 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHRC-Bench: A Multilingual Hardware Repository-Level Code Completion benchmark
Jan 07, 2026Large language models (LLMs) have achieved strong performance on code completion tasks in general-purpose programming languages. However, existing repository-level code completion benchmarks focus almost exclusively on software code and largely overlook hardware description languages. In this work, we present \textbf{MHRC-Bench}, consisting of \textbf{MHRC-Bench-Train} and \textbf{MHRC-Bench-Eval}, the first benchmark designed for multilingual hardware code completion at the repository level. Our benchmark targets completion tasks and covers three major hardware design coding styles. Each completion target is annotated with code-structure-level and hardware-oriented semantic labels derived from concrete syntax tree analysis. We conduct a comprehensive evaluation of models on MHRC-Bench-Eval. Comprehensive evaluation results and analysis demonstrate the effectiveness of MHRC-Bench.
Semi-Supervised High Dynamic Range Image Reconstructing via Bi-Level Uncertain Area Masking
Nov 17, 2025Reconstructing high dynamic range (HDR) images from low dynamic range (LDR) bursts plays an essential role in the computational photography. Impressive progress has been achieved by learning-based algorithms which require LDR-HDR image pairs. However, these pairs are hard to obtain, which motivates researchers to delve into the problem of annotation-efficient HDR image reconstructing: how to achieve comparable performance with limited HDR ground truths (GTs). This work attempts to address this problem from the view of semi-supervised learning where a teacher model generates pseudo HDR GTs for the LDR samples without GTs and a student model learns from pseudo GTs. Nevertheless, the confirmation bias, i.e., the student may learn from the artifacts in pseudo HDR GTs, presents an impediment. To remove this impediment, an uncertainty-based masking process is proposed to discard unreliable parts of pseudo GTs at both pixel and patch levels, then the trusted areas can be learned from by the student. With this novel masking process, our semi-supervised HDR reconstructing method not only outperforms previous annotation-efficient algorithms, but also achieves comparable performance with up-to-date fully-supervised methods by using only 6.7% HDR GTs.
Hallo4: High-Fidelity Dynamic Portrait Animation via Direct Preference Optimization and Temporal Motion Modulation
May 29, 2025Generating highly dynamic and photorealistic portrait animations driven by audio and skeletal motion remains challenging due to the need for precise lip synchronization, natural facial expressions, and high-fidelity body motion dynamics. We propose a human-preference-aligned diffusion framework that addresses these challenges through two key innovations. First, we introduce direct preference optimization tailored for human-centric animation, leveraging a curated dataset of human preferences to align generated outputs with perceptual metrics for portrait motion-video alignment and naturalness of expression. Second, the proposed temporal motion modulation resolves spatiotemporal resolution mismatches by reshaping motion conditions into dimensionally aligned latent features through temporal channel redistribution and proportional feature expansion, preserving the fidelity of high-frequency motion details in diffusion-based synthesis. The proposed mechanism is complementary to existing UNet and DiT-based portrait diffusion approaches, and experiments demonstrate obvious improvements in lip-audio synchronization, expression vividness, body motion coherence over baseline methods, alongside notable gains in human preference metrics. Our model and source code can be found at: https://github.com/xyz123xyz456/hallo4.
Dynamic Arthroscopic Navigation System for Anterior Cruciate Ligament Reconstruction Based on Multi-level Memory Architecture
Apr 28, 2025This paper presents a dynamic arthroscopic navigation system based on multi-level memory architecture for anterior cruciate ligament (ACL) reconstruction surgery. The system extends our previously proposed markerless navigation method from static image matching to dynamic video sequence tracking. By integrating the Atkinson-Shiffrin memory model's three-level architecture (sensory memory, working memory, and long-term memory), our system maintains continuous tracking of the femoral condyle throughout the surgical procedure, providing stable navigation support even in complex situations involving viewpoint changes, instrument occlusion, and tissue deformation. Unlike existing methods, our system operates in real-time on standard arthroscopic equipment without requiring additional tracking hardware, achieving 25.3 FPS with a latency of only 39.5 ms, representing a 3.5-fold improvement over our previous static system. For extended sequences (1000 frames), the dynamic system maintained an error of 5.3 plus-minus 1.5 pixels, compared to the static system's 12.6 plus-minus 3.7 pixels - an improvement of approximately 45 percent. For medium-length sequences (500 frames) and short sequences (100 frames), the system achieved approximately 35 percent and 19 percent accuracy improvements, respectively. Experimental results demonstrate the system overcomes limitations of traditional static matching methods, providing new technical support for improving surgical precision in ACL reconstruction.
Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Diffusion Transformer Networks
Dec 01, 2024Existing methodologies for animating portrait images face significant challenges, particularly in handling non-frontal perspectives, rendering dynamic objects around the portrait, and generating immersive, realistic backgrounds. In this paper, we introduce the first application of a pretrained transformer-based video generative model that demonstrates strong generalization capabilities and generates highly dynamic, realistic videos for portrait animation, effectively addressing these challenges. The adoption of a new video backbone model makes previous U-Net-based methods for identity maintenance, audio conditioning, and video extrapolation inapplicable. To address this limitation, we design an identity reference network consisting of a causal 3D VAE combined with a stacked series of transformer layers, ensuring consistent facial identity across video sequences. Additionally, we investigate various speech audio conditioning and motion frame mechanisms to enable the generation of continuous video driven by speech audio. Our method is validated through experiments on benchmark and newly proposed wild datasets, demonstrating substantial improvements over prior methods in generating realistic portraits characterized by diverse orientations within dynamic and immersive scenes. Further visualizations and the source code are available at: https://github.com/fudan-generative-vision/hallo3.
Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
Oct 10, 2024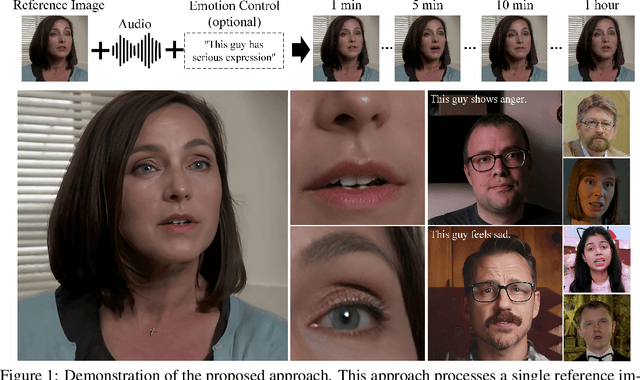


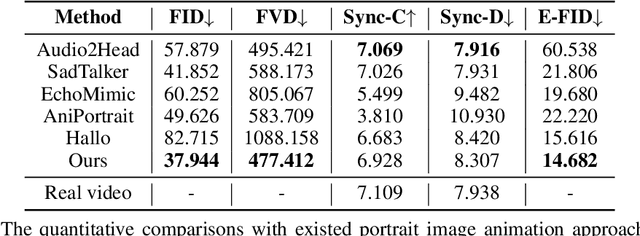
Recent advances in latent diffusion-based generative models for portrait image animation, such as Hallo, have achieved impressive results in short-duration video synthesis. In this paper, we present updates to Hallo, introducing several design enhancements to extend its capabilities. First, we extend the method to produce long-duration videos. To address substantial challenges such as appearance drift and temporal artifacts, we investigate augmentation strategies within the image space of conditional motion frames. Specifically, we introduce a patch-drop technique augmented with Gaussian noise to enhance visual consistency and temporal coherence over long duration. Second, we achieve 4K resolution portrait video generation. To accomplish this, we implement vector quantization of latent codes and apply temporal alignment techniques to maintain coherence across the temporal dimension. By integrating a high-quality decoder, we realize visual synthesis at 4K resolution. Third, we incorporate adjustable semantic textual labels for portrait expressions as conditional inputs. This extends beyond traditional audio cues to improve controllability and increase the diversity of the generated content. To the best of our knowledge, Hallo2, proposed in this paper, is the first method to achieve 4K resolution and generate hour-long, audio-driven portrait image animations enhanced with textual prompts. We have conducted extensive experiments to evaluate our method on publicly available datasets, including HDTF, CelebV, and our introduced "Wild" dataset. The experimental results demonstrate that our approach achieves state-of-the-art performance in long-duration portrait video animation, successfully generating rich and controllable content at 4K resolution for duration extending up to tens of minutes. Project page https://fudan-generative-vision.github.io/hallo2
Exposure Completing for Temporally Consistent Neural High Dynamic Range Video Rendering
Jul 18, 2024High dynamic range (HDR) video rendering from low dynamic range (LDR) videos where frames are of alternate exposure encounters significant challenges, due to the exposure change and absence at each time stamp. The exposure change and absence make existing methods generate flickering HDR results. In this paper, we propose a novel paradigm to render HDR frames via completing the absent exposure information, hence the exposure information is complete and consistent. Our approach involves interpolating neighbor LDR frames in the time dimension to reconstruct LDR frames for the absent exposures. Combining the interpolated and given LDR frames, the complete set of exposure information is available at each time stamp. This benefits the fusing process for HDR results, reducing noise and ghosting artifacts therefore improving temporal consistency. Extensive experimental evaluations on standard benchmarks demonstrate that our method achieves state-of-the-art performance, highlighting the importance of absent exposure completing in HDR video rendering. The code is available at https://github.com/cuijiahao666/NECHDR.
Pseudo-Labeling by Multi-Policy Viewfinder Network for Image Cropping
Jul 02, 2024



Automatic image cropping models predict reframing boxes to enhance image aesthetics. Yet, the scarcity of labeled data hinders the progress of this task. To overcome this limitation, we explore the possibility of utilizing both labeled and unlabeled data together to expand the scale of training data for image cropping models. This idea can be implemented in a pseudo-labeling way: producing pseudo labels for unlabeled data by a teacher model and training a student model with these pseudo labels. However, the student may learn from teacher's mistakes. To address this issue, we propose the multi-policy viewfinder network (MPV-Net) that offers diverse refining policies to rectify the mistakes in original pseudo labels from the teacher. The most reliable policy is selected to generate trusted pseudo labels. The reliability of policies is evaluated via the robustness against box jittering. The efficacy of our method can be evaluated by the improvement compared to the supervised baseline which only uses labeled data. Notably, our MPV-Net outperforms off-the-shelf pseudo-labeling methods, yielding the most substantial improvement over the supervised baseline. Furthermore, our approach achieves state-of-the-art results on both the FCDB and FLMS datasets, signifying the superiority of our approach.
Instance Consistency Regularization for Semi-Supervised 3D Instance Segmentation
Jun 24, 2024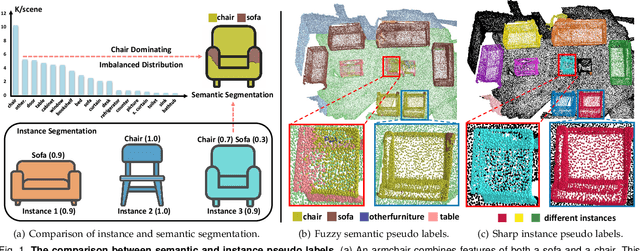
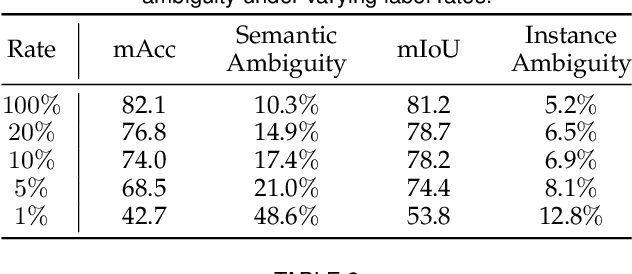
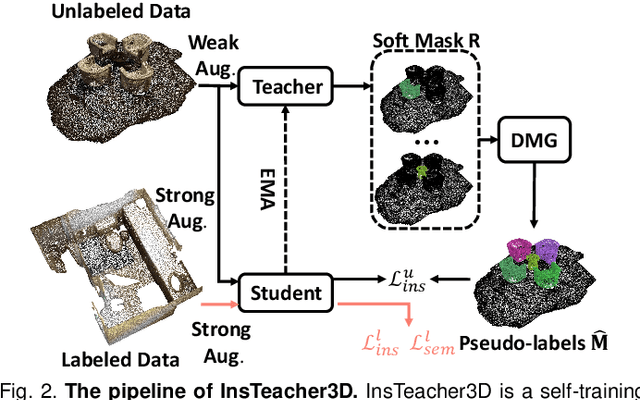

Large-scale datasets with point-wise semantic and instance labels are crucial to 3D instance segmentation but also expensive. To leverage unlabeled data, previous semi-supervised 3D instance segmentation approaches have explored self-training frameworks, which rely on high-quality pseudo labels for consistency regularization. They intuitively utilize both instance and semantic pseudo labels in a joint learning manner. However, semantic pseudo labels contain numerous noise derived from the imbalanced category distribution and natural confusion of similar but distinct categories, which leads to severe collapses in self-training. Motivated by the observation that 3D instances are non-overlapping and spatially separable, we ask whether we can solely rely on instance consistency regularization for improved semi-supervised segmentation. To this end, we propose a novel self-training network InsTeacher3D to explore and exploit pure instance knowledge from unlabeled data. We first build a parallel base 3D instance segmentation model DKNet, which distinguishes each instance from the others via discriminative instance kernels without reliance on semantic segmentation. Based on DKNet, we further design a novel instance consistency regularization framework to generate and leverage high-quality instance pseudo labels. Experimental results on multiple large-scale datasets show that the InsTeacher3D significantly outperforms prior state-of-the-art semi-supervised approaches. Code is available: https://github.com/W1zheng/InsTeacher3D.
SAR-AE-SFP: SAR Imagery Adversarial Example in Real Physics domain with Target Scattering Feature Parameters
Mar 02, 2024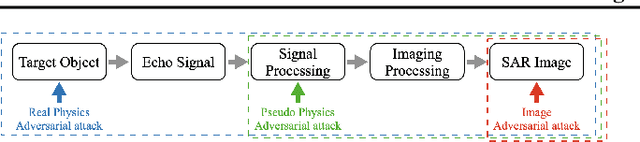



Deep neural network-based Synthetic Aperture Radar (SAR) target recognition models are susceptible to adversarial examples. Current adversarial example generation methods for SAR imagery primarily operate in the 2D digital domain, known as image adversarial examples. Recent work, while considering SAR imaging scatter mechanisms, fails to account for the actual imaging process, rendering attacks in the three-dimensional physical domain infeasible, termed pseudo physics adversarial examples. To address these challenges, this paper proposes SAR-AE-SFP-Attack, a method to generate real physics adversarial examples by altering the scattering feature parameters of target objects. Specifically, we iteratively optimize the coherent energy accumulation of the target echo by perturbing the reflection coefficient and scattering coefficient in the scattering feature parameters of the three-dimensional target object, and obtain the adversarial example after echo signal processing and imaging processing in the RaySAR simulator. Experimental results show that compared to digital adversarial attack methods, SAR-AE-SFP Attack significantly improves attack efficiency on CNN-based models (over 30\%) and Transformer-based models (over 13\%), demonstrating significant transferability of attack effects across different models and perspectives.