 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
RGBX-R1: Visual Modality Chain-of-Thought Guided Reinforcement Learning for Multimodal Grounding
Jan 31, 2026Multimodal Large Language Models (MLLM) are primarily pre-trained on the RGB modality, thereby limiting their performance on other modalities, such as infrared, depth, and event data, which are crucial for complex scenarios. To address this, we propose RGBX-R1, a framework to enhance MLLM's perception and reasoning capacities across various X visual modalities. Specifically, we employ an Understand-Associate-Validate (UAV) prompting strategy to construct the Visual Modality Chain-of-Thought (VM-CoT), which aims to expand the MLLMs' RGB understanding capability into X modalities. To progressively enhance reasoning capabilities, we introduce a two-stage training paradigm: Cold-Start Supervised Fine-Tuning (CS-SFT) and Spatio-Temporal Reinforcement Fine-Tuning (ST-RFT). CS-SFT supervises the reasoning process with the guidance of VM-CoT, equipping the MLLM with fundamental modality cognition. Building upon GRPO, ST-RFT employs a Modality-understanding Spatio-Temporal (MuST) reward to reinforce modality reasoning. Notably, we construct the first RGBX-Grounding benchmark, and extensive experiments verify our superiority in multimodal understanding and spatial perception, outperforming baselines by 22.71% on three RGBX grounding tasks.
Adversarial Semantic Augmentation for Training Generative Adversarial Networks under Limited Data
Feb 02, 2025Generative adversarial networks (GANs) have made remarkable achievements in synthesizing images in recent years. Typically, training GANs requires massive data, and the performance of GANs deteriorates significantly when training data is limited. To improve the synthesis performance of GANs in low-data regimes, existing approaches use various data augmentation techniques to enlarge the training sets. However, it is identified that these augmentation techniques may leak or even alter the data distribution. To remedy this, we propose an adversarial semantic augmentation (ASA) technique to enlarge the training data at the semantic level instead of the image level. Concretely, considering semantic features usually encode informative information of images, we estimate the covariance matrices of semantic features for both real and generated images to find meaningful transformation directions. Such directions translate original features to another semantic representation, e.g., changing the backgrounds or expressions of the human face dataset. Moreover, we derive an upper bound of the expected adversarial loss. By optimizing the upper bound, our semantic augmentation is implicitly achieved. Such design avoids redundant sampling of the augmented features and introduces negligible computation overhead, making our approach computation efficient. Extensive experiments on both few-shot and large-scale datasets demonstrate that our method consistently improve the synthesis quality under various data regimes, and further visualized and analytic results suggesting satisfactory versatility of our proposed method.
Pretrained Language Model based Web Search Ranking: From Relevance to Satisfaction
Jun 02, 2023



Search engine plays a crucial role in satisfying users' diverse information needs. Recently, Pretrained Language Models (PLMs) based text ranking models have achieved huge success in web search. However, many state-of-the-art text ranking approaches only focus on core relevance while ignoring other dimensions that contribute to user satisfaction, e.g., document quality, recency, authority, etc. In this work, we focus on ranking user satisfaction rather than relevance in web search, and propose a PLM-based framework, namely SAT-Ranker, which comprehensively models different dimensions of user satisfaction in a unified manner. In particular, we leverage the capacities of PLMs on both textual and numerical inputs, and apply a multi-field input that modularizes each dimension of user satisfaction as an input field. Overall, SAT-Ranker is an effective, extensible, and data-centric framework that has huge potential for industrial applications. On rigorous offline and online experiments, SAT-Ranker obtains remarkable gains on various evaluation sets targeting different dimensions of user satisfaction. It is now fully deployed online to improve the usability of our search engine.
Variational Reasoning over Incomplete Knowledge Graphs for Conversational Recommendation
Dec 23, 2022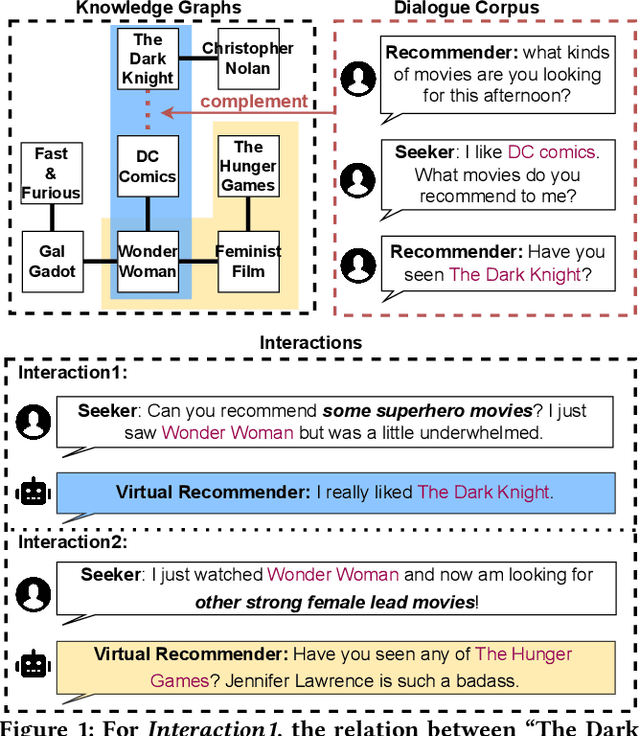
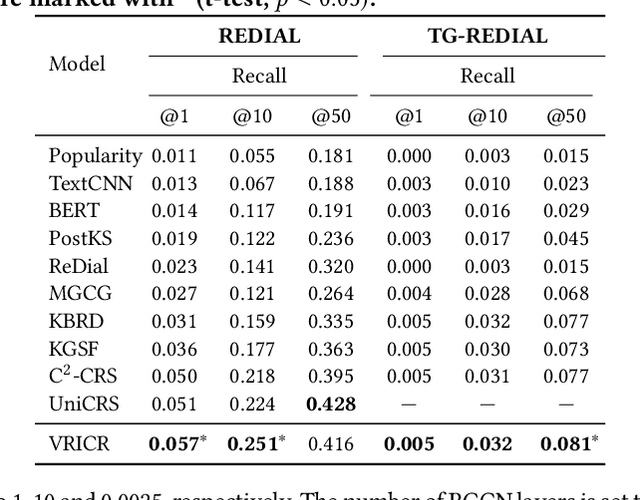
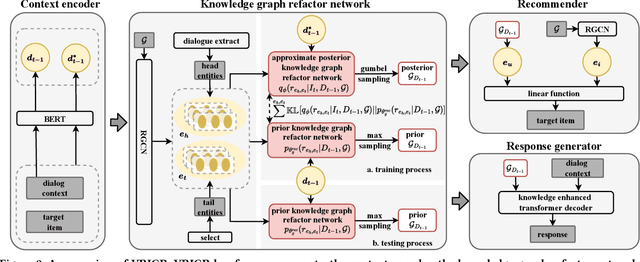
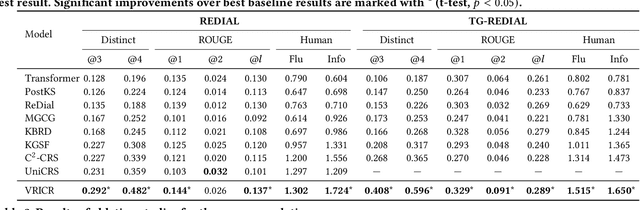
Conversational recommender systems (CRSs) often utilize external knowledge graphs (KGs) to introduce rich semantic information and recommend relevant items through natural language dialogues. However, original KGs employed in existing CRSs are often incomplete and sparse, which limits the reasoning capability in recommendation. Moreover, only few of existing studies exploit the dialogue context to dynamically refine knowledge from KGs for better recommendation. To address the above issues, we propose the Variational Reasoning over Incomplete KGs Conversational Recommender (VRICR). Our key idea is to incorporate the large dialogue corpus naturally accompanied with CRSs to enhance the incomplete KGs; and perform dynamic knowledge reasoning conditioned on the dialogue context. Specifically, we denote the dialogue-specific subgraphs of KGs as latent variables with categorical priors for adaptive knowledge graphs refactor. We propose a variational Bayesian method to approximate posterior distributions over dialogue-specific subgraphs, which not only leverages the dialogue corpus for restructuring missing entity relations but also dynamically selects knowledge based on the dialogue context. Finally, we infuse the dialogue-specific subgraphs to decode the recommendation and responses. We conduct experiments on two benchmark CRSs datasets. Experimental results confirm the effectiveness of our proposed method.
Subtype-Former: a deep learning approach for cancer subtype discovery with multi-omics data
Jul 28, 2022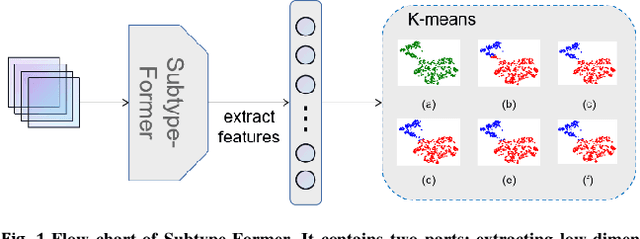
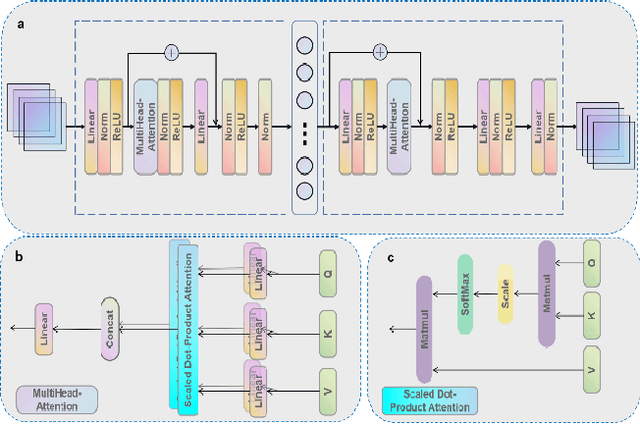
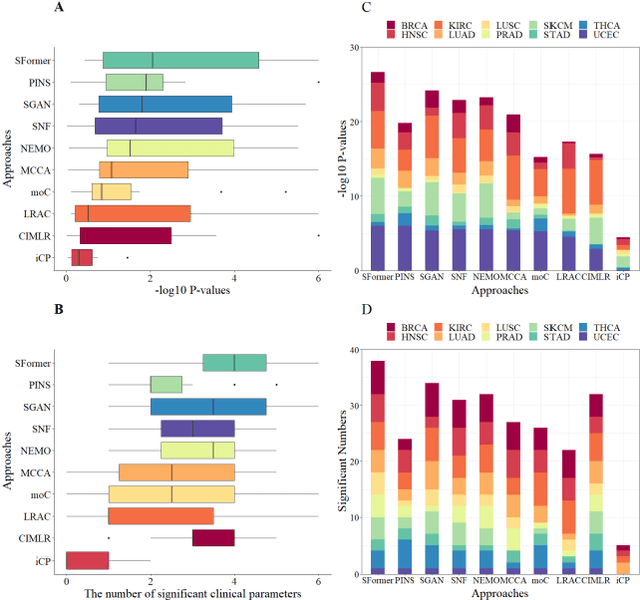
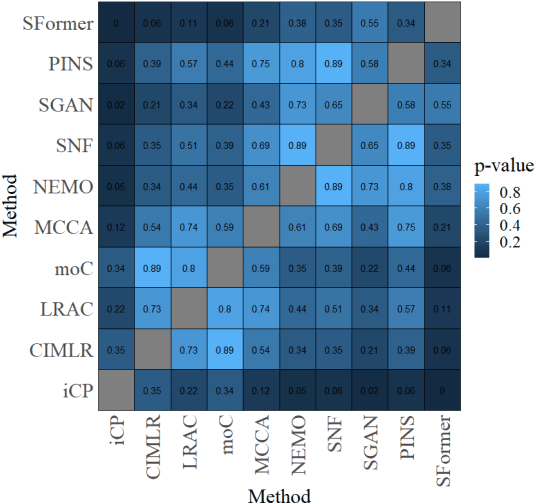
Motivation: Cancer is heterogeneous, affecting the precise approach to personalized treatment. Accurate subtyping can lead to better survival rates for cancer patients. High-throughput technologies provide multiple omics data for cancer subtyping. However, precise cancer subtyping remains challenging due to the large amount and high dimensionality of omics data. Results: This study proposed Subtype-Former, a deep learning method based on MLP and Transformer Block, to extract the low-dimensional representation of the multi-omics data. K-means and Consensus Clustering are also used to achieve accurate subtyping results. We compared Subtype-Former with the other state-of-the-art subtyping methods across the TCGA 10 cancer types. We found that Subtype-Former can perform better on the benchmark datasets of more than 5000 tumors based on the survival analysis. In addition, Subtype-Former also achieved outstanding results in pan-cancer subtyping, which can help analyze the commonalities and differences across various cancer types at the molecular level. Finally, we applied Subtype-Former to the TCGA 10 types of cancers. We identified 50 essential biomarkers, which can be used to study targeted cancer drugs and promote the development of cancer treatments in the era of precision medicine.
Vision-based Anti-UAV Detection and Tracking
May 22, 2022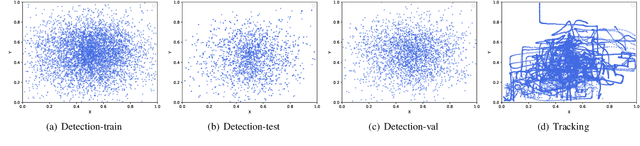


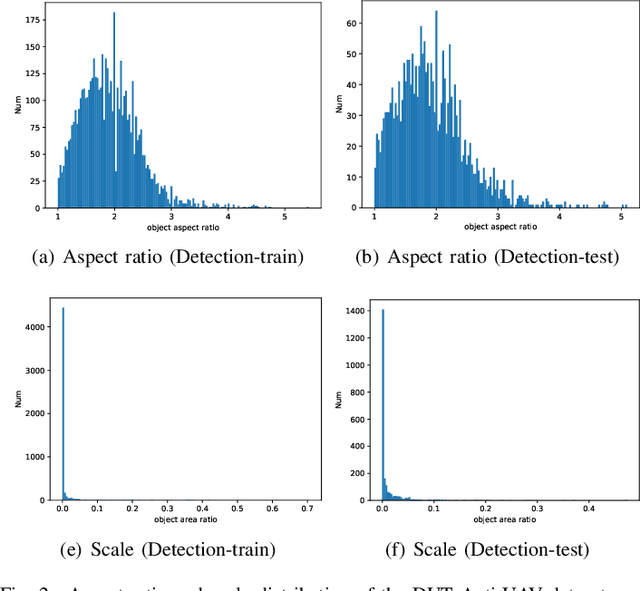
Unmanned aerial vehicles (UAV) have been widely used in various fields, and their invasion of security and privacy has aroused social concern. Several detection and tracking systems for UAVs have been introduced in recent years, but most of them are based on radio frequency, radar, and other media. We assume that the field of computer vision is mature enough to detect and track invading UAVs. Thus we propose a visible light mode dataset called Dalian University of Technology Anti-UAV dataset, DUT Anti-UAV for short. It contains a detection dataset with a total of 10,000 images and a tracking dataset with 20 videos that include short-term and long-term sequences. All frames and images are manually annotated precisely. We use this dataset to train several existing detection algorithms and evaluate the algorithms' performance. Several tracking methods are also tested on our tracking dataset. Furthermore, we propose a clear and simple tracking algorithm combined with detection that inherits the detector's high precision. Extensive experiments show that the tracking performance is improved considerably after fusing detection, thus providing a new attempt at UAV tracking using our dataset.The datasets and results are publicly available at: https://github.com/wangdongdut/DUT-Anti-UAV
Implicit Sample Extension for Unsupervised Person Re-Identification
Apr 14, 2022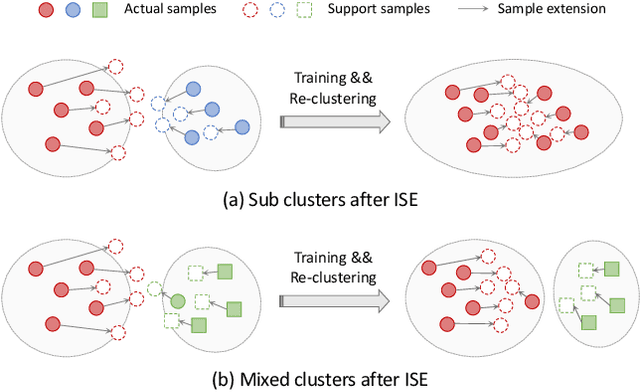
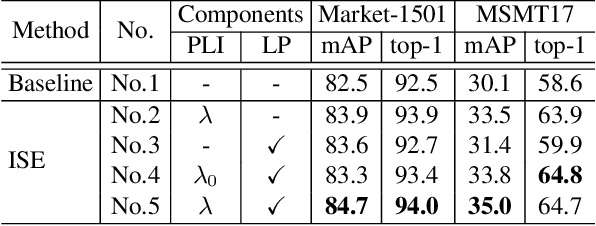
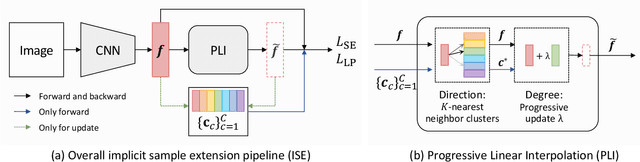
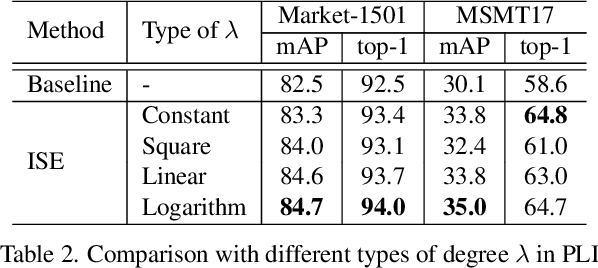
Most existing unsupervised person re-identification (Re-ID) methods use clustering to generate pseudo labels for model training. Unfortunately, clustering sometimes mixes different true identities together or splits the same identity into two or more sub clusters. Training on these noisy clusters substantially hampers the Re-ID accuracy. Due to the limited samples in each identity, we suppose there may lack some underlying information to well reveal the accurate clusters. To discover these information, we propose an Implicit Sample Extension (\OurWholeMethod) method to generate what we call support samples around the cluster boundaries. Specifically, we generate support samples from actual samples and their neighbouring clusters in the embedding space through a progressive linear interpolation (PLI) strategy. PLI controls the generation with two critical factors, i.e., 1) the direction from the actual sample towards its K-nearest clusters and 2) the degree for mixing up the context information from the K-nearest clusters. Meanwhile, given the support samples, ISE further uses a label-preserving loss to pull them towards their corresponding actual samples, so as to compact each cluster. Consequently, ISE reduces the "sub and mixed" clustering errors, thus improving the Re-ID performance. Extensive experiments demonstrate that the proposed method is effective and achieves state-of-the-art performance for unsupervised person Re-ID. Code is available at: \url{https://github.com/PaddlePaddle/PaddleClas}.
Efficient Visual Tracking via Hierarchical Cross-Attention Transformer
Mar 25, 2022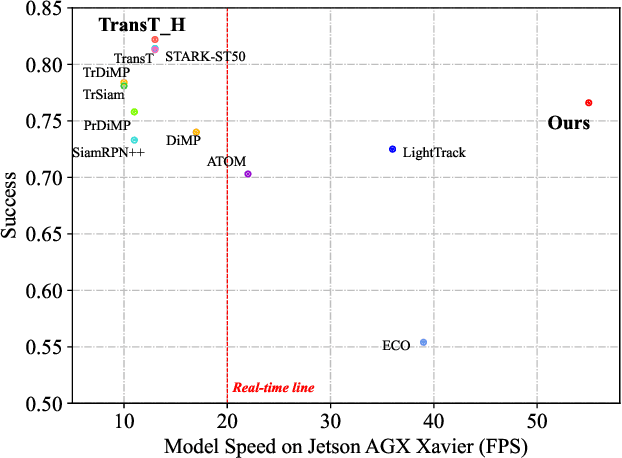


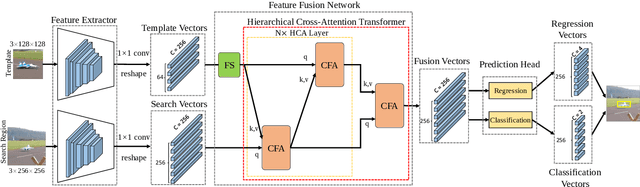
In recent years, target tracking has made great progress in accuracy. This development is mainly attributed to powerful networks (such as transformers) and additional modules (such as online update and refinement modules). However, less attention has been paid to tracking speed. Most state-of-the-art trackers are satisfied with the real-time speed on powerful GPUs. However, practical applications necessitate higher requirements for tracking speed, especially when edge platforms with limited resources are used. In this work, we present an efficient tracking method via a hierarchical cross-attention transformer named HCAT. Our model runs about 195 fps on GPU, 45 fps on CPU, and 55 fps on the edge AI platform of NVidia Jetson AGX Xavier. Experiments show that our HCAT achieves promising results on LaSOT, GOT-10k, TrackingNet, NFS, OTB100, UAV123, and VOT2020. Code and models are available at https://github.com/chenxin-dlut/HCAT.
DiaKG: an Annotated Diabetes Dataset for Medical Knowledge Graph Construction
May 31, 2021
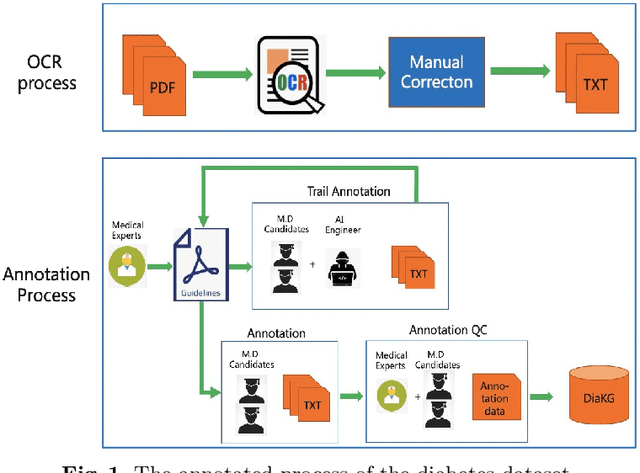

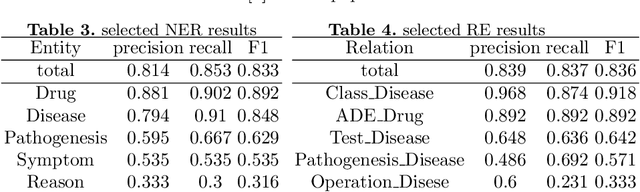
Knowledge Graph has been proven effective in modeling structured information and conceptual knowledge, especially in the medical domain. However, the lack of high-quality annotated corpora remains a crucial problem for advancing the research and applications on this task. In order to accelerate the research for domain-specific knowledge graphs in the medical domain, we introduce DiaKG, a high-quality Chinese dataset for Diabetes knowledge graph, which contains 22,050 entities and 6,890 relations in total. We implement recent typical methods for Named Entity Recognition and Relation Extraction as a benchmark to evaluate the proposed dataset thoroughly. Empirical results show that the DiaKG is challenging for most existing methods and further analysis is conducted to discuss future research direction for improvements. We hope the release of this dataset can assist the construction of diabetes knowledge graphs and facilitate AI-based applications.