 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Semantic Augmentation for Training Generative Adversarial Networks under Limited Data
Feb 02, 2025Generative adversarial networks (GANs) have made remarkable achievements in synthesizing images in recent years. Typically, training GANs requires massive data, and the performance of GANs deteriorates significantly when training data is limited. To improve the synthesis performance of GANs in low-data regimes, existing approaches use various data augmentation techniques to enlarge the training sets. However, it is identified that these augmentation techniques may leak or even alter the data distribution. To remedy this, we propose an adversarial semantic augmentation (ASA) technique to enlarge the training data at the semantic level instead of the image level. Concretely, considering semantic features usually encode informative information of images, we estimate the covariance matrices of semantic features for both real and generated images to find meaningful transformation directions. Such directions translate original features to another semantic representation, e.g., changing the backgrounds or expressions of the human face dataset. Moreover, we derive an upper bound of the expected adversarial loss. By optimizing the upper bound, our semantic augmentation is implicitly achieved. Such design avoids redundant sampling of the augmented features and introduces negligible computation overhead, making our approach computation efficient. Extensive experiments on both few-shot and large-scale datasets demonstrate that our method consistently improve the synthesis quality under various data regimes, and further visualized and analytic results suggesting satisfactory versatility of our proposed method.
FreGAN: Exploiting Frequency Components for Training GANs under Limited Data
Oct 11, 2022
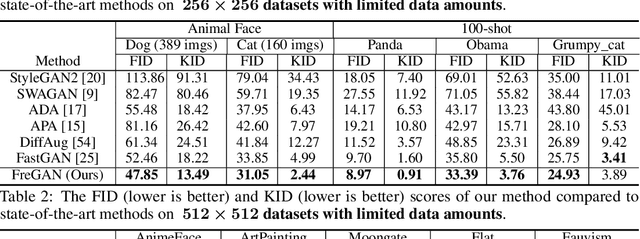
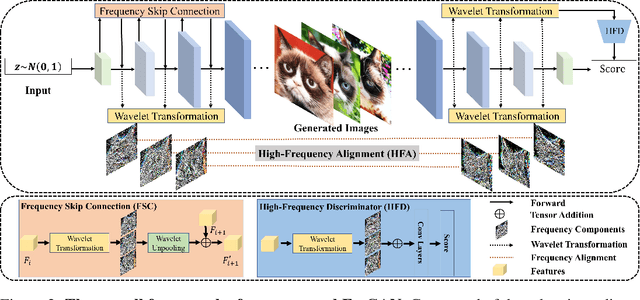
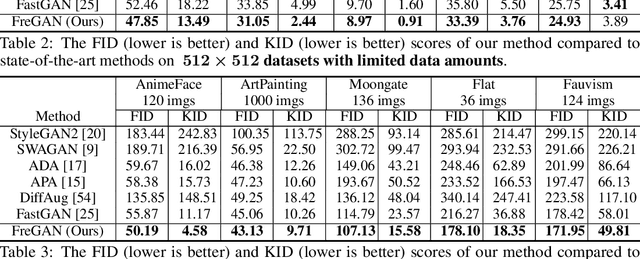
Training GANs under limited data often leads to discriminator overfitting and memorization issues, causing divergent training. Existing approaches mitigate the overfitting by employing data augmentations, model regularization, or attention mechanisms. However, they ignore the frequency bias of GANs and take poor consideration towards frequency information, especially high-frequency signals that contain rich details. To fully utilize the frequency information of limited data, this paper proposes FreGAN, which raises the model's frequency awareness and draws more attention to producing high-frequency signals, facilitating high-quality generation. In addition to exploiting both real and generated images' frequency information, we also involve the frequency signals of real images as a self-supervised constraint, which alleviates the GAN disequilibrium and encourages the generator to synthesize adequate rather than arbitrary frequency signals. Extensive results demonstrate the superiority and effectiveness of our FreGAN in ameliorating generation quality in the low-data regime (especially when training data is less than 100). Besides, FreGAN can be seamlessly applied to existing regularization and attention mechanism models to further boost the performance.
WaveGAN: Frequency-aware GAN for High-Fidelity Few-shot Image Generation
Jul 15, 2022

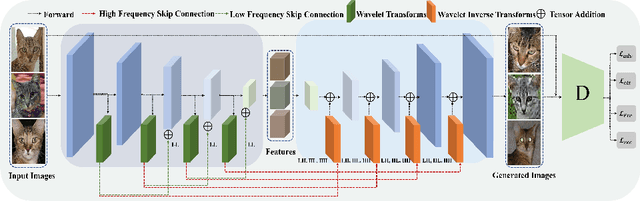
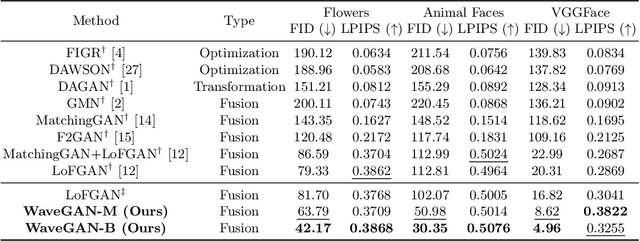
Existing few-shot image generation approaches typically employ fusion-based strategies, either on the image or the feature level, to produce new images. However, previous approaches struggle to synthesize high-frequency signals with fine details, deteriorating the synthesis quality. To address this, we propose WaveGAN, a frequency-aware model for few-shot image generation. Concretely, we disentangle encoded features into multiple frequency components and perform low-frequency skip connections to preserve outline and structural information. Then we alleviate the generator's struggles of synthesizing fine details by employing high-frequency skip connections, thus providing informative frequency information to the generator. Moreover, we utilize a frequency L1-loss on the generated and real images to further impede frequency information loss. Extensive experiments demonstrate the effectiveness and advancement of our method on three datasets. Noticeably, we achieve new state-of-the-art with FID 42.17, LPIPS 0.3868, FID 30.35, LPIPS 0.5076, and FID 4.96, LPIPS 0.3822 respectively on Flower, Animal Faces, and VGGFace. GitHub: https://github.com/kobeshegu/ECCV2022_WaveGAN