 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA4DIV: Multi-Agent Reinforcement Learning for Search Result Diversification
Mar 27, 2024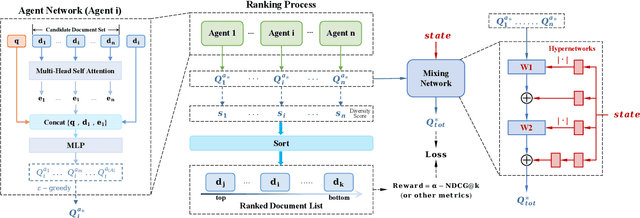

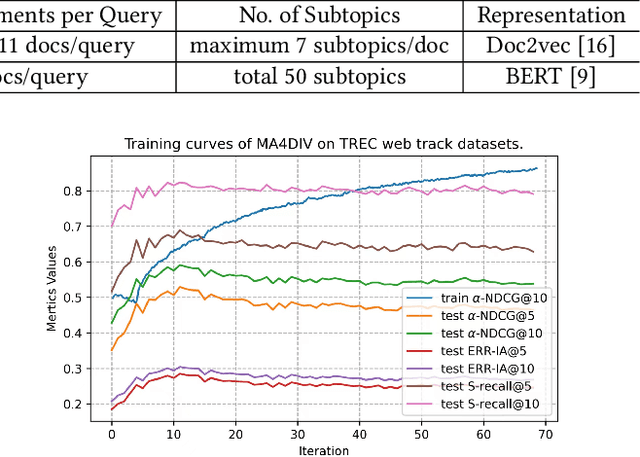
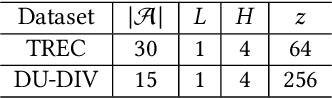
The objective of search result diversification (SRD) is to ensure that selected documents cover as many different subtopics as possible. Existing methods primarily utilize a paradigm of "greedy selection", i.e., selecting one document with the highest diversity score at a time. These approaches tend to be inefficient and are easily trapped in a suboptimal state. In addition, some other methods aim to approximately optimize the diversity metric, such as $\alpha$-NDCG, but the results still remain suboptimal. To address these challenges, we introduce Multi-Agent reinforcement learning (MARL) for search result DIVersity, which called MA4DIV. In this approach, each document is an agent and the search result diversification is modeled as a cooperative task among multiple agents. This approach allows for directly optimizing the diversity metrics, such as $\alpha$-NDCG, while achieving high training efficiency. We conducted preliminary experiments on public TREC datasets to demonstrate the effectiveness and potential of MA4DIV. Considering the limited number of queries in public TREC datasets, we construct a large-scale dataset from industry sources and show that MA4DIV achieves substantial improvements in both effectiveness and efficiency than existing baselines on a industrial scale dataset.
Improving the Robustness of Large Language Models via Consistency Alignment
Mar 22, 2024



Large language models (LLMs) have shown tremendous success in following user instructions and generating helpful responses. Nevertheless, their robustness is still far from optimal, as they may generate significantly inconsistent responses due to minor changes in the verbalized instructions. Recent literature has explored this inconsistency issue, highlighting the importance of continued improvement in the robustness of response generation. However, systematic analysis and solutions are still lacking. In this paper, we quantitatively define the inconsistency problem and propose a two-stage training framework consisting of instruction-augmented supervised fine-tuning and consistency alignment training. The first stage helps a model generalize on following instructions via similar instruction augmentations. In the second stage, we improve the diversity and help the model understand which responses are more aligned with human expectations by differentiating subtle differences in similar responses. The training process is accomplished by self-rewards inferred from the trained model at the first stage without referring to external human preference resources. We conduct extensive experiments on recent publicly available LLMs on instruction-following tasks and demonstrate the effectiveness of our training framework.
Knowing What LLMs DO NOT Know: A Simple Yet Effective Self-Detection Method
Oct 27, 2023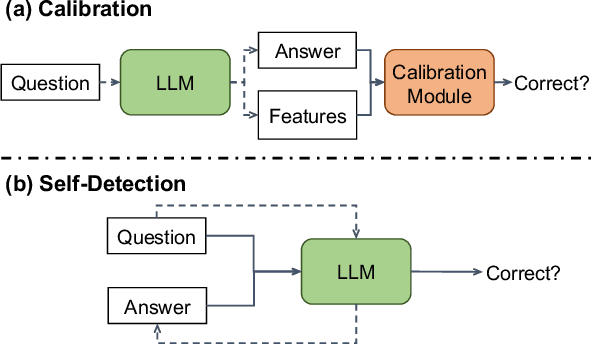
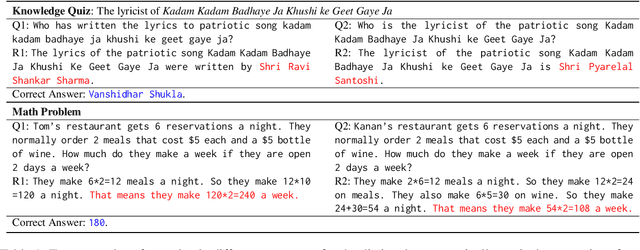
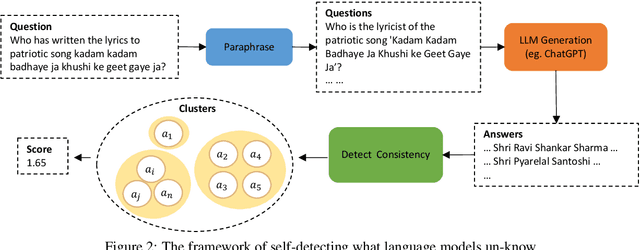

Large Language Models (LLMs) have shown great potential in Natural Language Processing (NLP) tasks. However, recent literature reveals that LLMs generate nonfactual responses intermittently, which impedes the LLMs' reliability for further utilization. In this paper, we propose a novel self-detection method to detect which questions that a LLM does not know that are prone to generate nonfactual results. Specifically, we first diversify the textual expressions for a given question and collect the corresponding answers. Then we examine the divergencies between the generated answers to identify the questions that the model may generate falsehoods. All of the above steps can be accomplished by prompting the LLMs themselves without referring to any other external resources. We conduct comprehensive experiments and demonstrate the effectiveness of our method on recently released LLMs, e.g., Vicuna, ChatGPT, and GPT-4.
DiQAD: A Benchmark Dataset for End-to-End Open-domain Dialogue Assessment
Oct 25, 2023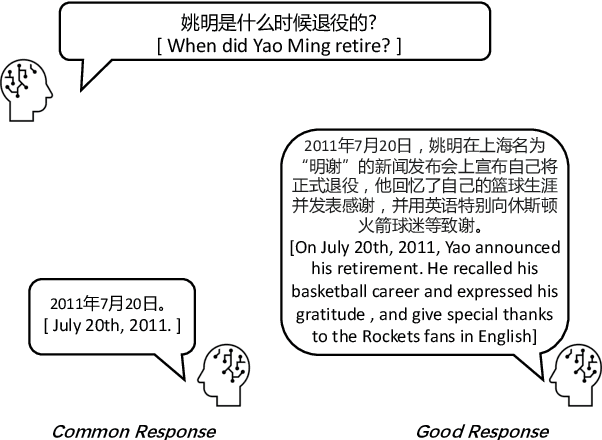
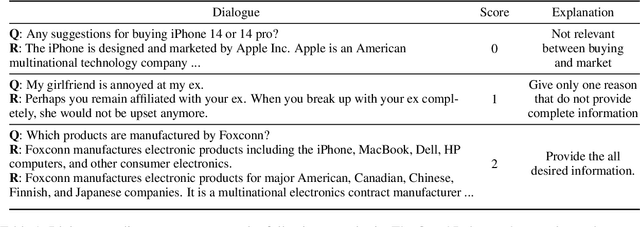
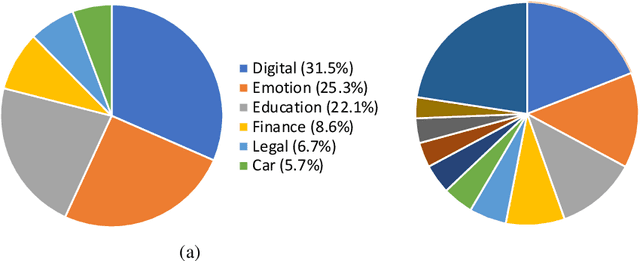
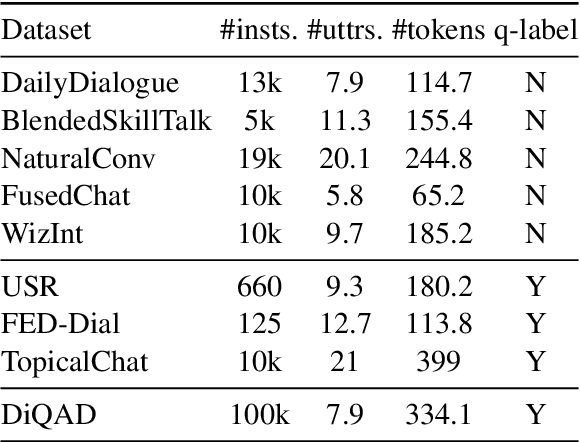
Dialogue assessment plays a critical role in the development of open-domain dialogue systems. Existing work are uncapable of providing an end-to-end and human-epistemic assessment dataset, while they only provide sub-metrics like coherence or the dialogues are conversed between annotators far from real user settings. In this paper, we release a large-scale dialogue quality assessment dataset (DiQAD), for automatically assessing open-domain dialogue quality. Specifically, we (1) establish the assessment criteria based on the dimensions conforming to human judgements on dialogue qualities, and (2) annotate large-scale dialogues that conversed between real users based on these annotation criteria, which contains around 100,000 dialogues. We conduct several experiments and report the performances of the baselines as the benchmark on DiQAD. The dataset is openly accessible at https://github.com/yukunZhao/Dataset_Dialogue_quality_evaluation.
Pretrained Language Model based Web Search Ranking: From Relevance to Satisfaction
Jun 02, 2023



Search engine plays a crucial role in satisfying users' diverse information needs. Recently, Pretrained Language Models (PLMs) based text ranking models have achieved huge success in web search. However, many state-of-the-art text ranking approaches only focus on core relevance while ignoring other dimensions that contribute to user satisfaction, e.g., document quality, recency, authority, etc. In this work, we focus on ranking user satisfaction rather than relevance in web search, and propose a PLM-based framework, namely SAT-Ranker, which comprehensively models different dimensions of user satisfaction in a unified manner. In particular, we leverage the capacities of PLMs on both textual and numerical inputs, and apply a multi-field input that modularizes each dimension of user satisfaction as an input field. Overall, SAT-Ranker is an effective, extensible, and data-centric framework that has huge potential for industrial applications. On rigorous offline and online experiments, SAT-Ranker obtains remarkable gains on various evaluation sets targeting different dimensions of user satisfaction. It is now fully deployed online to improve the usability of our search engine.
Layout-aware Webpage Quality Assessment
Feb 05, 2023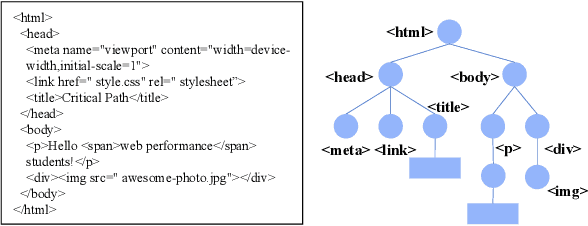

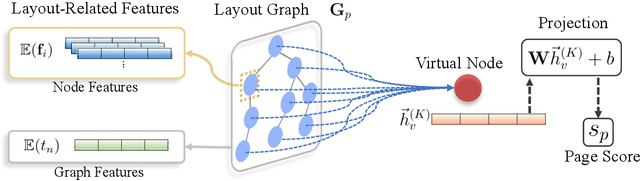
Identifying high-quality webpages is fundamental for real-world search engines, which can fulfil users' information need with the less cognitive burden. Early studies of \emph{webpage quality assessment} usually design hand-crafted features that may only work on particular categories of webpages (e.g., shopping websites, medical websites). They can hardly be applied to real-world search engines that serve trillions of webpages with various types and purposes. In this paper, we propose a novel layout-aware webpage quality assessment model currently deployed in our search engine. Intuitively, layout is a universal and critical dimension for the quality assessment of different categories of webpages. Based on this, we directly employ the meta-data that describes a webpage, i.e., Document Object Model (DOM) tree, as the input of our model. The DOM tree data unifies the representation of webpages with different categories and purposes and indicates the layout of webpages. To assess webpage quality from complex DOM tree data, we propose a graph neural network (GNN) based method that extracts rich layout-aware information that implies webpage quality in an end-to-end manner. Moreover, we improve the GNN method with an attentive readout function, external web categories and a category-aware sampling method. We conduct rigorous offline and online experiments to show that our proposed solution is effective in real search engines, improving the overall usability and user experience.
PILE: Pairwise Iterative Logits Ensemble for Multi-Teacher Labeled Distillation
Nov 11, 2022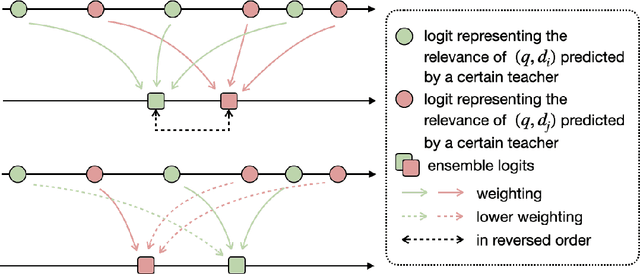
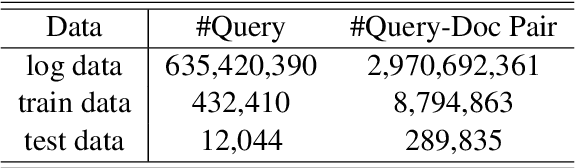

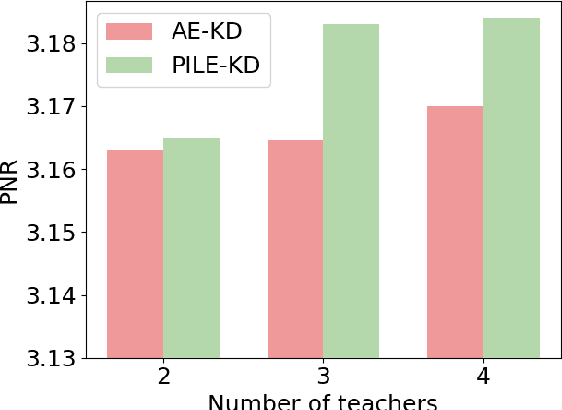
Pre-trained language models have become a crucial part of ranking systems and achieved very impressive effects recently. To maintain high performance while keeping efficient computations, knowledge distillation is widely used. In this paper, we focus on two key questions in knowledge distillation for ranking models: 1) how to ensemble knowledge from multi-teacher; 2) how to utilize the label information of data in the distillation process. We propose a unified algorithm called Pairwise Iterative Logits Ensemble (PILE) to tackle these two questions simultaneously. PILE ensembles multi-teacher logits supervised by label information in an iterative way and achieved competitive performance in both offline and online experiments. The proposed method has been deployed in a real-world commercial search system.
Approximated Doubly Robust Search Relevance Estimation
Aug 16, 2022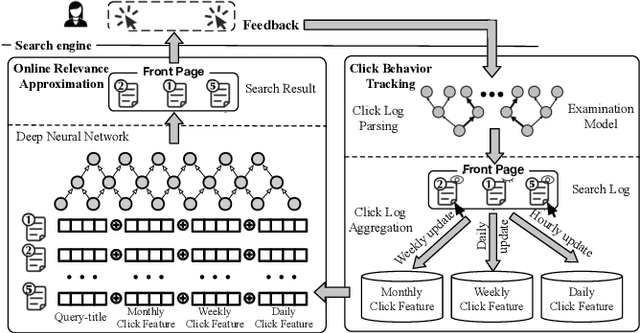
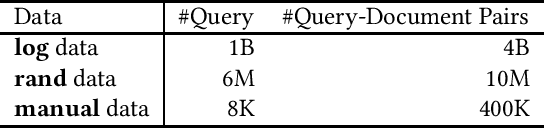
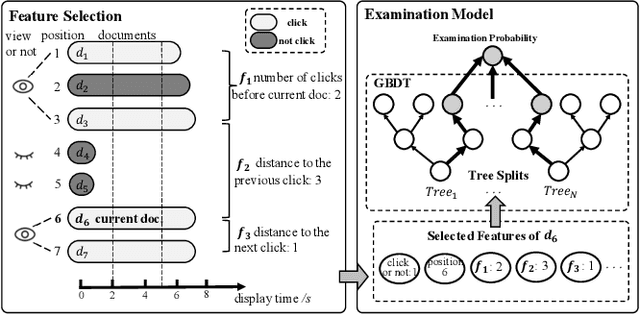
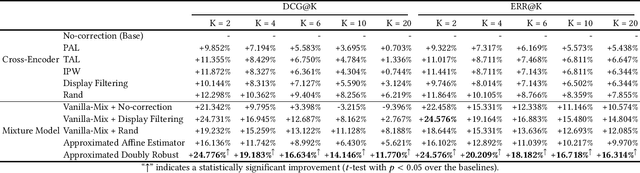
Extracting query-document relevance from the sparse, biased clickthrough log is among the most fundamental tasks in the web search system. Prior art mainly learns a relevance judgment model with semantic features of the query and document and ignores directly counterfactual relevance evaluation from the clicking log. Though the learned semantic matching models can provide relevance signals for tail queries as long as the semantic feature is available. However, such a paradigm lacks the capability to introspectively adjust the biased relevance estimation whenever it conflicts with massive implicit user feedback. The counterfactual evaluation methods, on the contrary, ensure unbiased relevance estimation with sufficient click information. However, they suffer from the sparse or even missing clicks caused by the long-tailed query distribution. In this paper, we propose to unify the counterfactual evaluating and learning approaches for unbiased relevance estimation on search queries with various popularities. Specifically, we theoretically develop a doubly robust estimator with low bias and variance, which intentionally combines the benefits of existing relevance evaluating and learning approaches. We further instantiate the proposed unbiased relevance estimation framework in Baidu search, with comprehensive practical solutions designed regarding the data pipeline for click behavior tracking and online relevance estimation with an approximated deep neural network. Finally, we present extensive empirical evaluations to verify the effectiveness of our proposed framework, finding that it is robust in practice and manages to improve online ranking performance substantially.
* 10 pages
Practical Strategies of Active Learning to Rank for Web Search
May 20, 2022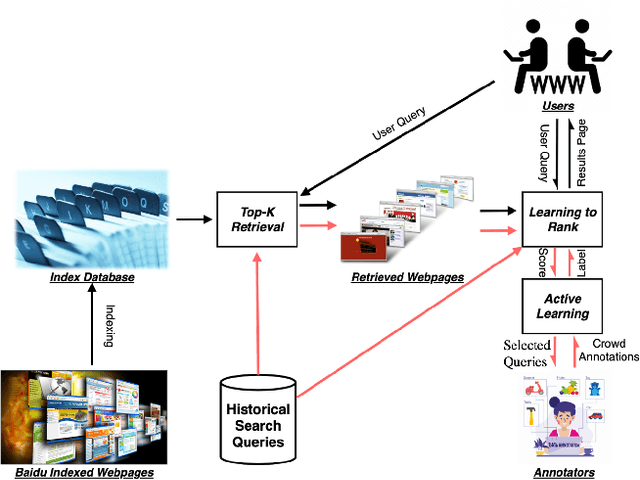
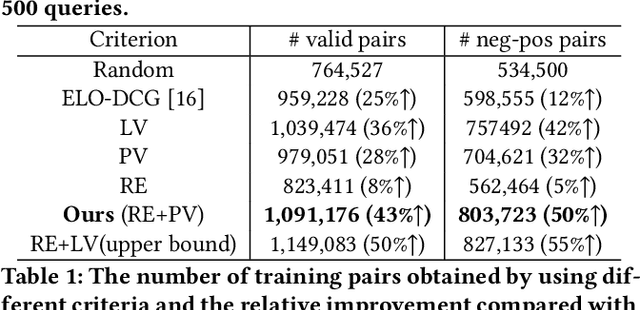
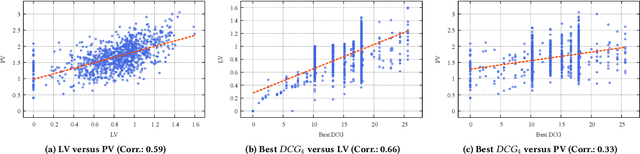
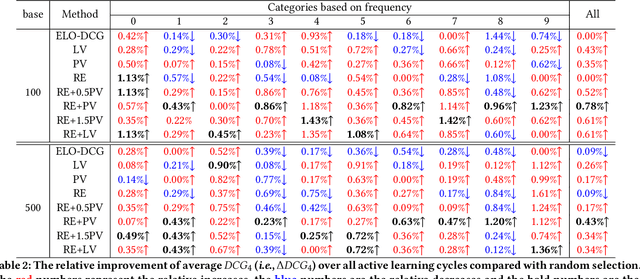
While China has become the biggest online market in the world with around 1 billion internet users, Baidu runs the world largest Chinese search engine serving more than hundreds of millions of daily active users and responding billions queries per day. To handle the diverse query requests from users at web-scale, Baidu has done tremendous efforts in understanding users' queries, retrieve relevant contents from a pool of trillions of webpages, and rank the most relevant webpages on the top of results. Among these components used in Baidu search, learning to rank (LTR) plays a critical role and we need to timely label an extremely large number of queries together with relevant webpages to train and update the online LTR models. To reduce the costs and time consumption of queries/webpages labeling, we study the problem of Activ Learning to Rank (active LTR) that selects unlabeled queries for annotation and training in this work. Specifically, we first investigate the criterion -- Ranking Entropy (RE) characterizing the entropy of relevant webpages under a query produced by a sequence of online LTR models updated by different checkpoints, using a Query-By-Committee (QBC) method. Then, we explore a new criterion namely Prediction Variances (PV) that measures the variance of prediction results for all relevant webpages under a query. Our empirical studies find that RE may favor low-frequency queries from the pool for labeling while PV prioritizing high-frequency queries more. Finally, we combine these two complementary criteria as the sample selection strategies for active learning. Extensive experiments with comparisons to baseline algorithms show that the proposed approach could train LTR models achieving higher Discounted Cumulative Gain (i.e., the relative improvement {\Delta}DCG4=1.38%) with the same budgeted labeling efforts.
Incorporating Explicit Knowledge in Pre-trained Language Models for Passage Re-ranking
Apr 25, 2022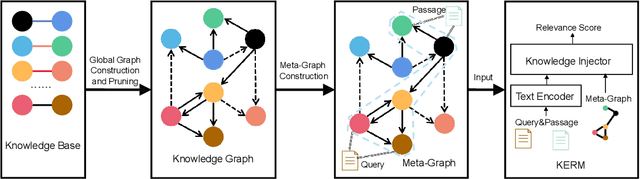

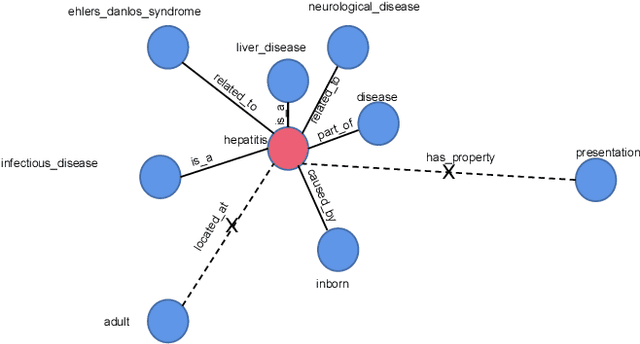
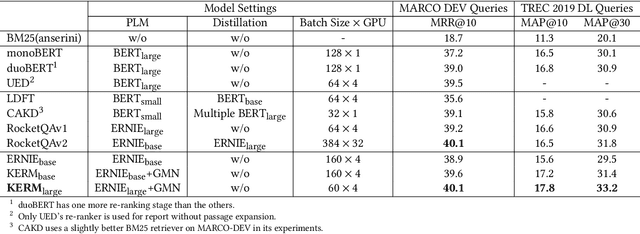
Passage re-ranking is to obtain a permutation over the candidate passage set from retrieval stage. Re-rankers have been boomed by Pre-trained Language Models (PLMs) due to their overwhelming advantages in natural language understanding. However, existing PLM based re-rankers may easily suffer from vocabulary mismatch and lack of domain specific knowledge. To alleviate these problems, explicit knowledge contained in knowledge graph is carefully introduced in our work. Specifically, we employ the existing knowledge graph which is incomplete and noisy, and first apply it in passage re-ranking task. To leverage a reliable knowledge, we propose a novel knowledge graph distillation method and obtain a knowledge meta graph as the bridge between query and passage. To align both kinds of embedding in the latent space, we employ PLM as text encoder and graph neural network over knowledge meta graph as knowledge encoder. Besides, a novel knowledge injector is designed for the dynamic interaction between text and knowledge encoder. Experimental results demonstrate the effectiveness of our method especially in queries requiring in-depth domain knowledge.