 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient RAG with Intent-Aware Retrieval and Semantics-Preserving Chunking
May 31, 2026The demand for powerful instruction following and reasoning capability of large language models (LLMs) has promoted rapid development of retrieval-augmented generation (RAG). The RAG system assists LLM generation by retrieving chunks of query-fit supplementary knowledge from an external database. Conventional RAG systems, however, suffer from information insufficiency due to two factors, which are intent-agnostic retrieval and information fragmentation. Our work proposes a RAG framework, termed InSemRAG, that addresses these challenges via an iterative retrieve-and-check mechanism with two supporting modules, an intention-aware retriever (IAR) and semantics-preserving chunking (SPC). IAR implements a dynamic hybrid retrieval method that adaptively weights the retrieval channels based on the query intent, while SPC performs detection and reparation to the damaged evidence chunks to preserve the semantic integrity. To alleviate the computational latency brought by our iterative mechanism, we leverage small language models (SLMs). Extensive experiments across several benchmark datasets consistently demonstrate the competitiveness of our method against recent state-of-the-art RAG mechanisms. Particularly, our method achieves significant gains on multi-hop and evidence-sensitive tasks, with a 2.65-point improvement in F1 on HotPotQA and a 1.5-point increase in accuracy on FEVER. Our method also achieves competitive performance to Multi-Hop RAG with 4.32$\times$ lower latency with the utilization of SLM.
Beyond Point-wise Neural Collapse: A Topology-Aware Hierarchical Classifier for Class-Incremental Learning
May 12, 2026The Nearest Class Mean (NCM) classifier is widely favored in Class-Incremental Learning (CIL) for its superior resistance to catastrophic forgetting compared to Fully Connected layers. While Neural Collapse (NC) theory supports NCM's optimality by assuming features collapse into single points, non-linear feature drift and insufficient training in CIL often prevent this ideal state. Consequently, classes manifest as complex manifolds rather than collapsed points, rendering the single-point NCM suboptimal. To address this, we propose Hierarchical-Cluster SOINN (HC-SOINN), a novel classifier that captures the topological structure of these manifolds via a ``local-to-global'' representation. Furthermore, we introduce Structure-Topology Alignment via Residuals (STAR) method, which employs a fine-grained pointwise trajectory tracking mechanism to actively deform the learned topology, allowing it to adapt precisely to complex non-linear feature drift. Theoretical analysis and Procrustes distance experiments validate our framework's resilience to manifold deformations. We integrated HC-SOINN into seven state-of-the-art methods by replacing their original classifiers, achieving consistent improvements that highlight the effectiveness and robustness of our approach. Code is available at https://github.com/yhyet/HC_SOINN.
The Cartesian Shortcut: Re-evaluate Vision Reasoning in Polar Coordinate Space
May 11, 2026As current Multimodal Large Language Models rapidly saturate canonical visual reasoning benchmarks, a key question emerges: do these strong scores genuinely reflect robust visual understanding? We identify a pervasive vulnerability, the \textbf{Cartesian Shortcut}: visual reasoning benchmarks prevalently build on orthogonal grid-based layouts that can be readily discretized into explicit textual coordinates. Models systematically exploit this property, heavily leveraging text-based deductive reasoning to assist visual problem-solving. To systematically dismantle this shortcut, we introduce \textbf{Polaris-Bench}, which re-formulates 53 visual reasoning tasks in Polar coordinate space with paired Cartesian counterparts as reference, while preserving consistent logical constraints and task semantics -- thus fundamentally breaking the orthogonal prior that models exploit. Comprehensive evaluation across $14$ state-of-the-art MLLMs reveals that frontier models achieving $70$--$83\%$ on Cartesian layouts collapse to $31$--$39\%$ on Polar equivalents, with degradation persisting even under complete logical equivalence. Moreover, reasoning gains observed on Cartesian layouts are severely diminished on Polar equivalents. These findings expose a critical deficiency in current MLLMs: the lack of topology-invariant visual reasoning.
Image Generators are Generalist Vision Learners
Apr 22, 2026Recent works show that image and video generators exhibit zero-shot visual understanding behaviors, in a way reminiscent of how LLMs develop emergent capabilities of language understanding and reasoning from generative pretraining. While it has long been conjectured that the ability to create visual content implies an ability to understand it, there has been limited evidence that generative vision models have developed strong understanding capabilities. In this work, we demonstrate that image generation training serves a role similar to LLM pretraining, and lets models learn powerful and general visual representations that enable SOTA performance on various vision tasks. We introduce Vision Banana, a generalist model built by instruction-tuning Nano Banana Pro (NBP) on a mixture of its original training data alongside a small amount of vision task data. By parameterizing the output space of vision tasks as RGB images, we seamlessly reframe perception as image generation. Our generalist model, Vision Banana, achieves SOTA results on a variety of vision tasks involving both 2D and 3D understanding, beating or rivaling zero-shot domain-specialists, including Segment Anything Model 3 on segmentation tasks, and the Depth Anything series on metric depth estimation. We show that these results can be achieved with lightweight instruction-tuning without sacrificing the base model's image generation capabilities. The superior results suggest that image generation pretraining is a generalist vision learner. It also shows that image generation serves as a unified and universal interface for vision tasks, similar to text generation's role in language understanding and reasoning. We could be witnessing a major paradigm shift for computer vision, where generative vision pretraining takes a central role in building Foundational Vision Models for both generation and understanding.
Lightweight LLM Agent Memory with Small Language Models
Apr 09, 2026Although LLM agents can leverage tools for complex tasks, they still need memory to maintain cross-turn consistency and accumulate reusable information in long-horizon interactions. However, retrieval-based external memory systems incur low online overhead but suffer from unstable accuracy due to limited query construction and candidate filtering. In contrast, many systems use repeated large-model calls for online memory operations, improving accuracy but accumulating latency over long interactions. We propose LightMem, a lightweight memory system for better agent memory driven by Small Language Models (SLMs). LightMem modularizes memory retrieval, writing, and long-term consolidation, and separates online processing from offline consolidation to enable efficient memory invocation under bounded compute. We organize memory into short-term memory (STM) for immediate conversational context, mid-term memory (MTM) for reusable interaction summaries, and long-term memory (LTM) for consolidated knowledge, and uses user identifiers to support independent retrieval and incremental maintenance in multi-user settings. Online, LightMem operates under a fixed retrieval budget and selects memories via a two-stage procedure: vector-based coarse retrieval followed by semantic consistency re-ranking. Offline, it abstracts reusable interaction evidence and incrementally integrates it into LTM. Experiments show gains across model scales, with an average F1 improvement of about 2.5 on LoCoMo, more effective and low median latency (83 ms retrieval; 581 ms end-to-end).
Pailitao-VL: Unified Embedding and Reranker for Real-Time Multi-Modal Industrial Search
Feb 14, 2026In this work, we presented Pailitao-VL, a comprehensive multi-modal retrieval system engineered for high-precision, real-time industrial search. We here address three critical challenges in the current SOTA solution: insufficient retrieval granularity, vulnerability to environmental noise, and prohibitive efficiency-performance gap. Our primary contribution lies in two fundamental paradigm shifts. First, we transitioned the embedding paradigm from traditional contrastive learning to an absolute ID-recognition task. Through anchoring instances to a globally consistent latent space defined by billions of semantic prototypes, we successfully overcome the stochasticity and granularity bottlenecks inherent in existing embedding solutions. Second, we evolved the generative reranker from isolated pointwise evaluation to the compare-and-calibrate listwise policy. By synergizing chunk-based comparative reasoning with calibrated absolute relevance scoring, the system achieves nuanced discriminative resolution while circumventing the prohibitive latency typically associated with conventional reranking methods. Extensive offline benchmarks and online A/B tests on Alibaba e-commerce platform confirm that Pailitao-VL achieves state-of-the-art performance and delivers substantial business impact. This work demonstrates a robust and scalable path for deploying advanced MLLM-based retrieval architectures in demanding, large-scale production environments.
Compression Tells Intelligence: Visual Coding, Visual Token Technology, and the Unification
Jan 28, 2026"Compression Tells Intelligence", is supported by research in artificial intelligence, particularly concerning (multimodal) large language models (LLMs/MLLMs), where compression efficiency often correlates with improved model performance and capabilities. For compression, classical visual coding based on traditional information theory has developed over decades, achieving great success with numerous international industrial standards widely applied in multimedia (e.g., image/video) systems. Except that, the recent emergingvisual token technology of generative multi-modal large models also shares a similar fundamental objective like visual coding: maximizing semantic information fidelity during the representation learning while minimizing computational cost. Therefore, this paper provides a comprehensive overview of two dominant technique families first -- Visual Coding and Vision Token Technology -- then we further unify them from the aspect of optimization, discussing the essence of compression efficiency and model performance trade-off behind. Next, based on the proposed unified formulation bridging visual coding andvisual token technology, we synthesize bidirectional insights of themselves and forecast the next-gen visual codec and token techniques. Last but not least, we experimentally show a large potential of the task-oriented token developments in the more practical tasks like multimodal LLMs (MLLMs), AI-generated content (AIGC), and embodied AI, as well as shedding light on the future possibility of standardizing a general token technology like the traditional codecs (e.g., H.264/265) with high efficiency for a wide range of intelligent tasks in a unified and effective manner.
Understanding Chain-of-Thought in Large Language Models via Topological Data Analysis
Dec 22, 2025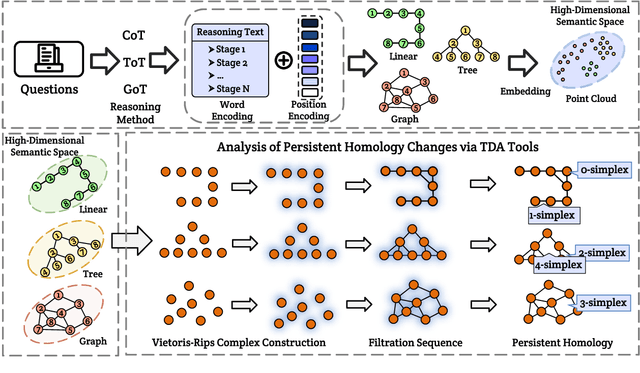
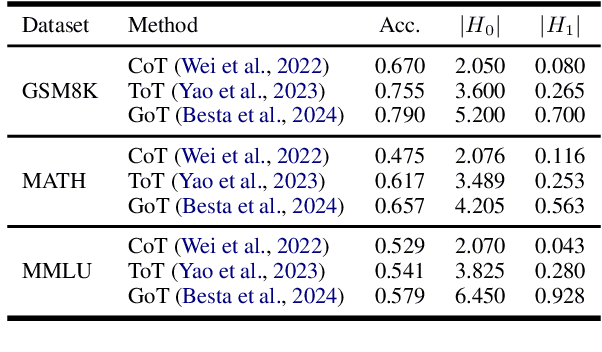
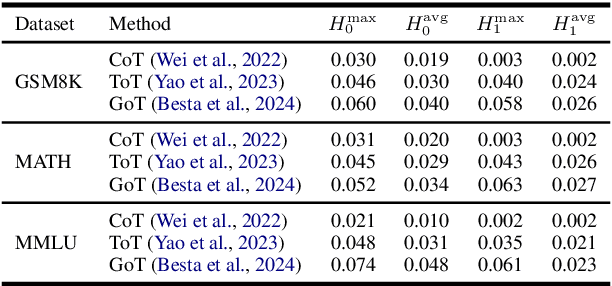
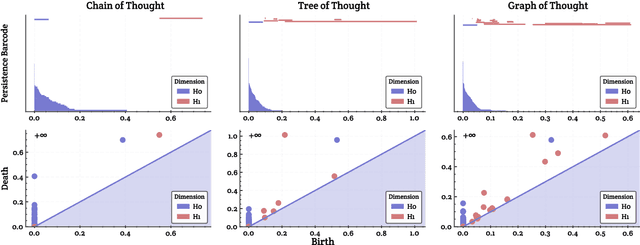
With the development of large language models (LLMs), particularly with the introduction of the long reasoning chain technique, the reasoning ability of LLMs in complex problem-solving has been significantly enhanced. While acknowledging the power of long reasoning chains, we cannot help but wonder: Why do different reasoning chains perform differently in reasoning? What components of the reasoning chains play a key role? Existing studies mainly focus on evaluating reasoning chains from a functional perspective, with little attention paid to their structural mechanisms. To address this gap, this work is the first to analyze and evaluate the quality of the reasoning chain from a structural perspective. We apply persistent homology from Topological Data Analysis (TDA) to map reasoning steps into semantic space, extract topological features, and analyze structural changes. These changes reveal semantic coherence, logical redundancy, and identify logical breaks and gaps. By calculating homology groups, we assess connectivity and redundancy at various scales, using barcode and persistence diagrams to quantify stability and consistency. Our results show that the topological structural complexity of reasoning chains correlates positively with accuracy. More complex chains identify correct answers sooner, while successful reasoning exhibits simpler topologies, reducing redundancy and cycles, enhancing efficiency and interpretability. This work provides a new perspective on reasoning chain quality assessment and offers guidance for future optimization.
START: Traversing Sparse Footholds with Terrain Reconstruction
Dec 15, 2025

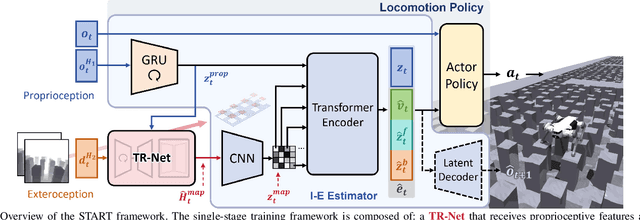
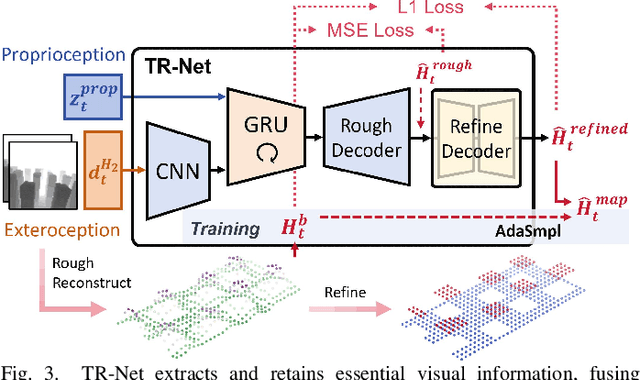
Traversing terrains with sparse footholds like legged animals presents a promising yet challenging task for quadruped robots, as it requires precise environmental perception and agile control to secure safe foot placement while maintaining dynamic stability. Model-based hierarchical controllers excel in laboratory settings, but suffer from limited generalization and overly conservative behaviors. End-to-end learning-based approaches unlock greater flexibility and adaptability, but existing state-of-the-art methods either rely on heightmaps that introduce noise and complex, costly pipelines, or implicitly infer terrain features from egocentric depth images, often missing accurate critical geometric cues and leading to inefficient learning and rigid gaits. To overcome these limitations, we propose START, a single-stage learning framework that enables agile, stable locomotion on highly sparse and randomized footholds. START leverages only low-cost onboard vision and proprioception to accurately reconstruct local terrain heightmap, providing an explicit intermediate representation to convey essential features relevant to sparse foothold regions. This supports comprehensive environmental understanding and precise terrain assessment, reducing exploration cost and accelerating skill acquisition. Experimental results demonstrate that START achieves zero-shot transfer across diverse real-world scenarios, showcasing superior adaptability, precise foothold placement, and robust locomotion.
Robot Learning from a Physical World Model
Nov 10, 2025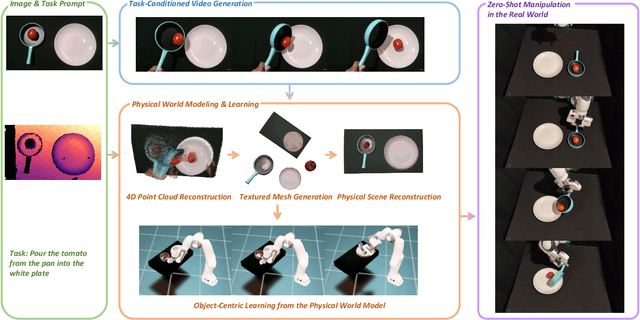

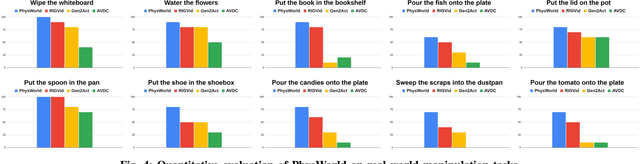

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.