 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolving Role of Large Language Models in Scientific Innovation: Evaluator, Collaborator, and Scientist
Jul 16, 2025


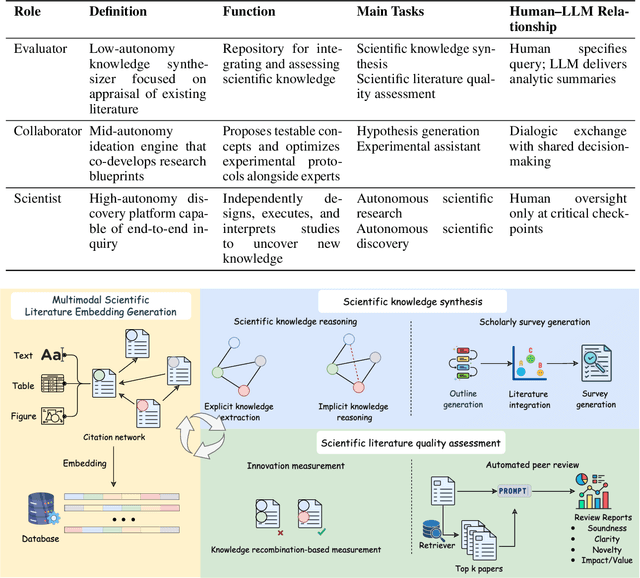
Scientific innovation is undergoing a paradigm shift driven by the rapid advancement of Large Language Models (LLMs). As science faces mounting challenges including information overload, disciplinary silos, and diminishing returns on conventional research methods, LLMs are emerging as powerful agents capable not only of enhancing scientific workflows but also of participating in and potentially leading the innovation process. Existing surveys mainly focus on different perspectives, phrases, and tasks in scientific research and discovery, while they have limitations in understanding the transformative potential and role differentiation of LLM. This survey proposes a comprehensive framework to categorize the evolving roles of LLMs in scientific innovation across three hierarchical levels: Evaluator, Collaborator, and Scientist. We distinguish between LLMs' contributions to structured scientific research processes and open-ended scientific discovery, thereby offering a unified taxonomy that clarifies capability boundaries, evaluation criteria, and human-AI interaction patterns at each level. Through an extensive analysis of current methodologies, benchmarks, systems, and evaluation metrics, this survey delivers an in-depth and systematic synthesis on LLM-driven scientific innovation. We present LLMs not only as tools for automating existing processes, but also as catalysts capable of reshaping the epistemological foundations of science itself. This survey offers conceptual clarity, practical guidance, and theoretical foundations for future research, while also highlighting open challenges and ethical considerations in the pursuit of increasingly autonomous AI-driven science. Resources related to this survey can be accessed on GitHub at: https://github.com/haoxuan-unt2024/llm4innovation.
HumanoidGen: Data Generation for Bimanual Dexterous Manipulation via LLM Reasoning
Jul 01, 2025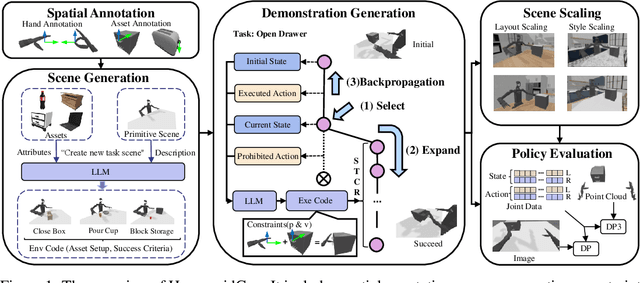
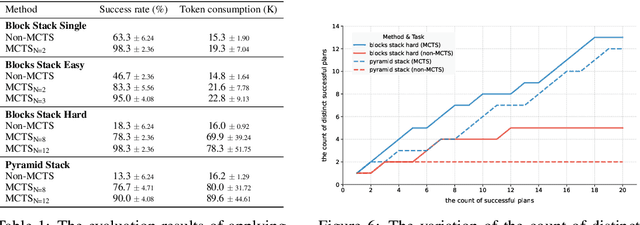
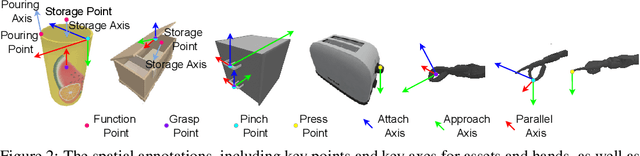
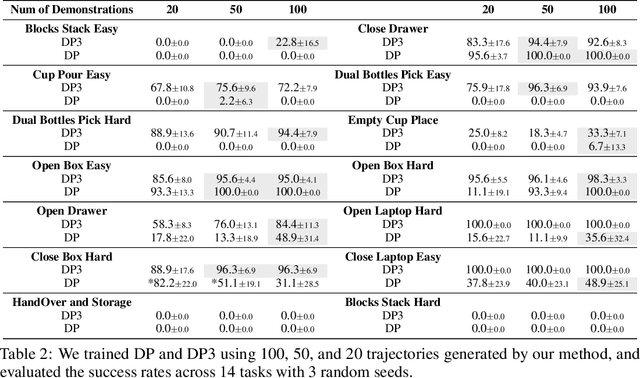
For robotic manipulation, existing robotics datasets and simulation benchmarks predominantly cater to robot-arm platforms. However, for humanoid robots equipped with dual arms and dexterous hands, simulation tasks and high-quality demonstrations are notably lacking. Bimanual dexterous manipulation is inherently more complex, as it requires coordinated arm movements and hand operations, making autonomous data collection challenging. This paper presents HumanoidGen, an automated task creation and demonstration collection framework that leverages atomic dexterous operations and LLM reasoning to generate relational constraints. Specifically, we provide spatial annotations for both assets and dexterous hands based on the atomic operations, and perform an LLM planner to generate a chain of actionable spatial constraints for arm movements based on object affordances and scenes. To further improve planning ability, we employ a variant of Monte Carlo tree search to enhance LLM reasoning for long-horizon tasks and insufficient annotation. In experiments, we create a novel benchmark with augmented scenarios to evaluate the quality of the collected data. The results show that the performance of the 2D and 3D diffusion policies can scale with the generated dataset. Project page is https://openhumanoidgen.github.io.
Unsupervised Skill Discovery through Skill Regions Differentiation
Jun 17, 2025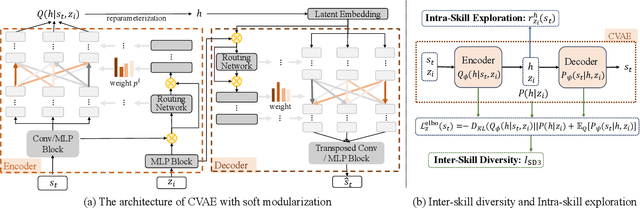
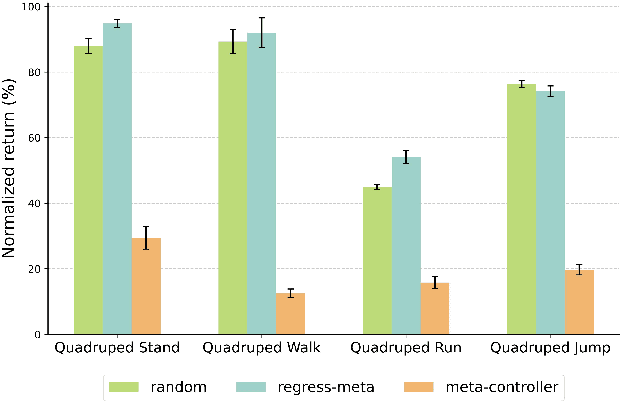
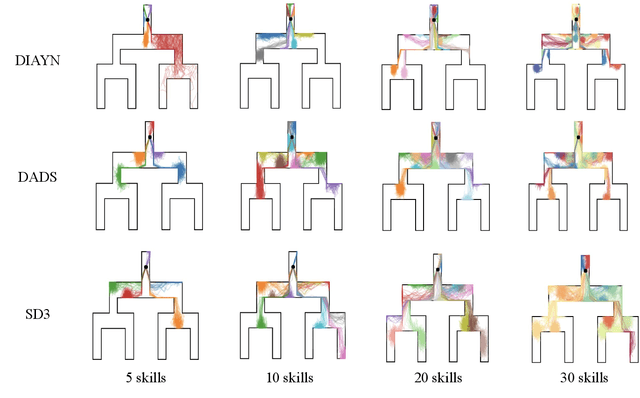

Unsupervised Reinforcement Learning (RL) aims to discover diverse behaviors that can accelerate the learning of downstream tasks. Previous methods typically focus on entropy-based exploration or empowerment-driven skill learning. However, entropy-based exploration struggles in large-scale state spaces (e.g., images), and empowerment-based methods with Mutual Information (MI) estimations have limitations in state exploration. To address these challenges, we propose a novel skill discovery objective that maximizes the deviation of the state density of one skill from the explored regions of other skills, encouraging inter-skill state diversity similar to the initial MI objective. For state-density estimation, we construct a novel conditional autoencoder with soft modularization for different skill policies in high-dimensional space. Meanwhile, to incentivize intra-skill exploration, we formulate an intrinsic reward based on the learned autoencoder that resembles count-based exploration in a compact latent space. Through extensive experiments in challenging state and image-based tasks, we find our method learns meaningful skills and achieves superior performance in various downstream tasks.
Learn as Individuals, Evolve as a Team: Multi-agent LLMs Adaptation in Embodied Environments
Jun 08, 2025



Large language models (LLMs) possess extensive knowledge bases and strong reasoning capabilities, making them promising tools for complex, multi-agent planning in embodied environments. However, despite LLMs' advanced abilities and the sophisticated modular design of agentic methods, existing LLM-based planning algorithms remain limited by weak adaptation capabilities to multi-agent embodied scenarios. We address this limitation by introducing a framework that enables LLM agents to learn and evolve both before and during test time, equipping them with environment-relevant knowledge for better planning and enhanced communication for improved cooperation. Inspired by centralized training with decentralized execution in multi-agent reinforcement learning, we propose a \textit{Learn as Individuals, Evolve as a Team (LIET)} paradigm for multi-agent LLMs adaptation. At the individual level, LLM agents learn a local utility function from exploratory datasets to better comprehend the embodied environment, which is then queried during test time to support informed decision-making. At the team level, LLM agents collaboratively and iteratively maintain and update a shared cooperation knowledge list based on new experiences, using it to guide more effective communication. By combining individual learning with team evolution, LIET enables comprehensive and flexible adaptation for LLM agents. Our experiments on Communicative Watch-And-Help and ThreeD-World Multi-Agent Transport benchmarks demonstrate that LIET, instantiated with both LLaMA and GPT-4o, outperforms existing baselines and exhibits strong cooperative planning abilities.
Online Iterative Self-Alignment for Radiology Report Generation
May 17, 2025



Radiology Report Generation (RRG) is an important research topic for relieving radiologist' heavy workload. Existing RRG models mainly rely on supervised fine-tuning (SFT) based on different model architectures using data pairs of radiological images and corresponding radiologist-annotated reports. Recent research has shifted focus to post-training improvements, aligning RRG model outputs with human preferences using reinforcement learning (RL). However, the limited data coverage of high-quality annotated data poses risks of overfitting and generalization. This paper proposes a novel Online Iterative Self-Alignment (OISA) method for RRG that consists of four stages: self-generation of diverse data, self-evaluation for multi-objective preference data,self-alignment for multi-objective optimization and self-iteration for further improvement. Our approach allows for generating varied reports tailored to specific clinical objectives, enhancing the overall performance of the RRG model iteratively. Unlike existing methods, our frame-work significantly increases data quality and optimizes performance through iterative multi-objective optimization. Experimental results demonstrate that our method surpasses previous approaches, achieving state-of-the-art performance across multiple evaluation metrics.
A Multimodal Multi-Agent Framework for Radiology Report Generation
May 14, 2025Radiology report generation (RRG) aims to automatically produce diagnostic reports from medical images, with the potential to enhance clinical workflows and reduce radiologists' workload. While recent approaches leveraging multimodal large language models (MLLMs) and retrieval-augmented generation (RAG) have achieved strong results, they continue to face challenges such as factual inconsistency, hallucination, and cross-modal misalignment. We propose a multimodal multi-agent framework for RRG that aligns with the stepwise clinical reasoning workflow, where task-specific agents handle retrieval, draft generation, visual analysis, refinement, and synthesis. Experimental results demonstrate that our approach outperforms a strong baseline in both automatic metrics and LLM-based evaluations, producing more accurate, structured, and interpretable reports. This work highlights the potential of clinically aligned multi-agent frameworks to support explainable and trustworthy clinical AI applications.
Radiology Report Generation via Multi-objective Preference Optimization
Dec 12, 2024



Automatic Radiology Report Generation (RRG) is an important topic for alleviating the substantial workload of radiologists. Existing RRG approaches rely on supervised regression based on different architectures or additional knowledge injection,while the generated report may not align optimally with radiologists' preferences. Especially, since the preferences of radiologists are inherently heterogeneous and multidimensional, e.g., some may prioritize report fluency, while others emphasize clinical accuracy. To address this problem,we propose a new RRG method via Multi-objective Preference Optimization (MPO) to align the pre-trained RRG model with multiple human preferences, which can be formulated by multi-dimensional reward functions and optimized by multi-objective reinforcement learning (RL). Specifically, we use a preference vector to represent the weight of preferences and use it as a condition for the RRG model. Then, a linearly weighed reward is obtained via a dot product between the preference vector and multi-dimensional reward.Next,the RRG model is optimized to align with the preference vector by optimizing such a reward via RL. In the training stage,we randomly sample diverse preference vectors from the preference space and align the model by optimizing the weighted multi-objective rewards, which leads to an optimal policy on the entire preference space. When inference,our model can generate reports aligned with specific preferences without further fine-tuning. Extensive experiments on two public datasets show the proposed method can generate reports that cater to different preferences in a single model and achieve state-of-the-art performance.
Constrained Ensemble Exploration for Unsupervised Skill Discovery
May 25, 2024Unsupervised Reinforcement Learning (RL) provides a promising paradigm for learning useful behaviors via reward-free per-training. Existing methods for unsupervised RL mainly conduct empowerment-driven skill discovery or entropy-based exploration. However, empowerment often leads to static skills, and pure exploration only maximizes the state coverage rather than learning useful behaviors. In this paper, we propose a novel unsupervised RL framework via an ensemble of skills, where each skill performs partition exploration based on the state prototypes. Thus, each skill can explore the clustered area locally, and the ensemble skills maximize the overall state coverage. We adopt state-distribution constraints for the skill occupancy and the desired cluster for learning distinguishable skills. Theoretical analysis is provided for the state entropy and the resulting skill distributions. Based on extensive experiments on several challenging tasks, we find our method learns well-explored ensemble skills and achieves superior performance in various downstream tasks compared to previous methods.
Improving Few-shot Image Generation by Structural Discrimination and Textural Modulation
Aug 30, 2023



Few-shot image generation, which aims to produce plausible and diverse images for one category given a few images from this category, has drawn extensive attention. Existing approaches either globally interpolate different images or fuse local representations with pre-defined coefficients. However, such an intuitive combination of images/features only exploits the most relevant information for generation, leading to poor diversity and coarse-grained semantic fusion. To remedy this, this paper proposes a novel textural modulation (TexMod) mechanism to inject external semantic signals into internal local representations. Parameterized by the feedback from the discriminator, our TexMod enables more fined-grained semantic injection while maintaining the synthesis fidelity. Moreover, a global structural discriminator (StructD) is developed to explicitly guide the model to generate images with reasonable layout and outline. Furthermore, the frequency awareness of the model is reinforced by encouraging the model to distinguish frequency signals. Together with these techniques, we build a novel and effective model for few-shot image generation. The effectiveness of our model is identified by extensive experiments on three popular datasets and various settings. Besides achieving state-of-the-art synthesis performance on these datasets, our proposed techniques could be seamlessly integrated into existing models for a further performance boost.
Stock2Vec: An Embedding to Improve Predictive Models for Companies
Jan 27, 2022



Building predictive models for companies often relies on inference using historical data of companies in the same industry sector. However, companies are similar across a variety of dimensions that should be leveraged in relevant prediction problems. This is particularly true for large, complex organizations which may not be well defined by a single industry and have no clear peers. To enable prediction using company information across a variety of dimensions, we create an embedding of company stocks, Stock2Vec, which can be easily added to any prediction model that applies to companies with associated stock prices. We describe the process of creating this rich vector representation from stock price fluctuations, and characterize what the dimensions represent. We then conduct comprehensive experiments to evaluate this embedding in applied machine learning problems in various business contexts. Our experiment results demonstrate that the four features in the Stock2Vec embedding can readily augment existing cross-company models and enhance cross-company predictions.