 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicLog: Towards Accurate and Efficient LLM-based Log Parsing via Progressive Meta In-Context Learning
Jan 11, 2026Log parsing converts semi-structured logs into structured templates, forming a critical foundation for downstream analysis. Traditional syntax and semantic-based parsers often struggle with semantic variations in evolving logs and data scarcity stemming from their limited domain coverage. Recent large language model (LLM)-based parsers leverage in-context learning (ICL) to extract semantics from examples, demonstrating superior accuracy. However, LLM-based parsers face two main challenges: 1) underutilization of ICL capabilities, particularly in dynamic example selection and cross-domain generalization, leading to inconsistent performance; 2) time-consuming and costly LLM querying. To address these challenges, we present MicLog, the first progressive meta in-context learning (ProgMeta-ICL) log parsing framework that combines meta-learning with ICL on small open-source LLMs (i.e., Qwen-2.5-3B). Specifically, MicLog: i) enhances LLMs' ICL capability through a zero-shot to k-shot ProgMeta-ICL paradigm, employing weighted DBSCAN candidate sampling and enhanced BM25 demonstration selection; ii) accelerates parsing via a multi-level pre-query cache that dynamically matches and refines recently parsed templates. Evaluated on Loghub-2.0, MicLog achieves 10.3% higher parsing accuracy than the state-of-the-art parser while reducing parsing time by 42.4%.
Unsupervised Skill Discovery through Skill Regions Differentiation
Jun 17, 2025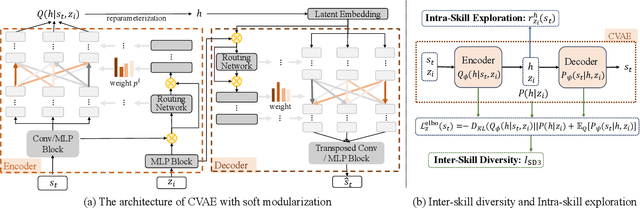
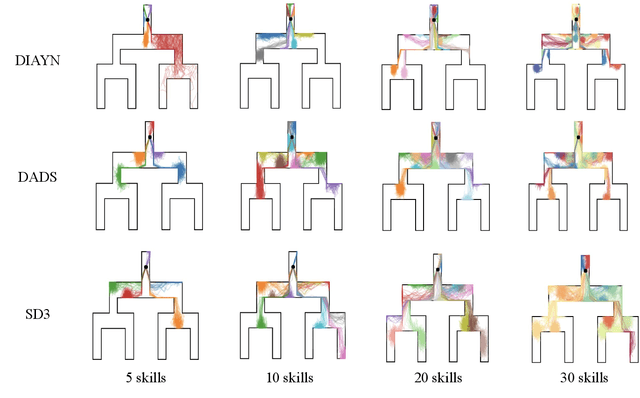

Unsupervised Reinforcement Learning (RL) aims to discover diverse behaviors that can accelerate the learning of downstream tasks. Previous methods typically focus on entropy-based exploration or empowerment-driven skill learning. However, entropy-based exploration struggles in large-scale state spaces (e.g., images), and empowerment-based methods with Mutual Information (MI) estimations have limitations in state exploration. To address these challenges, we propose a novel skill discovery objective that maximizes the deviation of the state density of one skill from the explored regions of other skills, encouraging inter-skill state diversity similar to the initial MI objective. For state-density estimation, we construct a novel conditional autoencoder with soft modularization for different skill policies in high-dimensional space. Meanwhile, to incentivize intra-skill exploration, we formulate an intrinsic reward based on the learned autoencoder that resembles count-based exploration in a compact latent space. Through extensive experiments in challenging state and image-based tasks, we find our method learns meaningful skills and achieves superior performance in various downstream tasks.
3D Gaussian Inverse Rendering with Approximated Global Illumination
Apr 02, 20253D Gaussian Splatting shows great potential in reconstructing photo-realistic 3D scenes. However, these methods typically bake illumination into their representations, limiting their use for physically-based rendering and scene editing. Although recent inverse rendering approaches aim to decompose scenes into material and lighting components, they often rely on simplifying assumptions that fail when editing. We present a novel approach that enables efficient global illumination for 3D Gaussians Splatting through screen-space ray tracing. Our key insight is that a substantial amount of indirect light can be traced back to surfaces visible within the current view frustum. Leveraging this observation, we augment the direct shading computed by 3D Gaussians with Monte-Carlo screen-space ray-tracing to capture one-bounce indirect illumination. In this way, our method enables realistic global illumination without sacrificing the computational efficiency and editability benefits of 3D Gaussians. Through experiments, we show that the screen-space approximation we utilize allows for indirect illumination and supports real-time rendering and editing. Code, data, and models will be made available at our project page: https://wuzirui.github.io/gs-ssr.
ODRL: A Benchmark for Off-Dynamics Reinforcement Learning
Oct 28, 2024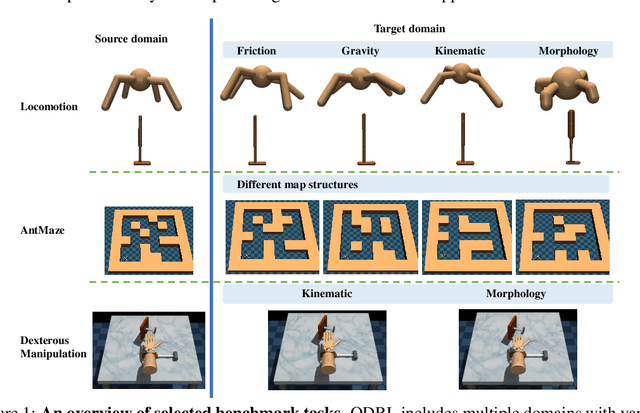

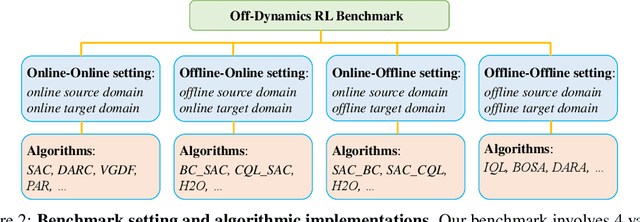

We consider off-dynamics reinforcement learning (RL) where one needs to transfer policies across different domains with dynamics mismatch. Despite the focus on developing dynamics-aware algorithms, this field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ODRL, the first benchmark tailored for evaluating off-dynamics RL methods. ODRL contains four experimental settings where the source and target domains can be either online or offline, and provides diverse tasks and a broad spectrum of dynamics shifts, making it a reliable platform to comprehensively evaluate the agent's adaptation ability to the target domain. Furthermore, ODRL includes recent off-dynamics RL algorithms in a unified framework and introduces some extra baselines for different settings, all implemented in a single-file manner. To unpack the true adaptation capability of existing methods, we conduct extensive benchmarking experiments, which show that no method has universal advantages across varied dynamics shifts. We hope this benchmark can serve as a cornerstone for future research endeavors. Our code is publicly available at https://github.com/OffDynamicsRL/off-dynamics-rl.
Serialized Point Mamba: A Serialized Point Cloud Mamba Segmentation Model
Jul 17, 2024



Point cloud segmentation is crucial for robotic visual perception and environmental understanding, enabling applications such as robotic navigation and 3D reconstruction. However, handling the sparse and unordered nature of point cloud data presents challenges for efficient and accurate segmentation. Inspired by the Mamba model's success in natural language processing, we propose the Serialized Point Cloud Mamba Segmentation Model (Serialized Point Mamba), which leverages a state-space model to dynamically compress sequences, reduce memory usage, and enhance computational efficiency. Serialized Point Mamba integrates local-global modeling capabilities with linear complexity, achieving state-of-the-art performance on both indoor and outdoor datasets. This approach includes novel techniques such as staged point cloud sequence learning, grid pooling, and Conditional Positional Encoding, facilitating effective segmentation across diverse point cloud tasks. Our method achieved 76.8 mIoU on Scannet and 70.3 mIoU on S3DIS. In Scannetv2 instance segmentation, it recorded 40.0 mAP. It also had the lowest latency and reasonable memory use, making it the SOTA among point semantic segmentation models based on mamba.
VersiCode: Towards Version-controllable Code Generation
Jun 11, 2024

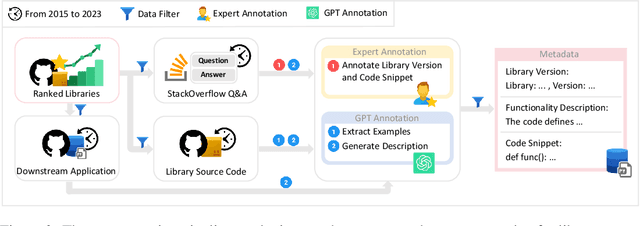

Significant research has focused on improving the performance of large language model on code-related tasks due to their practical importance. Although performance is typically evaluated using public benchmark datasets, the existing datasets do not account for the concept of \emph{version}, which is crucial in professional software development. In this paper, we introduce VersiCode, the first comprehensive dataset designed to assess the ability of large language models to generate verifiable code for specific library versions. VersiCode encompasses 300 libraries across more than 2,000 versions spanning 9 years. We design two dedicated evaluation tasks: version-specific code completion (VSCC) and version-aware code editing (VACE). Comprehensive experiments are conducted to benchmark the performance of LLMs, revealing the challenging nature of these tasks and VersiCode, that even state-of-the-art LLMs struggle to generate version-correct code. This dataset, together with the proposed tasks, sheds light on LLMs' capabilities and limitations in handling version-specific code generation, and opens up an important new area of research for further investigation. The resources can be found at https://github.com/wutong8023/VersiCode.
Constrained Ensemble Exploration for Unsupervised Skill Discovery
May 25, 2024Unsupervised Reinforcement Learning (RL) provides a promising paradigm for learning useful behaviors via reward-free per-training. Existing methods for unsupervised RL mainly conduct empowerment-driven skill discovery or entropy-based exploration. However, empowerment often leads to static skills, and pure exploration only maximizes the state coverage rather than learning useful behaviors. In this paper, we propose a novel unsupervised RL framework via an ensemble of skills, where each skill performs partition exploration based on the state prototypes. Thus, each skill can explore the clustered area locally, and the ensemble skills maximize the overall state coverage. We adopt state-distribution constraints for the skill occupancy and the desired cluster for learning distinguishable skills. Theoretical analysis is provided for the state entropy and the resulting skill distributions. Based on extensive experiments on several challenging tasks, we find our method learns well-explored ensemble skills and achieves superior performance in various downstream tasks compared to previous methods.
Contrastive Representation for Data Filtering in Cross-Domain Offline Reinforcement Learning
May 10, 2024



Cross-domain offline reinforcement learning leverages source domain data with diverse transition dynamics to alleviate the data requirement for the target domain. However, simply merging the data of two domains leads to performance degradation due to the dynamics mismatch. Existing methods address this problem by measuring the dynamics gap via domain classifiers while relying on the assumptions of the transferability of paired domains. In this paper, we propose a novel representation-based approach to measure the domain gap, where the representation is learned through a contrastive objective by sampling transitions from different domains. We show that such an objective recovers the mutual-information gap of transition functions in two domains without suffering from the unbounded issue of the dynamics gap in handling significantly different domains. Based on the representations, we introduce a data filtering algorithm that selectively shares transitions from the source domain according to the contrastive score functions. Empirical results on various tasks demonstrate that our method achieves superior performance, using only 10% of the target data to achieve 89.2% of the performance on 100% target dataset with state-of-the-art methods.
Large Scale Foundation Models for Intelligent Manufacturing Applications: A Survey
Dec 22, 2023Although the applications of artificial intelligence especially deep learning had greatly improved various aspects of intelligent manufacturing, they still face challenges for wide employment due to the poor generalization ability, difficulties to establish high-quality training datasets, and unsatisfactory performance of deep learning methods. The emergence of large scale foundational models(LSFMs) had triggered a wave in the field of artificial intelligence, shifting deep learning models from single-task, single-modal, limited data patterns to a paradigm encompassing diverse tasks, multimodal, and pre-training on massive datasets. Although LSFMs had demonstrated powerful generalization capabilities, automatic high-quality training dataset generation and superior performance across various domains, applications of LSFMs on intelligent manufacturing were still in their nascent stage. A systematic overview of this topic was lacking, especially regarding which challenges of deep learning can be addressed by LSFMs and how these challenges can be systematically tackled. To fill this gap, this paper systematically expounded current statue of LSFMs and their advantages in the context of intelligent manufacturing. and compared comprehensively with the challenges faced by current deep learning models in various intelligent manufacturing applications. We also outlined the roadmaps for utilizing LSFMs to address these challenges. Finally, case studies of applications of LSFMs in real-world intelligent manufacturing scenarios were presented to illustrate how LSFMs could help industries, improve their efficiency.
Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning
May 29, 2023Diffusion models have demonstrated highly-expressive generative capabilities in vision and NLP. Recent studies in reinforcement learning (RL) have shown that diffusion models are also powerful in modeling complex policies or trajectories in offline datasets. However, these works have been limited to single-task settings where a generalist agent capable of addressing multi-task predicaments is absent. In this paper, we aim to investigate the effectiveness of a single diffusion model in modeling large-scale multi-task offline data, which can be challenging due to diverse and multimodal data distribution. Specifically, we propose Multi-Task Diffusion Model (\textsc{MTDiff}), a diffusion-based method that incorporates Transformer backbones and prompt learning for generative planning and data synthesis in multi-task offline settings. \textsc{MTDiff} leverages vast amounts of knowledge available in multi-task data and performs implicit knowledge sharing among tasks. For generative planning, we find \textsc{MTDiff} outperforms state-of-the-art algorithms across 50 tasks on Meta-World and 8 maps on Maze2D. For data synthesis, \textsc{MTDiff} generates high-quality data for testing tasks given a single demonstration as a prompt, which enhances the low-quality datasets for even unseen tasks.