 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised High Dynamic Range Image Reconstructing via Bi-Level Uncertain Area Masking
Nov 17, 2025Reconstructing high dynamic range (HDR) images from low dynamic range (LDR) bursts plays an essential role in the computational photography. Impressive progress has been achieved by learning-based algorithms which require LDR-HDR image pairs. However, these pairs are hard to obtain, which motivates researchers to delve into the problem of annotation-efficient HDR image reconstructing: how to achieve comparable performance with limited HDR ground truths (GTs). This work attempts to address this problem from the view of semi-supervised learning where a teacher model generates pseudo HDR GTs for the LDR samples without GTs and a student model learns from pseudo GTs. Nevertheless, the confirmation bias, i.e., the student may learn from the artifacts in pseudo HDR GTs, presents an impediment. To remove this impediment, an uncertainty-based masking process is proposed to discard unreliable parts of pseudo GTs at both pixel and patch levels, then the trusted areas can be learned from by the student. With this novel masking process, our semi-supervised HDR reconstructing method not only outperforms previous annotation-efficient algorithms, but also achieves comparable performance with up-to-date fully-supervised methods by using only 6.7% HDR GTs.
Fixed-Length Dense Fingerprint Representation
May 06, 2025Fixed-length fingerprint representations, which map each fingerprint to a compact and fixed-size feature vector, are computationally efficient and well-suited for large-scale matching. However, designing a robust representation that effectively handles diverse fingerprint modalities, pose variations, and noise interference remains a significant challenge. In this work, we propose a fixed-length dense descriptor of fingerprints, and introduce FLARE-a fingerprint matching framework that integrates the Fixed-Length dense descriptor with pose-based Alignment and Robust Enhancement. This fixed-length representation employs a three-dimensional dense descriptor to effectively capture spatial relationships among fingerprint ridge structures, enabling robust and locally discriminative representations. To ensure consistency within this dense feature space, FLARE incorporates pose-based alignment using complementary estimation methods, along with dual enhancement strategies that refine ridge clarity while preserving the original fingerprint modality. The proposed dense descriptor supports fixed-length representation while maintaining spatial correspondence, enabling fast and accurate similarity computation. Extensive experiments demonstrate that FLARE achieves superior performance across rolled, plain, latent, and contactless fingerprints, significantly outperforming existing methods in cross-modality and low-quality scenarios. Further analysis validates the effectiveness of the dense descriptor design, as well as the impact of alignment and enhancement modules on the accuracy of dense descriptor matching. Experimental results highlight the effectiveness and generalizability of FLARE as a unified and scalable solution for robust fingerprint representation and matching. The implementation and code will be publicly available at https://github.com/Yu-Yy/FLARE.
Finger Pose Estimation for Under-screen Fingerprint Sensor
May 05, 2025Two-dimensional pose estimation plays a crucial role in fingerprint recognition by facilitating global alignment and reduce pose-induced variations. However, existing methods are still unsatisfactory when handling with large angle or small area inputs. These limitations are particularly pronounced on fingerprints captured by under-screen fingerprint sensors in smartphones. In this paper, we present a novel dual-modal input based network for under-screen fingerprint pose estimation. Our approach effectively integrates two distinct yet complementary modalities: texture details extracted from ridge patches through the under-screen fingerprint sensor, and rough contours derived from capacitive images obtained via the touch screen. This collaborative integration endows our network with more comprehensive and discriminative information, substantially improving the accuracy and stability of pose estimation. A decoupled probability distribution prediction task is designed, instead of the traditional supervised forms of numerical regression or heatmap voting, to facilitate the training process. Additionally, we incorporate a Mixture of Experts (MoE) based feature fusion mechanism and a relationship driven cross-domain knowledge transfer strategy to further strengthen feature extraction and fusion capabilities. Extensive experiments are conducted on several public datasets and two private datasets. The results indicate that our method is significantly superior to previous state-of-the-art (SOTA) methods and remarkably boosts the recognition ability of fingerprint recognition algorithms. Our code is available at https://github.com/XiongjunGuan/DRACO.
Exploring Contextual Attribute Density in Referring Expression Counting
Mar 16, 2025
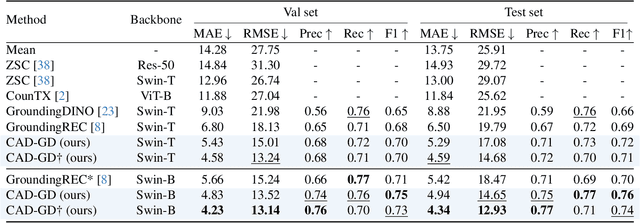
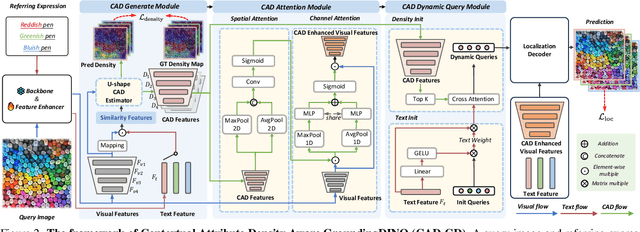
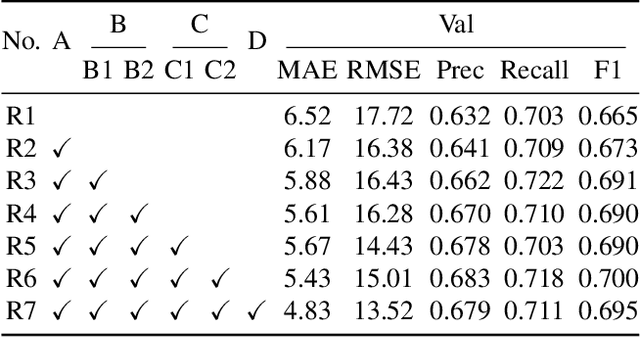
Referring expression counting (REC) algorithms are for more flexible and interactive counting ability across varied fine-grained text expressions. However, the requirement for fine-grained attribute understanding poses challenges for prior arts, as they struggle to accurately align attribute information with correct visual patterns. Given the proven importance of ''visual density'', it is presumed that the limitations of current REC approaches stem from an under-exploration of ''contextual attribute density'' (CAD). In the scope of REC, we define CAD as the measure of the information intensity of one certain fine-grained attribute in visual regions. To model the CAD, we propose a U-shape CAD estimator in which referring expression and multi-scale visual features from GroundingDINO can interact with each other. With additional density supervision, we can effectively encode CAD, which is subsequently decoded via a novel attention procedure with CAD-refined queries. Integrating all these contributions, our framework significantly outperforms state-of-the-art REC methods, achieves $30\%$ error reduction in counting metrics and a $10\%$ improvement in localization accuracy. The surprising results shed light on the significance of contextual attribute density for REC. Code will be at github.com/Xu3XiWang/CAD-GD.
Exposure Completing for Temporally Consistent Neural High Dynamic Range Video Rendering
Jul 18, 2024High dynamic range (HDR) video rendering from low dynamic range (LDR) videos where frames are of alternate exposure encounters significant challenges, due to the exposure change and absence at each time stamp. The exposure change and absence make existing methods generate flickering HDR results. In this paper, we propose a novel paradigm to render HDR frames via completing the absent exposure information, hence the exposure information is complete and consistent. Our approach involves interpolating neighbor LDR frames in the time dimension to reconstruct LDR frames for the absent exposures. Combining the interpolated and given LDR frames, the complete set of exposure information is available at each time stamp. This benefits the fusing process for HDR results, reducing noise and ghosting artifacts therefore improving temporal consistency. Extensive experimental evaluations on standard benchmarks demonstrate that our method achieves state-of-the-art performance, highlighting the importance of absent exposure completing in HDR video rendering. The code is available at https://github.com/cuijiahao666/NECHDR.
Camera-LiDAR Cross-modality Gait Recognition
Jul 03, 2024

Gait recognition is a crucial biometric identification technique. Camera-based gait recognition has been widely applied in both research and industrial fields. LiDAR-based gait recognition has also begun to evolve most recently, due to the provision of 3D structural information. However, in certain applications, cameras fail to recognize persons, such as in low-light environments and long-distance recognition scenarios, where LiDARs work well. On the other hand, the deployment cost and complexity of LiDAR systems limit its wider application. Therefore, it is essential to consider cross-modality gait recognition between cameras and LiDARs for a broader range of applications. In this work, we propose the first cross-modality gait recognition framework between Camera and LiDAR, namely CL-Gait. It employs a two-stream network for feature embedding of both modalities. This poses a challenging recognition task due to the inherent matching between 3D and 2D data, exhibiting significant modality discrepancy. To align the feature spaces of the two modalities, i.e., camera silhouettes and LiDAR points, we propose a contrastive pre-training strategy to mitigate modality discrepancy. To make up for the absence of paired camera-LiDAR data for pre-training, we also introduce a strategy for generating data on a large scale. This strategy utilizes monocular depth estimated from single RGB images and virtual cameras to generate pseudo point clouds for contrastive pre-training. Extensive experiments show that the cross-modality gait recognition is very challenging but still contains potential and feasibility with our proposed model and pre-training strategy. To the best of our knowledge, this is the first work to address cross-modality gait recognition.
Pseudo-Labeling by Multi-Policy Viewfinder Network for Image Cropping
Jul 02, 2024



Automatic image cropping models predict reframing boxes to enhance image aesthetics. Yet, the scarcity of labeled data hinders the progress of this task. To overcome this limitation, we explore the possibility of utilizing both labeled and unlabeled data together to expand the scale of training data for image cropping models. This idea can be implemented in a pseudo-labeling way: producing pseudo labels for unlabeled data by a teacher model and training a student model with these pseudo labels. However, the student may learn from teacher's mistakes. To address this issue, we propose the multi-policy viewfinder network (MPV-Net) that offers diverse refining policies to rectify the mistakes in original pseudo labels from the teacher. The most reliable policy is selected to generate trusted pseudo labels. The reliability of policies is evaluated via the robustness against box jittering. The efficacy of our method can be evaluated by the improvement compared to the supervised baseline which only uses labeled data. Notably, our MPV-Net outperforms off-the-shelf pseudo-labeling methods, yielding the most substantial improvement over the supervised baseline. Furthermore, our approach achieves state-of-the-art results on both the FCDB and FLMS datasets, signifying the superiority of our approach.
Instance Consistency Regularization for Semi-Supervised 3D Instance Segmentation
Jun 24, 2024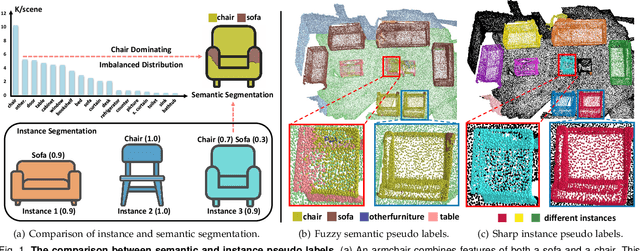
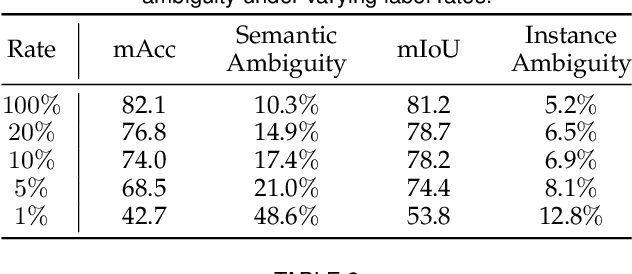
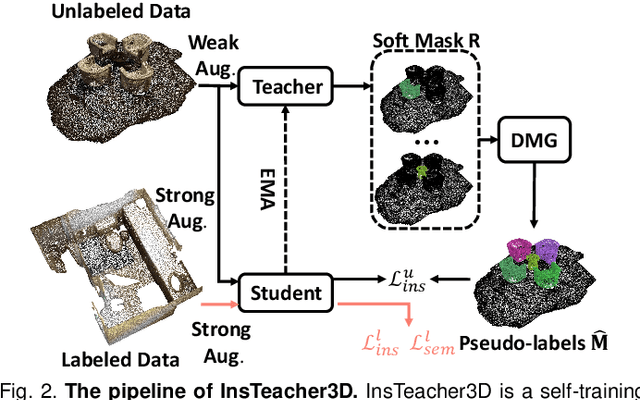

Large-scale datasets with point-wise semantic and instance labels are crucial to 3D instance segmentation but also expensive. To leverage unlabeled data, previous semi-supervised 3D instance segmentation approaches have explored self-training frameworks, which rely on high-quality pseudo labels for consistency regularization. They intuitively utilize both instance and semantic pseudo labels in a joint learning manner. However, semantic pseudo labels contain numerous noise derived from the imbalanced category distribution and natural confusion of similar but distinct categories, which leads to severe collapses in self-training. Motivated by the observation that 3D instances are non-overlapping and spatially separable, we ask whether we can solely rely on instance consistency regularization for improved semi-supervised segmentation. To this end, we propose a novel self-training network InsTeacher3D to explore and exploit pure instance knowledge from unlabeled data. We first build a parallel base 3D instance segmentation model DKNet, which distinguishes each instance from the others via discriminative instance kernels without reliance on semantic segmentation. Based on DKNet, we further design a novel instance consistency regularization framework to generate and leverage high-quality instance pseudo labels. Experimental results on multiple large-scale datasets show that the InsTeacher3D significantly outperforms prior state-of-the-art semi-supervised approaches. Code is available: https://github.com/W1zheng/InsTeacher3D.
Robust Stable Spiking Neural Networks
May 31, 2024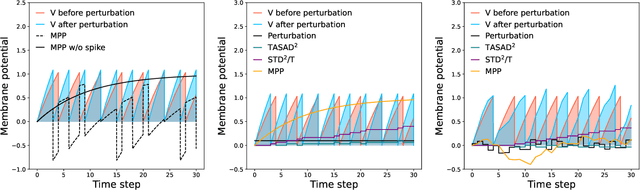
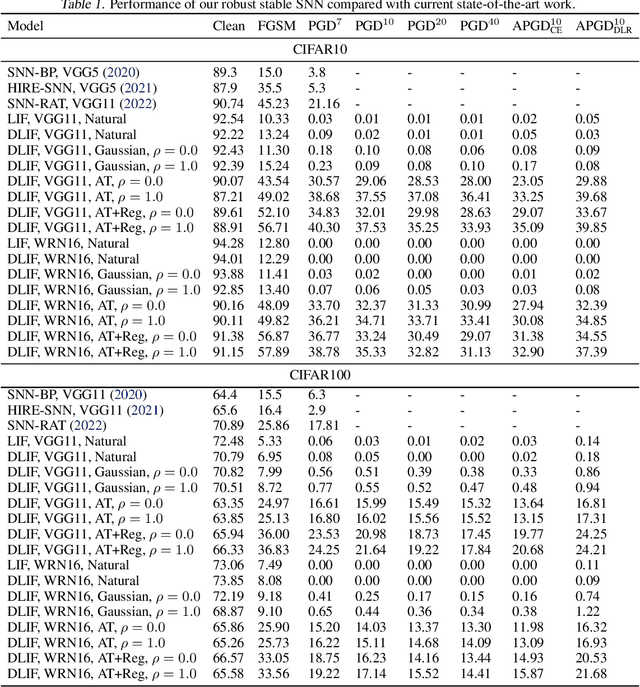
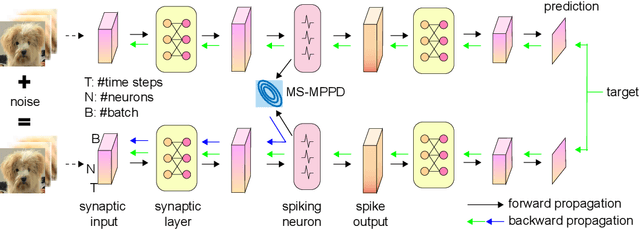
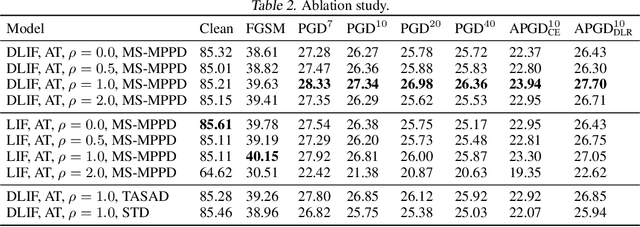
Spiking neural networks (SNNs) are gaining popularity in deep learning due to their low energy budget on neuromorphic hardware. However, they still face challenges in lacking sufficient robustness to guard safety-critical applications such as autonomous driving. Many studies have been conducted to defend SNNs from the threat of adversarial attacks. This paper aims to uncover the robustness of SNN through the lens of the stability of nonlinear systems. We are inspired by the fact that searching for parameters altering the leaky integrate-and-fire dynamics can enhance their robustness. Thus, we dive into the dynamics of membrane potential perturbation and simplify the formulation of the dynamics. We present that membrane potential perturbation dynamics can reliably convey the intensity of perturbation. Our theoretical analyses imply that the simplified perturbation dynamics satisfy input-output stability. Thus, we propose a training framework with modified SNN neurons and to reduce the mean square of membrane potential perturbation aiming at enhancing the robustness of SNN. Finally, we experimentally verify the effectiveness of the framework in the setting of Gaussian noise training and adversarial training on the image classification task.
Joint Estimation of Identity Verification and Relative Pose for Partial Fingerprints
May 07, 2024



Currently, portable electronic devices are becoming more and more popular. For lightweight considerations, their fingerprint recognition modules usually use limited-size sensors. However, partial fingerprints have few matchable features, especially when there are differences in finger pressing posture or image quality, which makes partial fingerprint verification challenging. Most existing methods regard fingerprint position rectification and identity verification as independent tasks, ignoring the coupling relationship between them -- relative pose estimation typically relies on paired features as anchors, and authentication accuracy tends to improve with more precise pose alignment. Consequently, in this paper we propose a method that jointly estimates identity verification and relative pose for partial fingerprints, aiming to leverage their inherent correlation to improve each other. To achieve this, we propose a multi-task CNN (Convolutional Neural Network)-Transformer hybrid network, and design a pre-training task to enhance the feature extraction capability. Experiments on multiple public datasets (NIST SD14, FVC2002 DB1A & DB3A, FVC2004 DB1A & DB2A, FVC2006 DB1A) and an in-house dataset show that our method achieves state-of-the-art performance in both partial fingerprint verification and relative pose estimation, while being more efficient than previous methods.