 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Regularized Generative Auto-Bidding: From Suboptimal Trajectories to Optimal Policies
Jan 06, 2026With the rapid development of e-commerce, auto-bidding has become a key asset in optimizing advertising performance under diverse advertiser environments. The current approaches focus on reinforcement learning (RL) and generative models. These efforts imitate offline historical behaviors by utilizing a complex structure with expensive hyperparameter tuning. The suboptimal trajectories further exacerbate the difficulty of policy learning. To address these challenges, we proposes QGA, a novel Q-value regularized Generative Auto-bidding method. In QGA, we propose to plug a Q-value regularization with double Q-learning strategy into the Decision Transformer backbone. This design enables joint optimization of policy imitation and action-value maximization, allowing the learned bidding policy to both leverage experience from the dataset and alleviate the adverse impact of the suboptimal trajectories. Furthermore, to safely explore the policy space beyond the data distribution, we propose a Q-value guided dual-exploration mechanism, in which the DT model is conditioned on multiple return-to-go targets and locally perturbed actions. This entire exploration process is dynamically guided by the aforementioned Q-value module, which provides principled evaluation for each candidate action. Experiments on public benchmarks and simulation environments demonstrate that QGA consistently achieves superior or highly competitive results compared to existing alternatives. Notably, in large-scale real-world A/B testing, QGA achieves a 3.27% increase in Ad GMV and a 2.49% improvement in Ad ROI.
LFD: Layer Fused Decoding to Exploit External Knowledge in Retrieval-Augmented Generation
Aug 27, 2025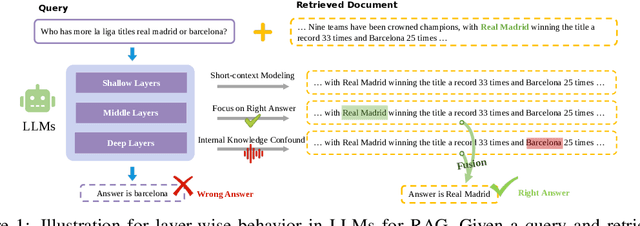
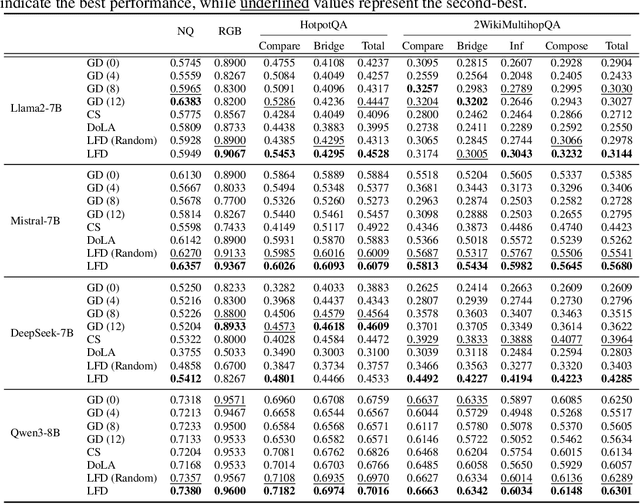
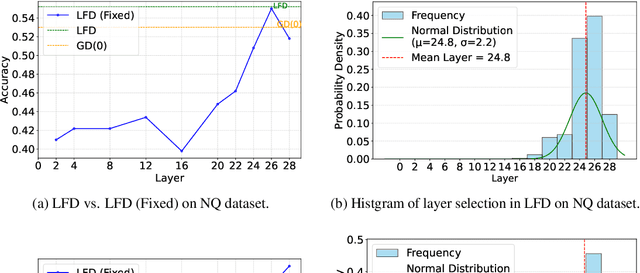

Retrieval-augmented generation (RAG) incorporates external knowledge into large language models (LLMs), improving their adaptability to downstream tasks and enabling information updates. Surprisingly, recent empirical evidence demonstrates that injecting noise into retrieved relevant documents paradoxically facilitates exploitation of external knowledge and improves generation quality. Although counterintuitive and challenging to apply in practice, this phenomenon enables granular control and rigorous analysis of how LLMs integrate external knowledge. Therefore, in this paper, we intervene on noise injection and establish a layer-specific functional demarcation within the LLM: shallow layers specialize in local context modeling, intermediate layers focus on integrating long-range external factual knowledge, and deeper layers primarily rely on parametric internal knowledge. Building on this insight, we propose Layer Fused Decoding (LFD), a simple decoding strategy that directly combines representations from an intermediate layer with final-layer decoding outputs to fully exploit the external factual knowledge. To identify the optimal intermediate layer, we introduce an internal knowledge score (IKS) criterion that selects the layer with the lowest IKS value in the latter half of layers. Experimental results across multiple benchmarks demonstrate that LFD helps RAG systems more effectively surface retrieved context knowledge with minimal cost.
Multi-Interest Recommendation: A Survey
Jun 18, 2025Existing recommendation methods often struggle to model users' multifaceted preferences due to the diversity and volatility of user behavior, as well as the inherent uncertainty and ambiguity of item attributes in practical scenarios. Multi-interest recommendation addresses this challenge by extracting multiple interest representations from users' historical interactions, enabling fine-grained preference modeling and more accurate recommendations. It has drawn broad interest in recommendation research. However, current recommendation surveys have either specialized in frontier recommendation methods or delved into specific tasks and downstream applications. In this work, we systematically review the progress, solutions, challenges, and future directions of multi-interest recommendation by answering the following three questions: (1) Why is multi-interest modeling significantly important for recommendation? (2) What aspects are focused on by multi-interest modeling in recommendation? and (3) How can multi-interest modeling be applied, along with the technical details of the representative modules? We hope that this survey establishes a fundamental framework and delivers a preliminary overview for researchers interested in this field and committed to further exploration. The implementation of multi-interest recommendation summarized in this survey is maintained at https://github.com/WHUIR/Multi-Interest-Recommendation-A-Survey.
Flow Matching based Sequential Recommender Model
May 22, 2025Generative models, particularly diffusion model, have emerged as powerful tools for sequential recommendation. However, accurately modeling user preferences remains challenging due to the noise perturbations inherent in the forward and reverse processes of diffusion-based methods. Towards this end, this study introduces FMRec, a Flow Matching based model that employs a straight flow trajectory and a modified loss tailored for the recommendation task. Additionally, from the diffusion-model perspective, we integrate a reconstruction loss to improve robustness against noise perturbations, thereby retaining user preferences during the forward process. In the reverse process, we employ a deterministic reverse sampler, specifically an ODE-based updating function, to eliminate unnecessary randomness, thereby ensuring that the generated recommendations closely align with user needs. Extensive evaluations on four benchmark datasets reveal that FMRec achieves an average improvement of 6.53% over state-of-the-art methods. The replication code is available at https://github.com/FengLiu-1/FMRec.
Who You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
May 16, 2025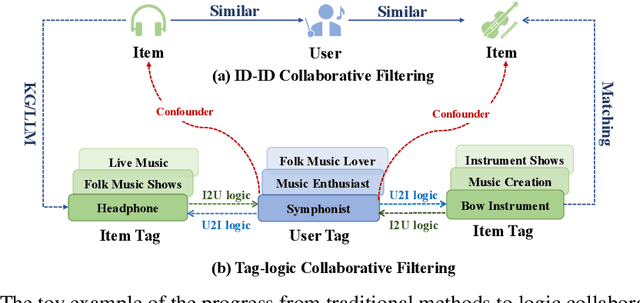
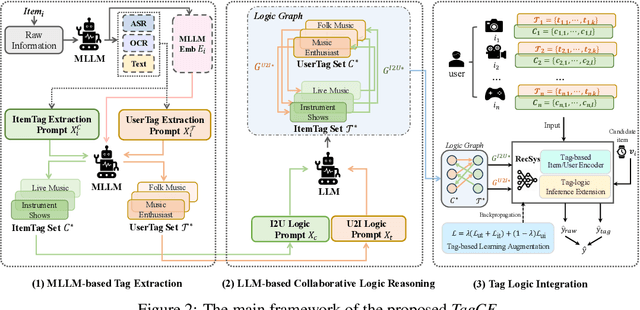
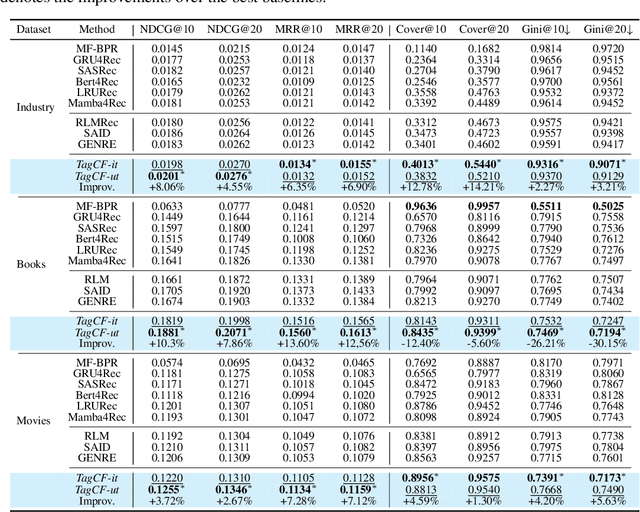
Recommender systems filter contents/items valuable to users by inferring preferences from user features and historical behaviors. Mainstream approaches follow the learning-to-rank paradigm, which focus on discovering and modeling item topics (e.g., categories), and capturing user preferences on these topics based on historical interactions. However, this paradigm often neglects the modeling of user characteristics and their social roles, which are logical confounders influencing the correlated interest and user preference transition. To bridge this gap, we introduce the user role identification task and the behavioral logic modeling task that aim to explicitly model user roles and learn the logical relations between item topics and user social roles. We show that it is possible to explicitly solve these tasks through an efficient integration framework of Large Language Model (LLM) and recommendation systems, for which we propose TagCF. On the one hand, the exploitation of the LLM's world knowledge and logic inference ability produces a virtual logic graph that reveals dynamic and expressive knowledge of users, augmenting the recommendation performance. On the other hand, the user role aligns the user behavioral logic with the observed user feedback, refining our understanding of user behaviors. Additionally, we also show that the extracted user-item logic graph is empirically a general knowledge that can benefit a wide range of recommendation tasks, and conduct experiments on industrial and several public datasets as verification.
Efficient and Robust Regularized Federated Recommendation
Nov 03, 2024



Recommender systems play a pivotal role across practical scenarios, showcasing remarkable capabilities in user preference modeling. However, the centralized learning paradigm predominantly used raises serious privacy concerns. The federated recommender system (FedRS) addresses this by updating models on clients, while a central server orchestrates training without accessing private data. Existing FedRS approaches, however, face unresolved challenges, including non-convex optimization, vulnerability, potential privacy leakage risk, and communication inefficiency. This paper addresses these challenges by reformulating the federated recommendation problem as a convex optimization issue, ensuring convergence to the global optimum. Based on this, we devise a novel method, RFRec, to tackle this optimization problem efficiently. In addition, we propose RFRecF, a highly efficient version that incorporates non-uniform stochastic gradient descent to improve communication efficiency. In user preference modeling, both methods learn local and global models, collaboratively learning users' common and personalized interests under the federated learning setting. Moreover, both methods significantly enhance communication efficiency, robustness, and privacy protection, with theoretical support. Comprehensive evaluations on four benchmark datasets demonstrate RFRec and RFRecF's superior performance compared to diverse baselines.
Efficient Sparse Attention needs Adaptive Token Release
Jul 02, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide array of text-centric tasks. However, their `large' scale introduces significant computational and storage challenges, particularly in managing the key-value states of the transformer, which limits their wider applicability. Therefore, we propose to adaptively release resources from caches and rebuild the necessary key-value states. Particularly, we accomplish this by a lightweight controller module to approximate an ideal top-$K$ sparse attention. This module retains the tokens with the highest top-$K$ attention weights and simultaneously rebuilds the discarded but necessary tokens, which may become essential for future decoding. Comprehensive experiments in natural language generation and modeling reveal that our method is not only competitive with full attention in terms of performance but also achieves a significant throughput improvement of up to 221.8%. The code for replication is available on the https://github.com/WHUIR/ADORE.
Evolutionary Reinforcement Learning: A Systematic Review and Future Directions
Feb 20, 2024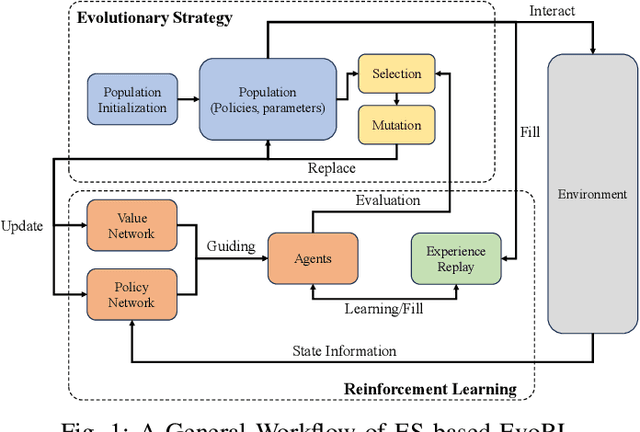

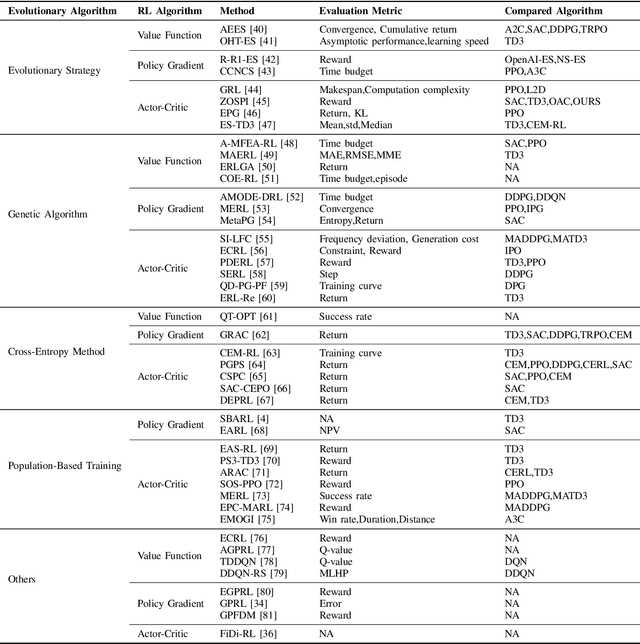

In response to the limitations of reinforcement learning and evolutionary algorithms (EAs) in complex problem-solving, Evolutionary Reinforcement Learning (EvoRL) has emerged as a synergistic solution. EvoRL integrates EAs and reinforcement learning, presenting a promising avenue for training intelligent agents. This systematic review firstly navigates through the technological background of EvoRL, examining the symbiotic relationship between EAs and reinforcement learning algorithms. We then delve into the challenges faced by both EAs and reinforcement learning, exploring their interplay and impact on the efficacy of EvoRL. Furthermore, the review underscores the need for addressing open issues related to scalability, adaptability, sample efficiency, adversarial robustness, ethic and fairness within the current landscape of EvoRL. Finally, we propose future directions for EvoRL, emphasizing research avenues that strive to enhance self-adaptation and self-improvement, generalization, interpretability, explainability, and so on. Serving as a comprehensive resource for researchers and practitioners, this systematic review provides insights into the current state of EvoRL and offers a guide for advancing its capabilities in the ever-evolving landscape of artificial intelligence.
Unconfounded Propensity Estimation for Unbiased Ranking
May 18, 2023The goal of unbiased learning to rank (ULTR) is to leverage implicit user feedback for optimizing learning-to-rank systems. Among existing solutions, automatic ULTR algorithms that jointly learn user bias models (i.e., propensity models) with unbiased rankers have received a lot of attention due to their superior performance and low deployment cost in practice. Despite their theoretical soundness, the effectiveness is usually justified under a weak logging policy, where the ranking model can barely rank documents according to their relevance to the query. However, when the logging policy is strong, e.g., an industry-deployed ranking policy, the reported effectiveness cannot be reproduced. In this paper, we first investigate ULTR from a causal perspective and uncover a negative result: existing ULTR algorithms fail to address the issue of propensity overestimation caused by the query-document relevance confounder. Then, we propose a new learning objective based on backdoor adjustment and highlight its differences from conventional propensity models, which reveal the prevalence of propensity overestimation. On top of that, we introduce a novel propensity model called Logging-Policy-aware Propensity (LPP) model and its distinctive two-step optimization strategy, which allows for the joint learning of LPP and ranking models within the automatic ULTR framework, and actualize the unconfounded propensity estimation for ULTR. Extensive experiments on two benchmarks demonstrate the effectiveness and generalizability of the proposed method.
User Retention-oriented Recommendation with Decision Transformer
Mar 11, 2023



Improving user retention with reinforcement learning~(RL) has attracted increasing attention due to its significant importance in boosting user engagement. However, training the RL policy from scratch without hurting users' experience is unavoidable due to the requirement of trial-and-error searches. Furthermore, the offline methods, which aim to optimize the policy without online interactions, suffer from the notorious stability problem in value estimation or unbounded variance in counterfactual policy evaluation. To this end, we propose optimizing user retention with Decision Transformer~(DT), which avoids the offline difficulty by translating the RL as an autoregressive problem. However, deploying the DT in recommendation is a non-trivial problem because of the following challenges: (1) deficiency in modeling the numerical reward value; (2) data discrepancy between the policy learning and recommendation generation; (3) unreliable offline performance evaluation. In this work, we, therefore, contribute a series of strategies for tackling the exposed issues. We first articulate an efficient reward prompt by weighted aggregation of meta embeddings for informative reward embedding. Then, we endow a weighted contrastive learning method to solve the discrepancy between training and inference. Furthermore, we design two robust offline metrics to measure user retention. Finally, the significant improvement in the benchmark datasets demonstrates the superiority of the proposed method.