 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Preference-Guided Diffusion Model for Cross-Domain Recommendation
Jan 20, 2025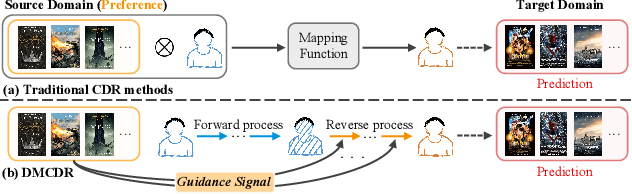
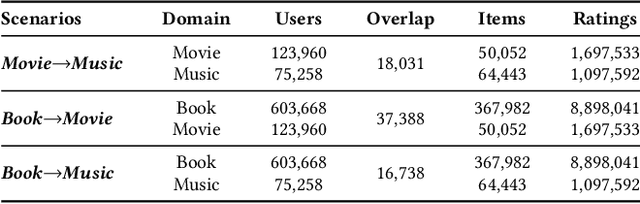
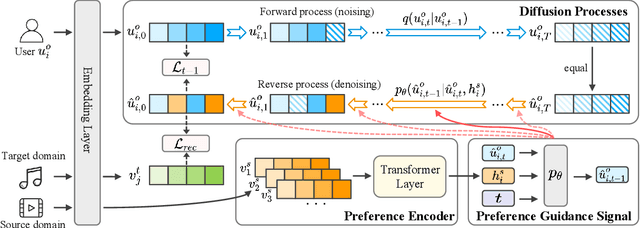
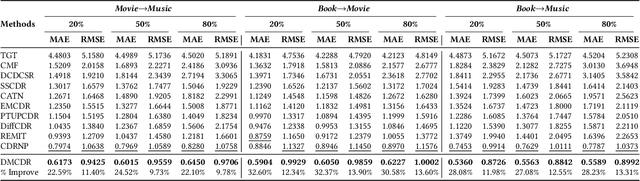
Cross-domain recommendation (CDR) has been proven as a promising way to alleviate the cold-start issue, in which the most critical problem is how to draw an informative user representation in the target domain via the transfer of user preference existing in the source domain. Prior efforts mostly follow the embedding-and-mapping paradigm, which first integrate the preference into user representation in the source domain, and then perform a mapping function on this representation to the target domain. However, they focus on mapping features across domains, neglecting to explicitly model the preference integration process, which may lead to learning coarse user representation. Diffusion models (DMs), which contribute to more accurate user/item representations due to their explicit information injection capability, have achieved promising performance in recommendation systems. Nevertheless, these DMs-based methods cannot directly account for valuable user preference in other domains, leading to challenges in adapting to the transfer of preference for cold-start users. Consequently, the feasibility of DMs for CDR remains underexplored. To this end, we explore to utilize the explicit information injection capability of DMs for user preference integration and propose a Preference-Guided Diffusion Model for CDR to cold-start users, termed as DMCDR. Specifically, we leverage a preference encoder to establish the preference guidance signal with the user's interaction history in the source domain. Then, we explicitly inject the preference guidance signal into the user representation step by step to guide the reverse process, and ultimately generate the personalized user representation in the target domain, thus achieving the transfer of user preference across domains. Furthermore, we comprehensively explore the impact of six DMs-based variants on CDR.
FltLM: An Intergrated Long-Context Large Language Model for Effective Context Filtering and Understanding
Oct 09, 2024
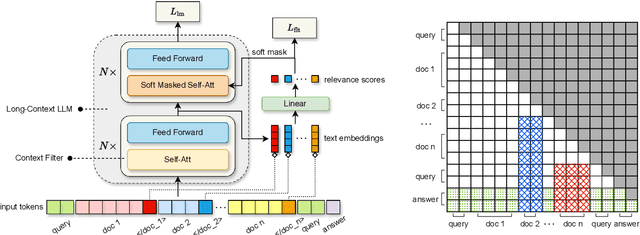

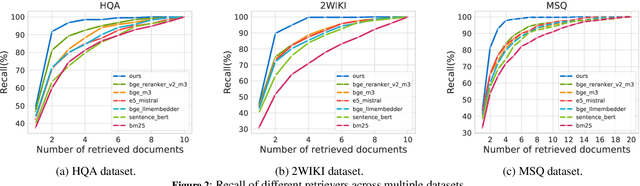
The development of Long-Context Large Language Models (LLMs) has markedly advanced natural language processing by facilitating the process of textual data across long documents and multiple corpora. However, Long-Context LLMs still face two critical challenges: The lost in the middle phenomenon, where crucial middle-context information is likely to be missed, and the distraction issue that the models lose focus due to overly extended contexts. To address these challenges, we propose the Context Filtering Language Model (FltLM), a novel integrated Long-Context LLM which enhances the ability of the model on multi-document question-answering (QA) tasks. Specifically, FltLM innovatively incorporates a context filter with a soft mask mechanism, identifying and dynamically excluding irrelevant content to concentrate on pertinent information for better comprehension and reasoning. Our approach not only mitigates these two challenges, but also enables the model to operate conveniently in a single forward pass. Experimental results demonstrate that FltLM significantly outperforms supervised fine-tuning and retrieval-based methods in complex QA scenarios, suggesting a promising solution for more accurate and reliable long-context natural language understanding applications.
Text-Video Retrieval via Variational Multi-Modal Hypergraph Networks
Jan 06, 2024Text-video retrieval is a challenging task that aims to identify relevant videos given textual queries. Compared to conventional textual retrieval, the main obstacle for text-video retrieval is the semantic gap between the textual nature of queries and the visual richness of video content. Previous works primarily focus on aligning the query and the video by finely aggregating word-frame matching signals. Inspired by the human cognitive process of modularly judging the relevance between text and video, the judgment needs high-order matching signal due to the consecutive and complex nature of video contents. In this paper, we propose chunk-level text-video matching, where the query chunks are extracted to describe a specific retrieval unit, and the video chunks are segmented into distinct clips from videos. We formulate the chunk-level matching as n-ary correlations modeling between words of the query and frames of the video and introduce a multi-modal hypergraph for n-ary correlation modeling. By representing textual units and video frames as nodes and using hyperedges to depict their relationships, a multi-modal hypergraph is constructed. In this way, the query and the video can be aligned in a high-order semantic space. In addition, to enhance the model's generalization ability, the extracted features are fed into a variational inference component for computation, obtaining the variational representation under the Gaussian distribution. The incorporation of hypergraphs and variational inference allows our model to capture complex, n-ary interactions among textual and visual contents. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on the text-video retrieval task.
Agent4Ranking: Semantic Robust Ranking via Personalized Query Rewriting Using Multi-agent LLM
Dec 24, 2023Search engines are crucial as they provide an efficient and easy way to access vast amounts of information on the internet for diverse information needs. User queries, even with a specific need, can differ significantly. Prior research has explored the resilience of ranking models against typical query variations like paraphrasing, misspellings, and order changes. Yet, these works overlook how diverse demographics uniquely formulate identical queries. For instance, older individuals tend to construct queries more naturally and in varied order compared to other groups. This demographic diversity necessitates enhancing the adaptability of ranking models to diverse query formulations. To this end, in this paper, we propose a framework that integrates a novel rewriting pipeline that rewrites queries from various demographic perspectives and a novel framework to enhance ranking robustness. To be specific, we use Chain of Thought (CoT) technology to utilize Large Language Models (LLMs) as agents to emulate various demographic profiles, then use them for efficient query rewriting, and we innovate a robust Multi-gate Mixture of Experts (MMoE) architecture coupled with a hybrid loss function, collectively strengthening the ranking models' robustness. Our extensive experimentation on both public and industrial datasets assesses the efficacy of our query rewriting approach and the enhanced accuracy and robustness of the ranking model. The findings highlight the sophistication and effectiveness of our proposed model.
LLMRec: Large Language Models with Graph Augmentation for Recommendation
Nov 17, 2023The problem of data sparsity has long been a challenge in recommendation systems, and previous studies have attempted to address this issue by incorporating side information. However, this approach often introduces side effects such as noise, availability issues, and low data quality, which in turn hinder the accurate modeling of user preferences and adversely impact recommendation performance. In light of the recent advancements in large language models (LLMs), which possess extensive knowledge bases and strong reasoning capabilities, we propose a novel framework called LLMRec that enhances recommender systems by employing three simple yet effective LLM-based graph augmentation strategies. Our approach leverages the rich content available within online platforms (e.g., Netflix, MovieLens) to augment the interaction graph in three ways: (i) reinforcing user-item interaction egde, (ii) enhancing the understanding of item node attributes, and (iii) conducting user node profiling, intuitively from the natural language perspective. By employing these strategies, we address the challenges posed by sparse implicit feedback and low-quality side information in recommenders. Besides, to ensure the quality of the augmentation, we develop a denoised data robustification mechanism that includes techniques of noisy implicit feedback pruning and MAE-based feature enhancement that help refine the augmented data and improve its reliability. Furthermore, we provide theoretical analysis to support the effectiveness of LLMRec and clarify the benefits of our method in facilitating model optimization. Experimental results on benchmark datasets demonstrate the superiority of our LLM-based augmentation approach over state-of-the-art techniques. To ensure reproducibility, we have made our code and augmented data publicly available at: https://github.com/HKUDS/LLMRec.git
Representation Learning with Large Language Models for Recommendation
Oct 24, 2023
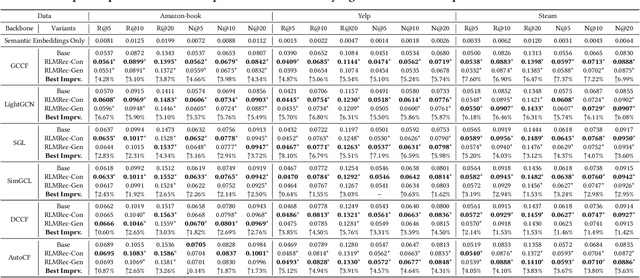
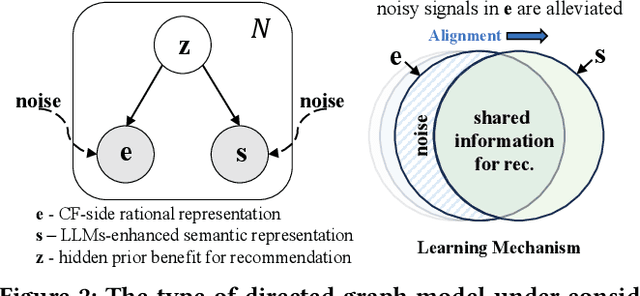
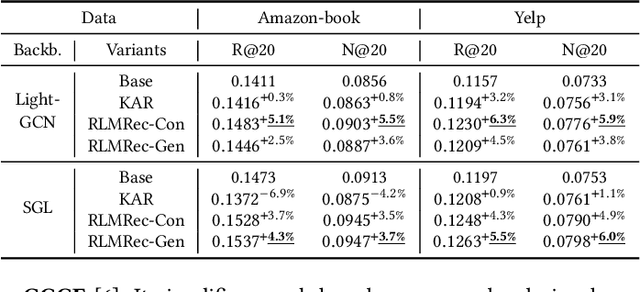
Recommender systems have seen significant advancements with the influence of deep learning and graph neural networks, particularly in capturing complex user-item relationships. However, these graph-based recommenders heavily depend on ID-based data, potentially disregarding valuable textual information associated with users and items, resulting in less informative learned representations. Moreover, the utilization of implicit feedback data introduces potential noise and bias, posing challenges for the effectiveness of user preference learning. While the integration of large language models (LLMs) into traditional ID-based recommenders has gained attention, challenges such as scalability issues, limitations in text-only reliance, and prompt input constraints need to be addressed for effective implementation in practical recommender systems. To address these challenges, we propose a model-agnostic framework RLMRec that aims to enhance existing recommenders with LLM-empowered representation learning. It proposes a recommendation paradigm that integrates representation learning with LLMs to capture intricate semantic aspects of user behaviors and preferences. RLMRec incorporates auxiliary textual signals, develops a user/item profiling paradigm empowered by LLMs, and aligns the semantic space of LLMs with the representation space of collaborative relational signals through a cross-view alignment framework. This work further establish a theoretical foundation demonstrating that incorporating textual signals through mutual information maximization enhances the quality of representations. In our evaluation, we integrate RLMRec with state-of-the-art recommender models, while also analyzing its efficiency and robustness to noise data. Our implementation codes are available at https://github.com/HKUDS/RLMRec.
GraphGPT: Graph Instruction Tuning for Large Language Models
Oct 19, 2023Graph Neural Networks (GNNs) have advanced graph structure understanding via recursive information exchange and aggregation among graph nodes. To improve model robustness, self-supervised learning (SSL) has emerged as a promising approach for data augmentation. However, existing methods for generating pre-trained graph embeddings often rely on fine-tuning with specific downstream task labels, which limits their usability in scenarios where labeled data is scarce or unavailable. To address this, our research focuses on advancing the generalization capabilities of graph models in challenging zero-shot learning scenarios. Inspired by the success of large language models (LLMs), we aim to develop a graph-oriented LLM that can achieve high generalization across diverse downstream datasets and tasks, even without any information available from the downstream graph data. In this work, we present the GraphGPT framework that aligns LLMs with graph structural knowledge with a graph instruction tuning paradigm. Our framework incorporates a text-graph grounding component to establish a connection between textual information and graph structures. Additionally, we propose a dual-stage instruction tuning paradigm, accompanied by a lightweight graph-text alignment projector. This paradigm explores self-supervised graph structural signals and task-specific graph instructions, to guide LLMs in understanding complex graph structures and improving their adaptability across different downstream tasks. Our framework is evaluated on supervised and zero-shot graph learning tasks, demonstrating superior generalization and outperforming state-of-the-art baselines.
Approximated Doubly Robust Search Relevance Estimation
Aug 16, 2022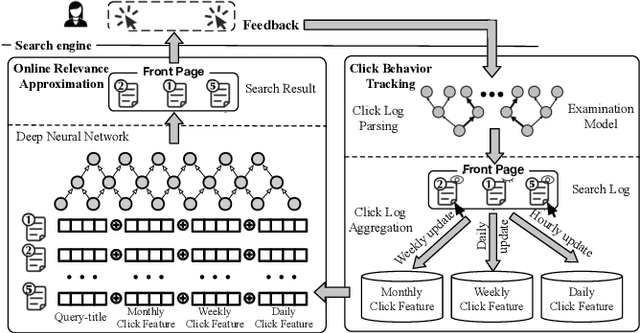
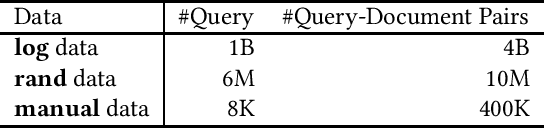
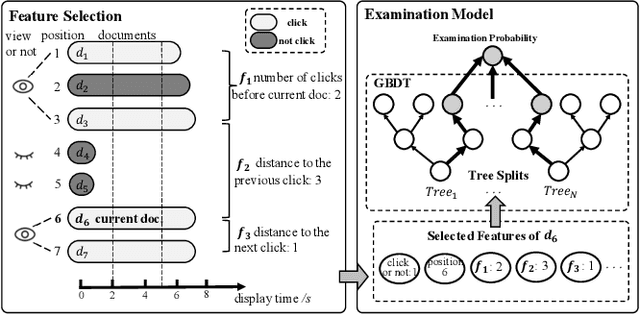
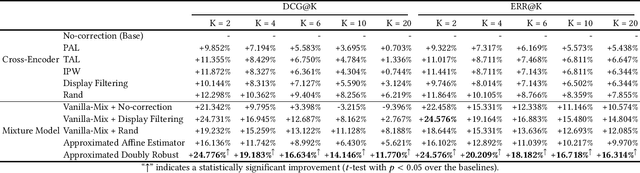
Extracting query-document relevance from the sparse, biased clickthrough log is among the most fundamental tasks in the web search system. Prior art mainly learns a relevance judgment model with semantic features of the query and document and ignores directly counterfactual relevance evaluation from the clicking log. Though the learned semantic matching models can provide relevance signals for tail queries as long as the semantic feature is available. However, such a paradigm lacks the capability to introspectively adjust the biased relevance estimation whenever it conflicts with massive implicit user feedback. The counterfactual evaluation methods, on the contrary, ensure unbiased relevance estimation with sufficient click information. However, they suffer from the sparse or even missing clicks caused by the long-tailed query distribution. In this paper, we propose to unify the counterfactual evaluating and learning approaches for unbiased relevance estimation on search queries with various popularities. Specifically, we theoretically develop a doubly robust estimator with low bias and variance, which intentionally combines the benefits of existing relevance evaluating and learning approaches. We further instantiate the proposed unbiased relevance estimation framework in Baidu search, with comprehensive practical solutions designed regarding the data pipeline for click behavior tracking and online relevance estimation with an approximated deep neural network. Finally, we present extensive empirical evaluations to verify the effectiveness of our proposed framework, finding that it is robust in practice and manages to improve online ranking performance substantially.
* 10 pages
Incorporating Explicit Knowledge in Pre-trained Language Models for Passage Re-ranking
Apr 25, 2022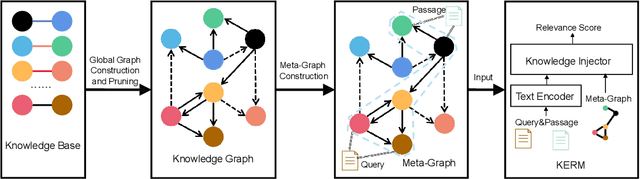

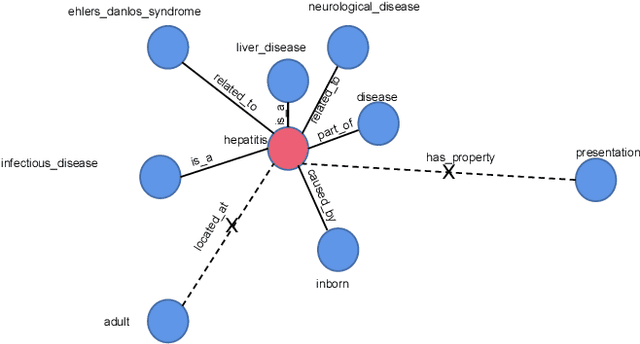
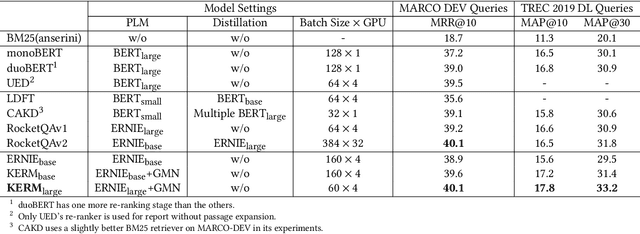
Passage re-ranking is to obtain a permutation over the candidate passage set from retrieval stage. Re-rankers have been boomed by Pre-trained Language Models (PLMs) due to their overwhelming advantages in natural language understanding. However, existing PLM based re-rankers may easily suffer from vocabulary mismatch and lack of domain specific knowledge. To alleviate these problems, explicit knowledge contained in knowledge graph is carefully introduced in our work. Specifically, we employ the existing knowledge graph which is incomplete and noisy, and first apply it in passage re-ranking task. To leverage a reliable knowledge, we propose a novel knowledge graph distillation method and obtain a knowledge meta graph as the bridge between query and passage. To align both kinds of embedding in the latent space, we employ PLM as text encoder and graph neural network over knowledge meta graph as knowledge encoder. Besides, a novel knowledge injector is designed for the dynamic interaction between text and knowledge encoder. Experimental results demonstrate the effectiveness of our method especially in queries requiring in-depth domain knowledge.
Graph Enhanced BERT for Query Understanding
Apr 03, 2022
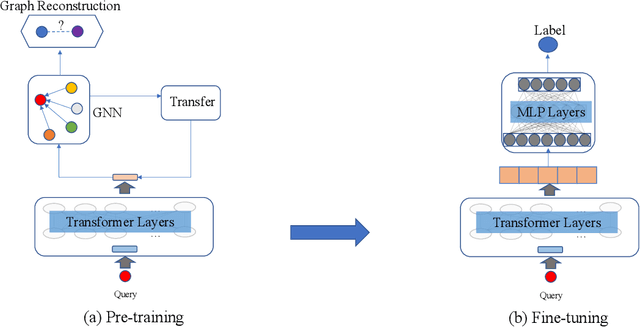
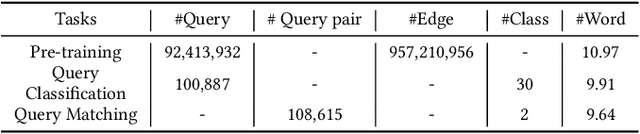
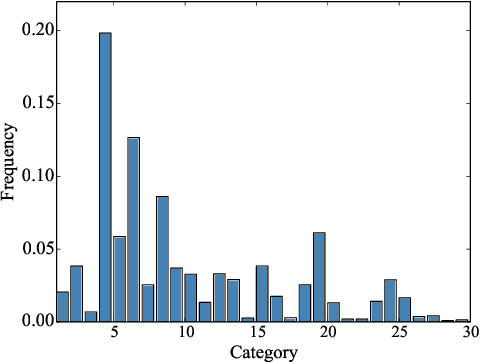
Query understanding plays a key role in exploring users' search intents and facilitating users to locate their most desired information. However, it is inherently challenging since it needs to capture semantic information from short and ambiguous queries and often requires massive task-specific labeled data. In recent years, pre-trained language models (PLMs) have advanced various natural language processing tasks because they can extract general semantic information from large-scale corpora. Therefore, there are unprecedented opportunities to adopt PLMs for query understanding. However, there is a gap between the goal of query understanding and existing pre-training strategies -- the goal of query understanding is to boost search performance while existing strategies rarely consider this goal. Thus, directly applying them to query understanding is sub-optimal. On the other hand, search logs contain user clicks between queries and urls that provide rich users' search behavioral information on queries beyond their content. Therefore, in this paper, we aim to fill this gap by exploring search logs. In particular, to incorporate search logs into pre-training, we first construct a query graph where nodes are queries and two queries are connected if they lead to clicks on the same urls. Then we propose a novel graph-enhanced pre-training framework, GE-BERT, which can leverage both query content and the query graph. In other words, GE-BERT can capture both the semantic information and the users' search behavioral information of queries. Extensive experiments on various query understanding tasks have demonstrated the effectiveness of the proposed framework.