 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Few-shot Image Generation by Structural Discrimination and Textural Modulation
Aug 30, 2023



Few-shot image generation, which aims to produce plausible and diverse images for one category given a few images from this category, has drawn extensive attention. Existing approaches either globally interpolate different images or fuse local representations with pre-defined coefficients. However, such an intuitive combination of images/features only exploits the most relevant information for generation, leading to poor diversity and coarse-grained semantic fusion. To remedy this, this paper proposes a novel textural modulation (TexMod) mechanism to inject external semantic signals into internal local representations. Parameterized by the feedback from the discriminator, our TexMod enables more fined-grained semantic injection while maintaining the synthesis fidelity. Moreover, a global structural discriminator (StructD) is developed to explicitly guide the model to generate images with reasonable layout and outline. Furthermore, the frequency awareness of the model is reinforced by encouraging the model to distinguish frequency signals. Together with these techniques, we build a novel and effective model for few-shot image generation. The effectiveness of our model is identified by extensive experiments on three popular datasets and various settings. Besides achieving state-of-the-art synthesis performance on these datasets, our proposed techniques could be seamlessly integrated into existing models for a further performance boost.
WaveGAN: Frequency-aware GAN for High-Fidelity Few-shot Image Generation
Jul 15, 2022

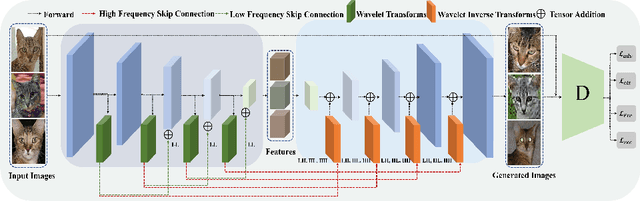
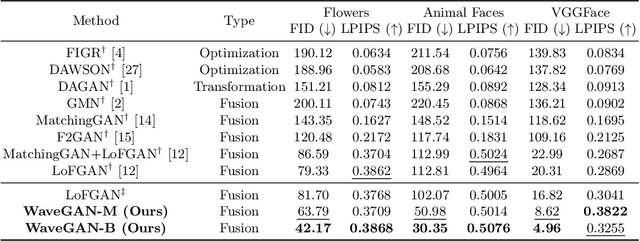
Existing few-shot image generation approaches typically employ fusion-based strategies, either on the image or the feature level, to produce new images. However, previous approaches struggle to synthesize high-frequency signals with fine details, deteriorating the synthesis quality. To address this, we propose WaveGAN, a frequency-aware model for few-shot image generation. Concretely, we disentangle encoded features into multiple frequency components and perform low-frequency skip connections to preserve outline and structural information. Then we alleviate the generator's struggles of synthesizing fine details by employing high-frequency skip connections, thus providing informative frequency information to the generator. Moreover, we utilize a frequency L1-loss on the generated and real images to further impede frequency information loss. Extensive experiments demonstrate the effectiveness and advancement of our method on three datasets. Noticeably, we achieve new state-of-the-art with FID 42.17, LPIPS 0.3868, FID 30.35, LPIPS 0.5076, and FID 4.96, LPIPS 0.3822 respectively on Flower, Animal Faces, and VGGFace. GitHub: https://github.com/kobeshegu/ECCV2022_WaveGAN