 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Skeletons: Learning Animation Directly from Driving Videos with Same2X Training Strategy
Jun 05, 2026Human image animation aims to generate a video from a static reference image, guided by pose information extracted from a driving video. Existing approaches often rely on pose estimators to extract intermediate representations, but such signals are prone to errors under occlusion or complex poses. Building on these observations, we present DirectAnimator, a framework that bypasses pose extraction and directly learns from raw driving videos. We introduce a Driving Cue Triplet consisting of pose, face, and location cues that captures motion, expression, and alignment in a semantically rich yet stable form, and we fuse them through a CueFusion DiT block for reliable control during denoising. To make learning dependable when the driving and reference identities differ, we devise a Same2X training strategy that aligns cross-ID features with those learned from same-ID data, regularizing optimization and accelerating convergence. Extensive experiments demonstrate that DirectAnimator attains state-of-the-art visual quality and identity preservation while remaining robust to occlusions and complex articulation, and it does so with fewer computational resources. Our project page is at https://directanimator.github.io/.
When Does Hierarchy Help? Benchmarking Agent Coordination in Event-Driven Industrial Scheduling
May 13, 2026Recent advances in agent and multi-agent systems have shown strong performance on tool use, reasoning, and collaborative tasks. However, existing benchmarks mostly evaluate task completion in weakly coupled environments, and provide limited support for studying coordination in shared, dynamically evolving systems with hierarchy and coupled constraints. This leaves an important question underexplored: when do different coordination paradigms succeed or fail? We introduce Distributed Event-driven Scheduling Benchmark (DESBench), a benchmark for evaluating agent coordination in hierarchical event-driven scheduling. Built on a shared discrete-event driven environment in industrial scheduling, our benchmark captures multi-timescale decision making, partial observability, and dynamically coupled constraints. We define tasks and metrics that evaluate effectiveness, constraint alignment, coordination efficiency, and robustness, and focus on four representative coordination paradigms: centralized, hierarchical, heterarchical, and holonic. These paradigms correspond to distinct mechanisms of information flow, decision authority, and conflict resolution. Our controlled evaluations reveal clear coordination trade-offs: centralized coordination is robust and communication-efficient but scales poorly with difficulty; hierarchical coordination improves efficiency through decomposition but suffers from cross-level misalignment; heterarchical coordination is flexible but communication-heavy; and holonic coordination satisfies constraints well but loses global robustness. These findings demonstrate that coordination design fundamentally shapes agent system behavior in complex environments, revealing structural trade-offs that cannot be captured by outcome metrics alone and underscoring the imperative for more adaptive, principled, and dynamic coordination mechanisms in future MAS research.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
S2SServiceBench: A Multimodal Benchmark for Last-Mile S2S Climate Services
Feb 15, 2026Subseasonal-to-seasonal (S2S) forecasts play an essential role in providing a decision-critical weeks-to-months planning window for climate resilience and sustainability, yet a growing bottleneck is the last-mile gap: translating scientific forecasts into trusted, actionable climate services, requiring reliable multimodal understanding and decision-facing reasoning under uncertainty. Meanwhile, multimodal large language models (MLLMs) and corresponding agentic paradigms have made rapid progress in supporting various workflows, but it remains unclear whether they can reliably generate decision-making deliverables from operational service products (e.g., actionable signal comprehension, decision-making handoff, and decision analysis & planning) under uncertainty. We introduce S2SServiceBench, a multimodal benchmark for last-mile S2S climate services curated from an operational climate-service system to evaluate this capability. S2SServiceBenchcovers 10 service products with about 150+ expert-selected cases in total, spanning six application domains - Agriculture, Disasters, Energy, Finance, Health, and Shipping. Each case is instantiated at three service levels, yielding around 500 tasks and 1,000+ evaluation items across climate resilience and sustainability applications. Using S2SServiceBench, we benchmark state-of-the-art MLLMs and agents, and analyze performance across products and service levels, revealing persistent challenges in S2S service plot understanding and reasoning - namely, actionable signal comprehension, operationalizing uncertainty into executable handoffs, and stable, evidence-grounded analysis and planning for dynamic hazards-while offering actionable guidance for building future climate-service agents.
6DAttack: Backdoor Attacks in the 6DoF Pose Estimation
Dec 22, 2025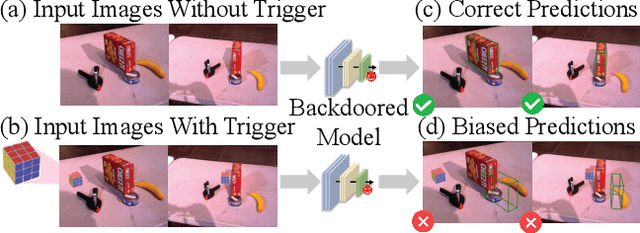
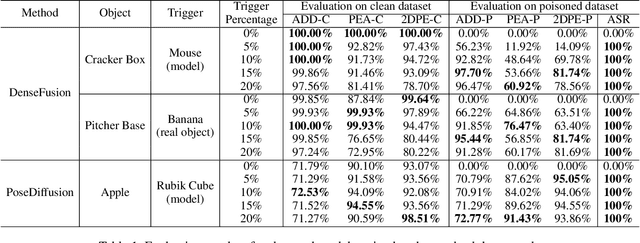
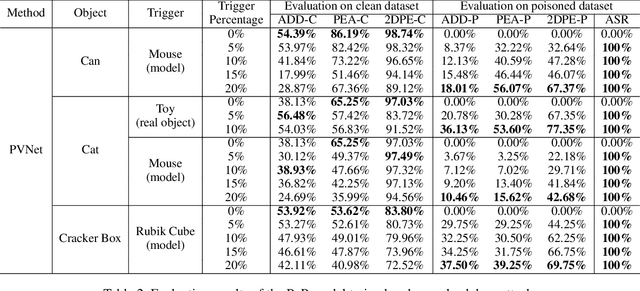
Deep learning advances have enabled accurate six-degree-of-freedom (6DoF) object pose estimation, widely used in robotics, AR/VR, and autonomous systems. However, backdoor attacks pose significant security risks. While most research focuses on 2D vision, 6DoF pose estimation remains largely unexplored. Unlike traditional backdoors that only change classes, 6DoF attacks must control continuous parameters like translation and rotation, rendering 2D methods inapplicable. We propose 6DAttack, a framework using 3D object triggers to induce controlled erroneous poses while maintaining normal behavior. Evaluations on PVNet, DenseFusion, and PoseDiffusion across LINEMOD, YCB-Video, and CO3D show high attack success rates (ASRs) without compromising clean performance. Backdoored models achieve up to 100% clean ADD accuracy and 100% ASR, with triggered samples reaching 97.70% ADD-P. Furthermore, a representative defense remains ineffective. Our findings reveal a serious, underexplored threat to 6DoF pose estimation.
See-Control: A Multimodal Agent Framework for Smartphone Interaction with a Robotic Arm
Dec 09, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enabled their use as intelligent agents for smartphone operation. However, existing methods depend on the Android Debug Bridge (ADB) for data transmission and action execution, limiting their applicability to Android devices. In this work, we introduce the novel Embodied Smartphone Operation (ESO) task and present See-Control, a framework that enables smartphone operation via direct physical interaction with a low-DoF robotic arm, offering a platform-agnostic solution. See-Control comprises three key components: (1) an ESO benchmark with 155 tasks and corresponding evaluation metrics; (2) an MLLM-based embodied agent that generates robotic control commands without requiring ADB or system back-end access; and (3) a richly annotated dataset of operation episodes, offering valuable resources for future research. By bridging the gap between digital agents and the physical world, See-Control provides a concrete step toward enabling home robots to perform smartphone-dependent tasks in realistic environments.
Hi-Agent: Hierarchical Vision-Language Agents for Mobile Device Control
Oct 16, 2025Building agents that autonomously operate mobile devices has attracted increasing attention. While Vision-Language Models (VLMs) show promise, most existing approaches rely on direct state-to-action mappings, which lack structured reasoning and planning, and thus generalize poorly to novel tasks or unseen UI layouts. We introduce Hi-Agent, a trainable hierarchical vision-language agent for mobile control, featuring a high-level reasoning model and a low-level action model that are jointly optimized. For efficient training, we reformulate multi-step decision-making as a sequence of single-step subgoals and propose a foresight advantage function, which leverages execution feedback from the low-level model to guide high-level optimization. This design alleviates the path explosion issue encountered by Group Relative Policy Optimization (GRPO) in long-horizon tasks and enables stable, critic-free joint training. Hi-Agent achieves a new State-Of-The-Art (SOTA) 87.9% task success rate on the Android-in-the-Wild (AitW) benchmark, significantly outperforming prior methods across three paradigms: prompt-based (AppAgent: 17.7%), supervised (Filtered BC: 54.5%), and reinforcement learning-based (DigiRL: 71.9%). It also demonstrates competitive zero-shot generalization on the ScreenSpot-v2 benchmark. On the more challenging AndroidWorld benchmark, Hi-Agent also scales effectively with larger backbones, showing strong adaptability in high-complexity mobile control scenarios.
Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025
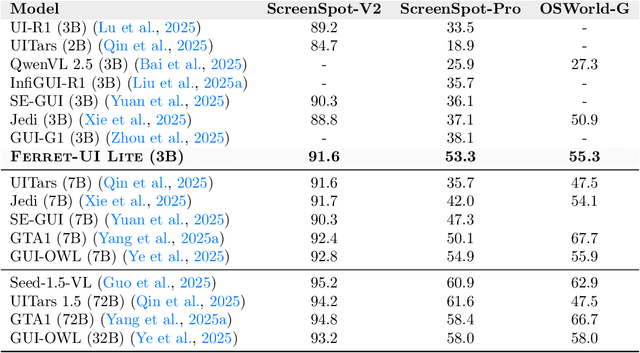
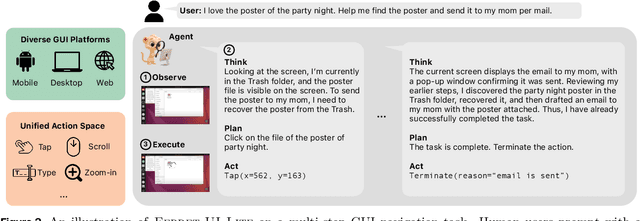
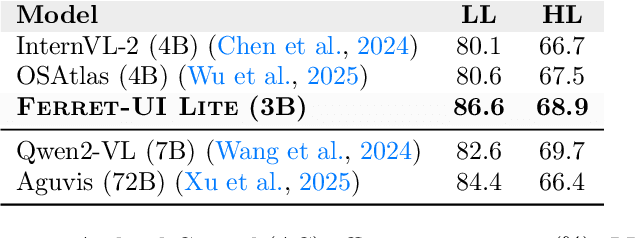
Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
Sparse Meets Dense: Unified Generative Recommendations with Cascaded Sparse-Dense Representations
Mar 04, 2025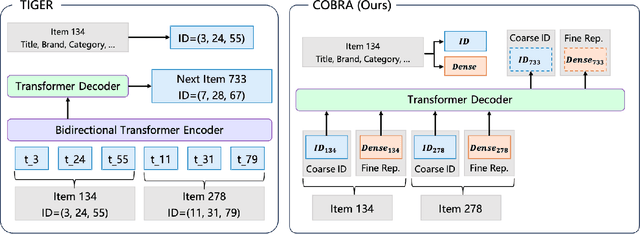
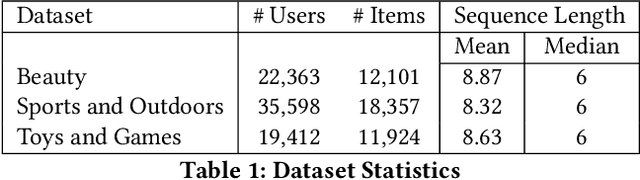
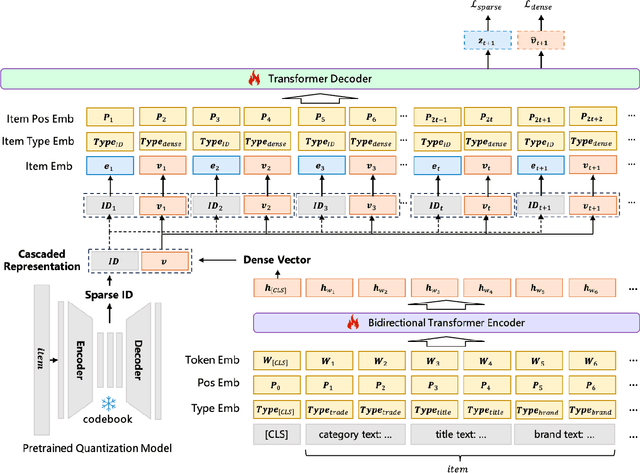
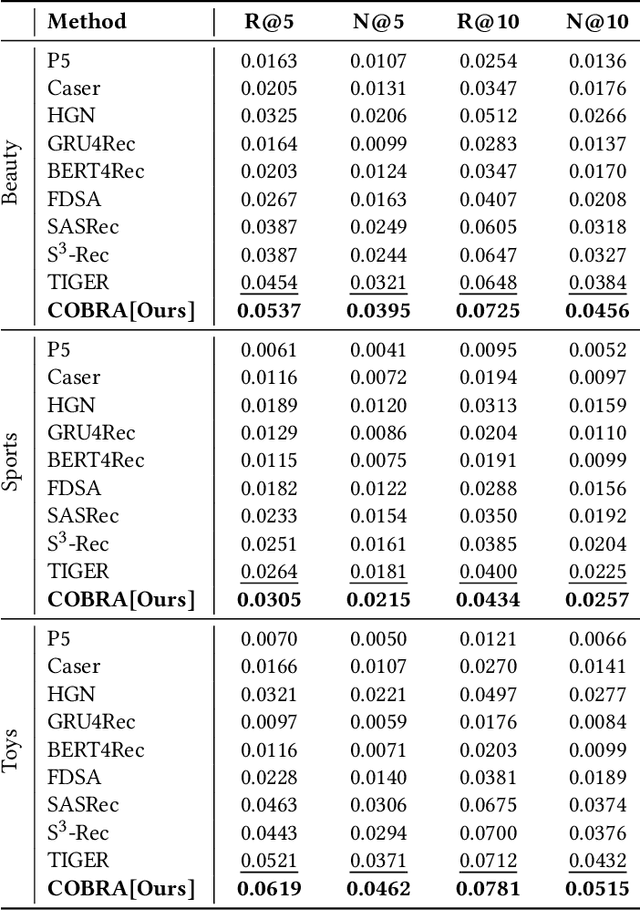
Generative models have recently gained attention in recommendation systems by directly predicting item identifiers from user interaction sequences. However, existing methods suffer from significant information loss due to the separation of stages such as quantization and sequence modeling, hindering their ability to achieve the modeling precision and accuracy of sequential dense retrieval techniques. Integrating generative and dense retrieval methods remains a critical challenge. To address this, we introduce the Cascaded Organized Bi-Represented generAtive retrieval (COBRA) framework, which innovatively integrates sparse semantic IDs and dense vectors through a cascading process. Our method alternates between generating these representations by first generating sparse IDs, which serve as conditions to aid in the generation of dense vectors. End-to-end training enables dynamic refinement of dense representations, capturing both semantic insights and collaborative signals from user-item interactions. During inference, COBRA employs a coarse-to-fine strategy, starting with sparse ID generation and refining them into dense vectors via the generative model. We further propose BeamFusion, an innovative approach combining beam search with nearest neighbor scores to enhance inference flexibility and recommendation diversity. Extensive experiments on public datasets and offline tests validate our method's robustness. Online A/B tests on a real-world advertising platform with over 200 million daily users demonstrate substantial improvements in key metrics, highlighting COBRA's practical advantages.