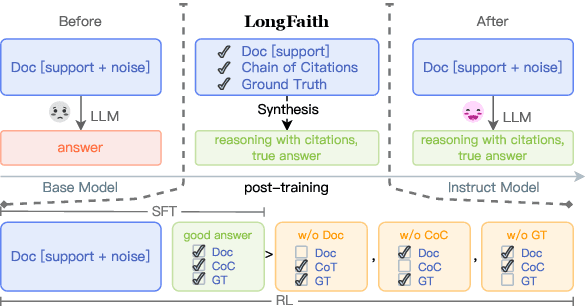
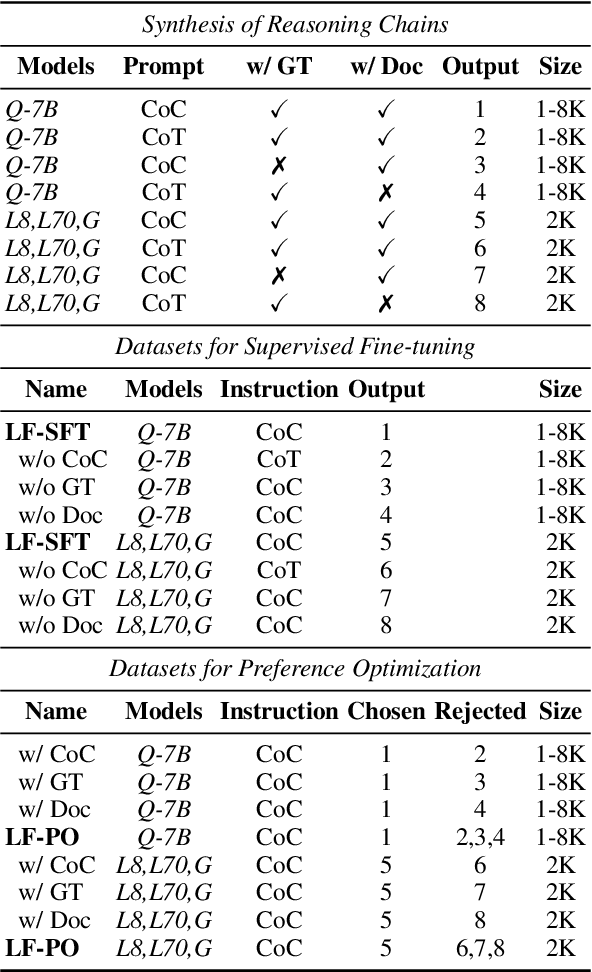
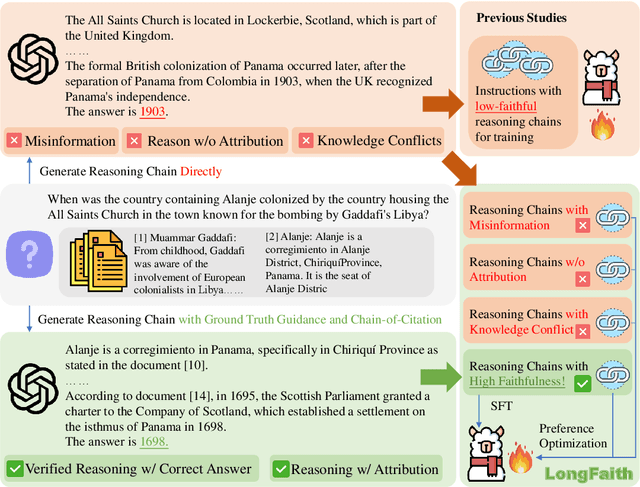
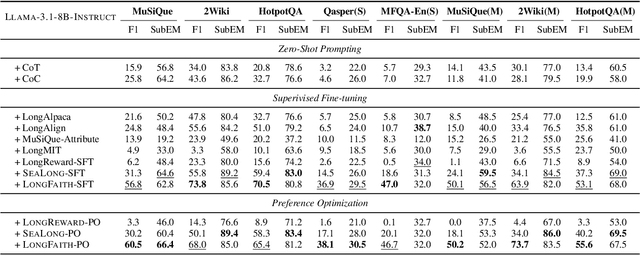
Despite the growing development of long-context large language models (LLMs), data-centric approaches relying on synthetic data have been hindered by issues related to faithfulness, which limit their effectiveness in enhancing model performance on tasks such as long-context reasoning and question answering (QA). These challenges are often exacerbated by misinformation caused by lack of verification, reasoning without attribution, and potential knowledge conflicts. We propose LongFaith, a novel pipeline for synthesizing faithful long-context reasoning instruction datasets. By integrating ground truth and citation-based reasoning prompts, we eliminate distractions and improve the accuracy of reasoning chains, thus mitigating the need for costly verification processes. We open-source two synthesized datasets, LongFaith-SFT and LongFaith-PO, which systematically address multiple dimensions of faithfulness, including verified reasoning, attribution, and contextual grounding. Extensive experiments on multi-hop reasoning datasets and LongBench demonstrate that models fine-tuned on these datasets significantly improve performance. Our ablation studies highlight the scalability and adaptability of the LongFaith pipeline, showcasing its broad applicability in developing long-context LLMs.
NQE: N-ary Query Embedding for Complex Query Answering over Hyper-relational Knowledge Graphs
Nov 24, 2022Complex query answering (CQA) is an essential task for multi-hop and logical reasoning on knowledge graphs (KGs). Currently, most approaches are limited to queries among binary relational facts and pay less attention to n-ary facts (n>=2) containing more than two entities, which are more prevalent in the real world. Moreover, previous CQA methods can only make predictions for a few given types of queries and cannot be flexibly extended to more complex logical queries, which significantly limits their applications. To overcome these challenges, in this work, we propose a novel N-ary Query Embedding (NQE) model for CQA over hyper-relational knowledge graphs (HKGs), which include massive n-ary facts. The NQE utilizes a dual-heterogeneous Transformer encoder and fuzzy logic theory to satisfy all n-ary FOL queries, including existential quantifiers, conjunction, disjunction, and negation. We also propose a parallel processing algorithm that can train or predict arbitrary n-ary FOL queries in a single batch, regardless of the kind of each query, with good flexibility and extensibility. In addition, we generate a new CQA dataset WD50K-NFOL, including diverse n-ary FOL queries over WD50K. Experimental results on WD50K-NFOL and other standard CQA datasets show that NQE is the state-of-the-art CQA method over HKGs with good generalization capability. Our code and dataset are publicly available.
DHGE: Dual-view Hyper-Relational Knowledge Graph Embedding for Link Prediction and Entity Typing
Jul 18, 2022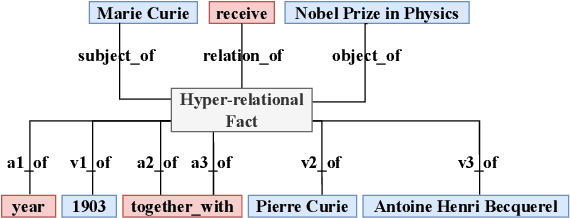
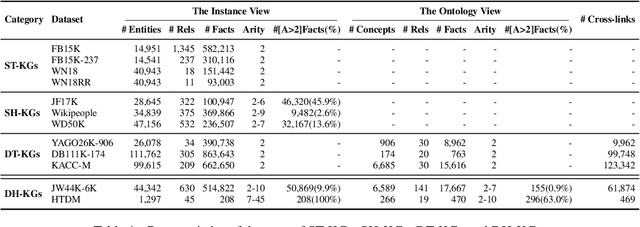
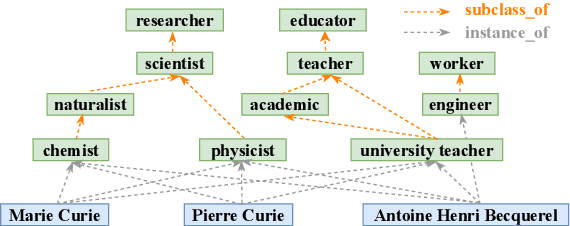
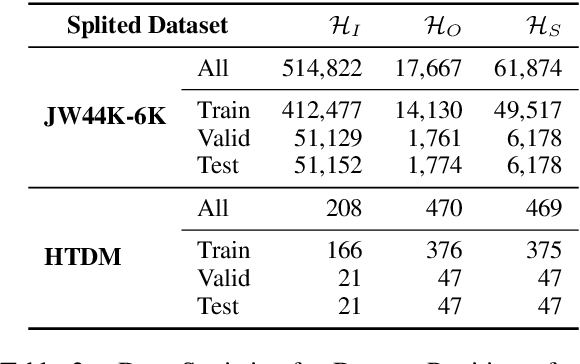
In the field of representation learning on knowledge graphs (KGs), a hyper-relational fact consists of a main triple and several auxiliary attribute value descriptions, which is considered to be more comprehensive and specific than a triple-based fact. However, the existing hyper-relational KG embedding methods in a single view are limited in application due to weakening the hierarchical structure representing the affiliation between entities. To break this limitation, we propose a dual-view hyper-relational KG (DH-KG) structure which contains a hyper-relational instance view for entities and a hyper-relational ontology view for concepts abstracted hierarchically from entities to jointly model hyper-relational and hierarchical information. In this paper, we first define link prediction and entity typing tasks on DH-KG and construct two DH-KG datasets, JW44K-6K extracted from Wikidata and HTDM based on medical data. Furthermore, We propose a DH-KG embedding model DHGE, based on GRAN encoder, HGNN, and joint learning. Experimental results show that DHGE outperforms baseline models on DH-KG. We also provide an example of the application of this technology in the field of hypertension medication. Our model and datasets are publicly available.
TFLEX: Temporal Feature-Logic Embedding Framework for Complex Reasoning over Temporal Knowledge Graph
May 28, 2022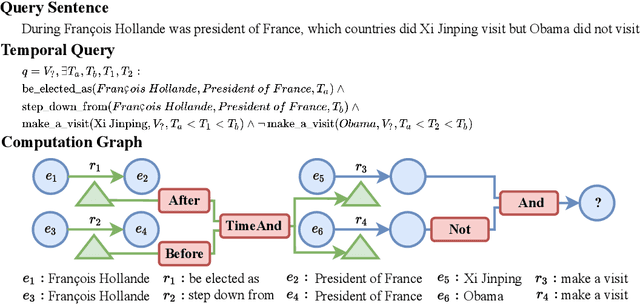

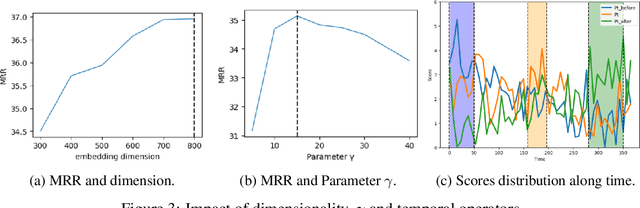
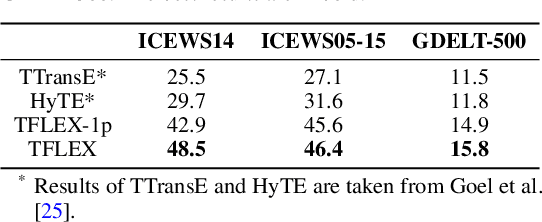
Multi-hop logical reasoning over knowledge graph (KG) plays a fundamental role in many artificial intelligence tasks. Recent complex query embedding (CQE) methods for reasoning focus on static KGs, while temporal knowledge graphs (TKGs) have not been fully explored. Reasoning over TKGs has two challenges: 1. The query should answer entities or timestamps; 2. The operators should consider both set logic on entity set and temporal logic on timestamp set. To bridge this gap, we define the multi-hop logical reasoning problem on TKGs. With generated three datasets, we propose the first temporal CQE named Temporal Feature-Logic Embedding framework (TFLEX) to answer the temporal complex queries. We utilize vector logic to compute the logic part of Temporal Feature-Logic embeddings, thus naturally modeling all First-Order Logic (FOL) operations on entity set. In addition, our framework extends vector logic on timestamp set to cope with three extra temporal operators (After, Before and Between). Experiments on numerous query patterns demonstrate the effectiveness of our method.
FLEX: Feature-Logic Embedding Framework for CompleX Knowledge Graph Reasoning
May 23, 2022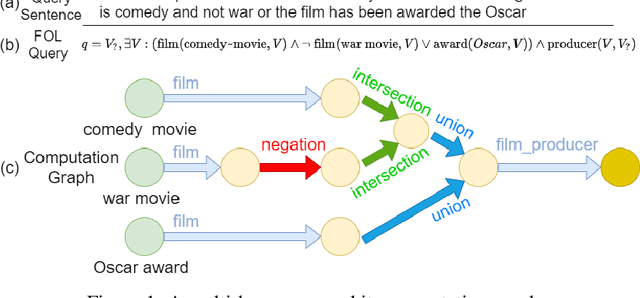
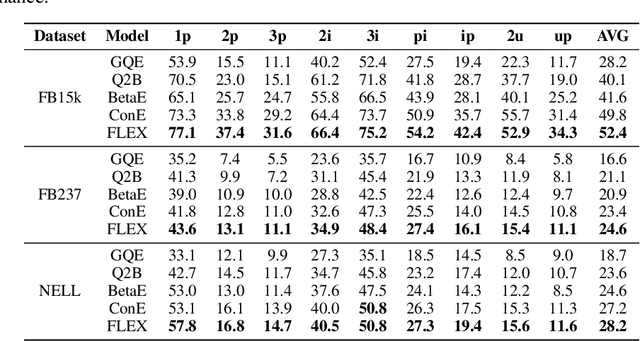
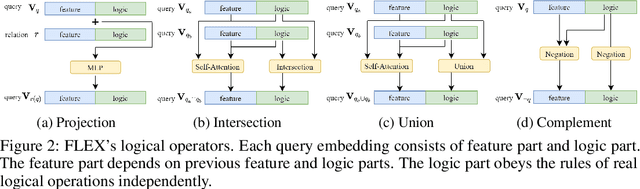
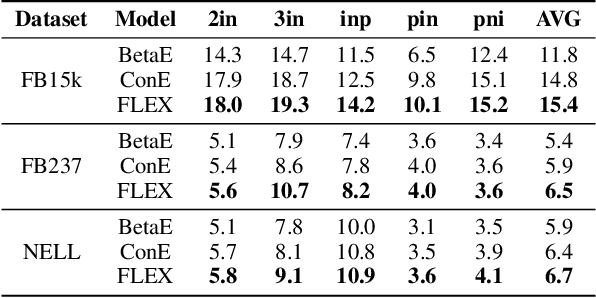
Current best performing models for knowledge graph reasoning (KGR) are based on complex distribution or geometry objects to embed entities and first-order logical (FOL) queries in low-dimensional spaces. They can be summarized as a center-size framework (point/box/cone, Beta/Gaussian distribution, etc.) whose logical reasoning ability is limited by the expressiveness of the relevant mathematical concepts. Because too deeply the center and the size depend on each other, it is difficult to integrate the logical reasoning ability with other models. To address these challenges, we instead propose a novel KGR framework named Feature-Logic Embedding framework, FLEX, which is the first KGR framework that can not only TRULY handle all FOL operations including conjunction, disjunction, negation and so on, but also support various feature spaces. Specifically, the logic part of feature-logic framework is based on vector logic, which naturally models all FOL operations. Experiments demonstrate that FLEX significantly outperforms existing state-of-the-art methods on benchmark datasets.