 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiGSP:Implicit Gradient Subspace Projection for Efficient Continual Learning of Vision-Language Models
May 19, 2026Vision-Language Models require efficient adaptation to continually emerging downstream tasks. While Parameter-Efficient Fine-Tuning mitigates catastrophic forgetting, assigning isolated modules per task leads to parameter explosion. Conversely, recent similarity-driven sharing mechanisms falsely equate superficial visual similarity with underlying alignment consistency. This fundamental mismatch triggers severe negative transfer between visually similar but logically distinct tasks and fails to exploit alignment reuse across visually diverse ones. We argue thatalignment sharing is fundamentally a geometric problem of overlapping optimization trajectories within shared low-rank subspaces. Grounded in this insight, we propose iGSP, a novel framework that achieves efficient adaptation via implicit gradient subspace projection. Leveraging the early convergence of MoE routers to establish the subspace basis, iGSP bifurcates the adaptation process into two phases. First, the Subspace Identification phase introduces candidate experts via basis pre-expansion, applies a novel subspace-constrained regularization to implicitly project new task gradients onto the historical subspace, and precisely prunes redundant dimensions by treating routing probabilities as gradient flow indicators, ultimately to maximize knowledge reuse. Second, the Orthogonal Subspace Fine-Tuning phase fixes this structural basis and removes the regularization to rapidly fit the task-specific residual loss. Extensive experiments on the MTIL benchmark demonstrate that iGSP achieves state-of-the-art accuracy while significantly improving training efficiency, reducing the average trainable parameters by 42.7\% compared to current SOTA methods, and decreasing the final total parameters by 86.9\% relative to counterparts. The source code is available at https://github.com/GeoX-Lab/iGSP.
RS-HyRe-R1: A Hybrid Reward Mechanism to Overcome Perceptual Inertia for Remote Sensing Images Understanding
Apr 19, 2026Reinforcement learning (RL) post-training substantially improves remote sensing vision-language models (RS-VLMs). However, when handling complex remote sensing imagery (RSI) requiring exhaustive visual scanning, models tend to rely on localized salient cues for rapid inference. We term this RL-induced bias "perceptual inertia". Driven by reward maximization, models favor quick outcome fitting, leading to two limitations: cognitively, overreliance on specific features impedes complete evidence construction; operationally, models struggle to flexibly shift visual focus across tasks. To address this bias and encourage comprehensive visual evidence mining, we propose RS-HyRe-R1, a hybrid reward framework for RSI understanding. It introduces: (1) a spatial reasoning activation reward that enforces structured visual reasoning; (2) a perception correctness reward that provides adaptive quality anchors across RS tasks, ensuring accurate geometric and semantic alignment; and (3) a visual-semantic path evolution reward that penalizes repetitive reasoning and promotes exploration of complementary cues to build richer evidence chains. Experiments show RS-HyRe-R1 effectively mitigates "perceptual inertia", encouraging deeper, more diverse reasoning. With only 3B parameters, it achieves state-of-the-art performance on REC, OVD, and VQA tasks, outperforming models up to 7B parameters. It also demonstrates strong zero-shot generalization, surpassing the second-best model by 3.16%, 3.97%, and 2.72% on VQA, OVD, and REC, respectively. Code and datasets are available at https://github.com/geox-lab/RS-HyRe-R1.
Remote Sensing Image Intelligent Interpretation with the Language-Centered Perspective: Principles, Methods and Challenges
Aug 09, 2025



The mainstream paradigm of remote sensing image interpretation has long been dominated by vision-centered models, which rely on visual features for semantic understanding. However, these models face inherent limitations in handling multi-modal reasoning, semantic abstraction, and interactive decision-making. While recent advances have introduced Large Language Models (LLMs) into remote sensing workflows, existing studies primarily focus on downstream applications, lacking a unified theoretical framework that explains the cognitive role of language. This review advocates a paradigm shift from vision-centered to language-centered remote sensing interpretation. Drawing inspiration from the Global Workspace Theory (GWT) of human cognition, We propose a language-centered framework for remote sensing interpretation that treats LLMs as the cognitive central hub integrating perceptual, task, knowledge and action spaces to enable unified understanding, reasoning, and decision-making. We first explore the potential of LLMs as the central cognitive component in remote sensing interpretation, and then summarize core technical challenges, including unified multimodal representation, knowledge association, and reasoning and decision-making. Furthermore, we construct a global workspace-driven interpretation mechanism and review how language-centered solutions address each challenge. Finally, we outline future research directions from four perspectives: adaptive alignment of multimodal data, task understanding under dynamic knowledge constraints, trustworthy reasoning, and autonomous interaction. This work aims to provide a conceptual foundation for the next generation of remote sensing interpretation systems and establish a roadmap toward cognition-driven intelligent geospatial analysis.
RS-GPT4V: A Unified Multimodal Instruction-Following Dataset for Remote Sensing Image Understanding
Jun 18, 2024The remote sensing image intelligence understanding model is undergoing a new profound paradigm shift which has been promoted by multi-modal large language model (MLLM), i.e. from the paradigm learning a domain model (LaDM) shifts to paradigm learning a pre-trained general foundation model followed by an adaptive domain model (LaGD). Under the new LaGD paradigm, the old datasets, which have led to advances in RSI intelligence understanding in the last decade, are no longer suitable for fire-new tasks. We argued that a new dataset must be designed to lighten tasks with the following features: 1) Generalization: training model to learn shared knowledge among tasks and to adapt to different tasks; 2) Understanding complex scenes: training model to understand the fine-grained attribute of the objects of interest, and to be able to describe the scene with natural language; 3) Reasoning: training model to be able to realize high-level visual reasoning. In this paper, we designed a high-quality, diversified, and unified multimodal instruction-following dataset for RSI understanding produced by GPT-4V and existing datasets, which we called RS-GPT4V. To achieve generalization, we used a (Question, Answer) which was deduced from GPT-4V via instruction-following to unify the tasks such as captioning and localization; To achieve complex scene, we proposed a hierarchical instruction description with local strategy in which the fine-grained attributes of the objects and their spatial relationships are described and global strategy in which all the local information are integrated to yield detailed instruction descript; To achieve reasoning, we designed multiple-turn QA pair to provide the reasoning ability for a model. The empirical results show that the fine-tuned MLLMs by RS-GPT4V can describe fine-grained information. The dataset is available at: https://github.com/GeoX-Lab/RS-GPT4V.
SAR-AE-SFP: SAR Imagery Adversarial Example in Real Physics domain with Target Scattering Feature Parameters
Mar 02, 2024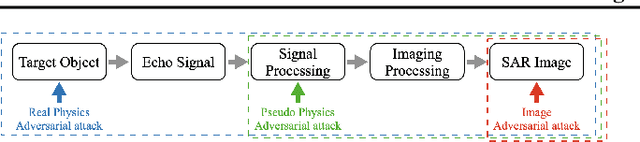



Deep neural network-based Synthetic Aperture Radar (SAR) target recognition models are susceptible to adversarial examples. Current adversarial example generation methods for SAR imagery primarily operate in the 2D digital domain, known as image adversarial examples. Recent work, while considering SAR imaging scatter mechanisms, fails to account for the actual imaging process, rendering attacks in the three-dimensional physical domain infeasible, termed pseudo physics adversarial examples. To address these challenges, this paper proposes SAR-AE-SFP-Attack, a method to generate real physics adversarial examples by altering the scattering feature parameters of target objects. Specifically, we iteratively optimize the coherent energy accumulation of the target echo by perturbing the reflection coefficient and scattering coefficient in the scattering feature parameters of the three-dimensional target object, and obtain the adversarial example after echo signal processing and imaging processing in the RaySAR simulator. Experimental results show that compared to digital adversarial attack methods, SAR-AE-SFP Attack significantly improves attack efficiency on CNN-based models (over 30\%) and Transformer-based models (over 13\%), demonstrating significant transferability of attack effects across different models and perspectives.