 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximated Doubly Robust Search Relevance Estimation
Aug 16, 2022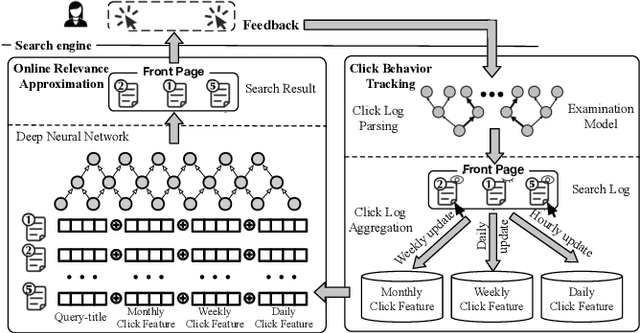
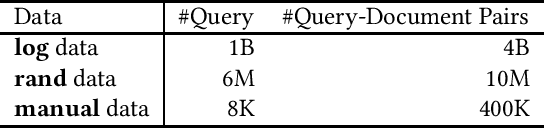
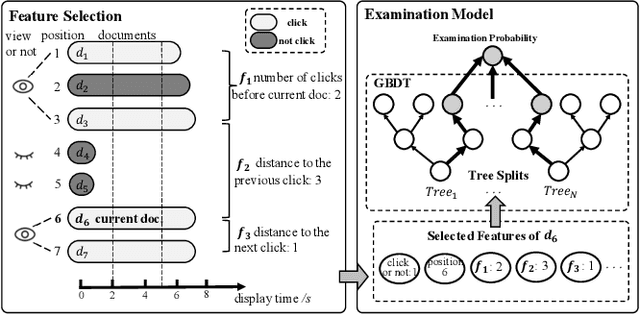
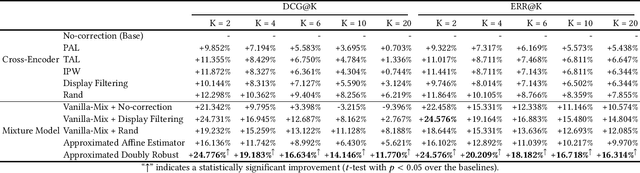
Extracting query-document relevance from the sparse, biased clickthrough log is among the most fundamental tasks in the web search system. Prior art mainly learns a relevance judgment model with semantic features of the query and document and ignores directly counterfactual relevance evaluation from the clicking log. Though the learned semantic matching models can provide relevance signals for tail queries as long as the semantic feature is available. However, such a paradigm lacks the capability to introspectively adjust the biased relevance estimation whenever it conflicts with massive implicit user feedback. The counterfactual evaluation methods, on the contrary, ensure unbiased relevance estimation with sufficient click information. However, they suffer from the sparse or even missing clicks caused by the long-tailed query distribution. In this paper, we propose to unify the counterfactual evaluating and learning approaches for unbiased relevance estimation on search queries with various popularities. Specifically, we theoretically develop a doubly robust estimator with low bias and variance, which intentionally combines the benefits of existing relevance evaluating and learning approaches. We further instantiate the proposed unbiased relevance estimation framework in Baidu search, with comprehensive practical solutions designed regarding the data pipeline for click behavior tracking and online relevance estimation with an approximated deep neural network. Finally, we present extensive empirical evaluations to verify the effectiveness of our proposed framework, finding that it is robust in practice and manages to improve online ranking performance substantially.
* 10 pages
A Large Scale Search Dataset for Unbiased Learning to Rank
Jul 07, 2022

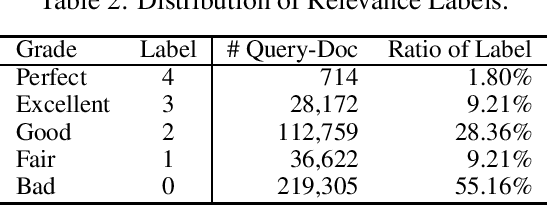

The unbiased learning to rank (ULTR) problem has been greatly advanced by recent deep learning techniques and well-designed debias algorithms. However, promising results on the existing benchmark datasets may not be extended to the practical scenario due to the following disadvantages observed from those popular benchmark datasets: (1) outdated semantic feature extraction where state-of-the-art large scale pre-trained language models like BERT cannot be exploited due to the missing of the original text;(2) incomplete display features for in-depth study of ULTR, e.g., missing the displayed abstract of documents for analyzing the click necessary bias; (3) lacking real-world user feedback, leading to the prevalence of synthetic datasets in the empirical study. To overcome the above disadvantages, we introduce the Baidu-ULTR dataset. It involves randomly sampled 1.2 billion searching sessions and 7,008 expert annotated queries, which is orders of magnitude larger than the existing ones. Baidu-ULTR provides:(1) the original semantic feature and a pre-trained language model for easy usage; (2) sufficient display information such as position, displayed height, and displayed abstract, enabling the comprehensive study of different biases with advanced techniques such as causal discovery and meta-learning; and (3) rich user feedback on search result pages (SERPs) like dwelling time, allowing for user engagement optimization and promoting the exploration of multi-task learning in ULTR. In this paper, we present the design principle of Baidu-ULTR and the performance of benchmark ULTR algorithms on this new data resource, favoring the exploration of ranking for long-tail queries and pre-training tasks for ranking. The Baidu-ULTR dataset and corresponding baseline implementation are available at https://github.com/ChuXiaokai/baidu_ultr_dataset.
Deep Random Forest with Ferroelectric Analog Content Addressable Memory
Oct 06, 2021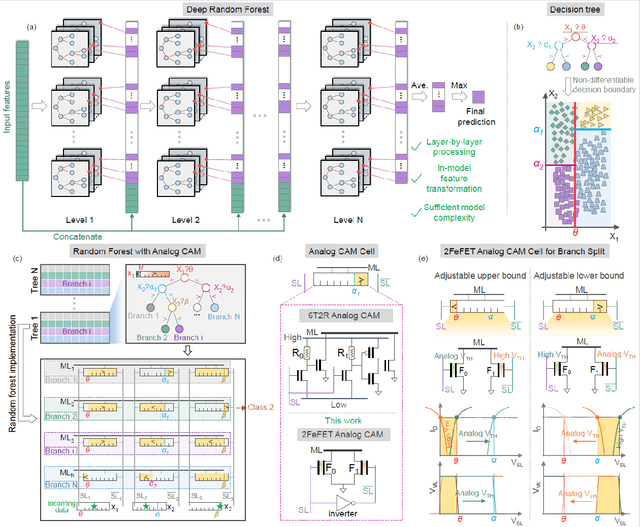
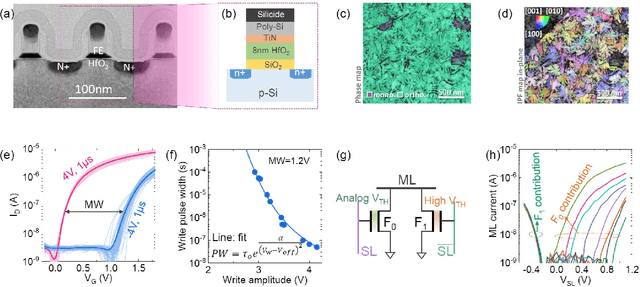
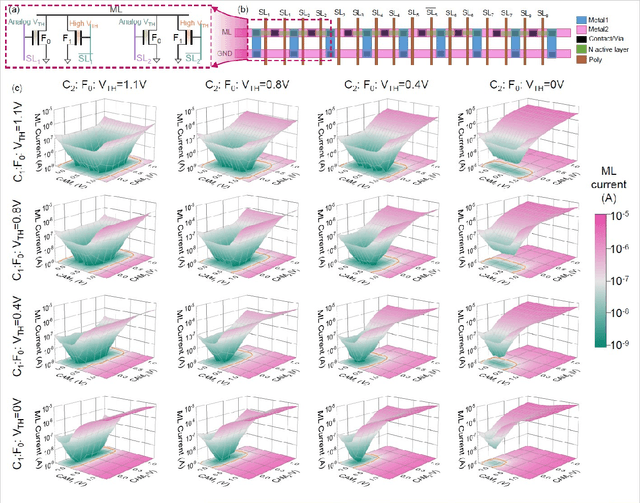
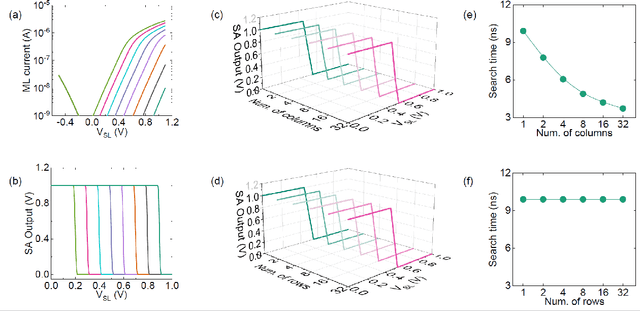
Deep random forest (DRF), which incorporates the core features of deep learning and random forest (RF), exhibits comparable classification accuracy, interpretability, and low memory and computational overhead when compared with deep neural networks (DNNs) in various information processing tasks for edge intelligence. However, the development of efficient hardware to accelerate DRF is lagging behind its DNN counterparts. The key for hardware acceleration of DRF lies in efficiently realizing the branch-split operation at decision nodes when traversing a decision tree. In this work, we propose to implement DRF through simple associative searches realized with ferroelectric analog content addressable memory (ACAM). Utilizing only two ferroelectric field effect transistors (FeFETs), the ultra-compact ACAM cell can perform a branch-split operation with an energy-efficient associative search by storing the decision boundaries as the analog polarization states in an FeFET. The DRF accelerator architecture and the corresponding mapping of the DRF model to the ACAM arrays are presented. The functionality, characteristics, and scalability of the FeFET ACAM based DRF and its robustness against FeFET device non-idealities are validated both in experiments and simulations. Evaluation results show that the FeFET ACAM DRF accelerator exhibits 10^6x/16x and 10^6x/2.5x improvements in terms of energy and latency when compared with other deep random forest hardware implementations on the state-of-the-art CPU/ReRAM, respectively.
Enhanced Doubly Robust Learning for Debiasing Post-click Conversion Rate Estimation
May 28, 2021
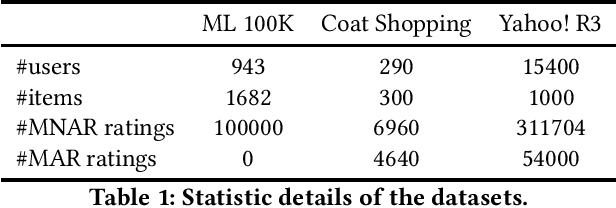
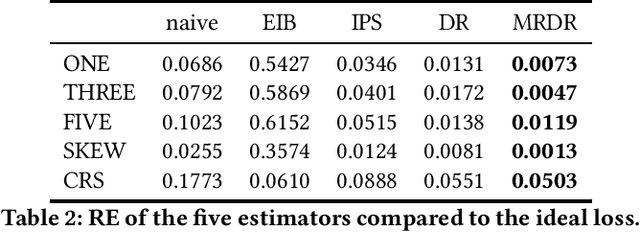

Post-click conversion, as a strong signal indicating the user preference, is salutary for building recommender systems. However, accurately estimating the post-click conversion rate (CVR) is challenging due to the selection bias, i.e., the observed clicked events usually happen on users' preferred items. Currently, most existing methods utilize counterfactual learning to debias recommender systems. Among them, the doubly robust (DR) estimator has achieved competitive performance by combining the error imputation based (EIB) estimator and the inverse propensity score (IPS) estimator in a doubly robust way. However, inaccurate error imputation may result in its higher variance than the IPS estimator. Worse still, existing methods typically use simple model-agnostic methods to estimate the imputation error, which are not sufficient to approximate the dynamically changing model-correlated target (i.e., the gradient direction of the prediction model). To solve these problems, we first derive the bias and variance of the DR estimator. Based on it, a more robust doubly robust (MRDR) estimator has been proposed to further reduce its variance while retaining its double robustness. Moreover, we propose a novel double learning approach for the MRDR estimator, which can convert the error imputation into the general CVR estimation. Besides, we empirically verify that the proposed learning scheme can further eliminate the high variance problem of the imputation learning. To evaluate its effectiveness, extensive experiments are conducted on a semi-synthetic dataset and two real-world datasets. The results demonstrate the superiority of the proposed approach over the state-of-the-art methods. The code is available at https://github.com/guosyjlu/MRDR-DL.