 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Apr 15, 2026We introduce HY-World 2.0, a multi-modal world model framework that advances our prior project HY-World 1.0. HY-World 2.0 accommodates diverse input modalities, including text prompts, single-view images, multi-view images, and videos, and produces 3D world representations. With text or single-view image inputs, the model performs world generation, synthesizing high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes. This is achieved through a four-stage method: a) Panorama Generation with HY-Pano 2.0, b) Trajectory Planning with WorldNav, c) World Expansion with WorldStereo 2.0, and d) World Composition with WorldMirror 2.0. Specifically, we introduce key innovations to enhance panorama fidelity, enable 3D scene understanding and planning, and upgrade WorldStereo, our keyframe-based view generation model with consistent memory. We also upgrade WorldMirror, a feed-forward model for universal 3D prediction, by refining model architecture and learning strategy, enabling world reconstruction from multi-view images or videos. Also, we introduce WorldLens, a high-performance 3DGS rendering platform featuring a flexible engine-agnostic architecture, automatic IBL lighting, efficient collision detection, and training-rendering co-design, enabling interactive exploration of 3D worlds with character support. Extensive experiments demonstrate that HY-World 2.0 achieves state-of-the-art performance on several benchmarks among open-source approaches, delivering results comparable to the closed-source model Marble. We release all model weights, code, and technical details to facilitate reproducibility and support further research on 3D world models.
Teaching Language Models to Self-Improve by Learning from Language Feedback
Jun 11, 2024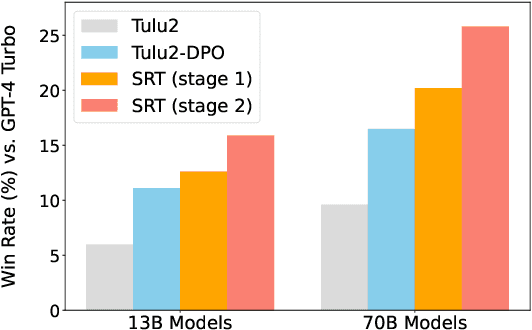

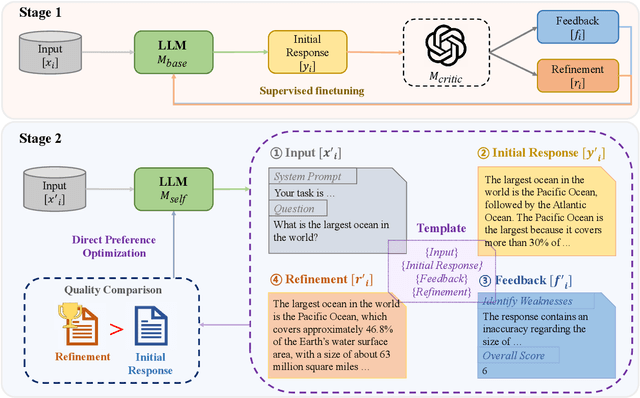

Aligning Large Language Models (LLMs) with human intentions and values is crucial yet challenging. Current methods primarily rely on human preferences, which are costly and insufficient in capturing nuanced feedback expressed in natural language. In this paper, we present Self-Refinement Tuning (SRT), a method that leverages model feedback for alignment, thereby reducing reliance on human annotations. SRT uses a base language model (e.g., Tulu2) to generate initial responses, which are critiqued and refined by a more advanced model (e.g., GPT-4-Turbo). This process enables the base model to self-evaluate and improve its outputs, facilitating continuous learning. SRT further optimizes the model by learning from its self-generated feedback and refinements, creating a feedback loop that promotes model improvement. Our empirical evaluations demonstrate that SRT significantly outperforms strong baselines across diverse tasks and model sizes. When applied to a 70B parameter model, SRT increases the win rate from 9.6\% to 25.8\% on the AlpacaEval 2.0 benchmark, surpassing well-established systems such as GPT-4-0314, Claude 2, and Gemini. Our analysis highlights the crucial role of language feedback in the success of SRT, suggesting potential for further exploration in this direction.
RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners
Mar 22, 2024



Large Language Models (LLMs) have achieved impressive performance across various reasoning tasks. However, even state-of-the-art LLMs such as ChatGPT are prone to logical errors during their reasoning processes. Existing solutions, such as deploying task-specific verifiers or voting over multiple reasoning paths, either require extensive human annotations or fail in scenarios with inconsistent responses. To address these challenges, we introduce RankPrompt, a new prompting method that enables LLMs to self-rank their responses without additional resources. RankPrompt breaks down the ranking problem into a series of comparisons among diverse responses, leveraging the inherent capabilities of LLMs to generate chains of comparison as contextual exemplars. Our experiments across 11 arithmetic and commonsense reasoning tasks show that RankPrompt significantly enhances the reasoning performance of ChatGPT and GPT-4, with improvements of up to 13%. Moreover, RankPrompt excels in LLM-based automatic evaluations for open-ended tasks, aligning with human judgments 74% of the time in the AlpacaEval dataset. It also exhibits robustness to variations in response order and consistency. Collectively, our results validate RankPrompt as an effective method for eliciting high-quality feedback from language models.
SAR-AE-SFP: SAR Imagery Adversarial Example in Real Physics domain with Target Scattering Feature Parameters
Mar 02, 2024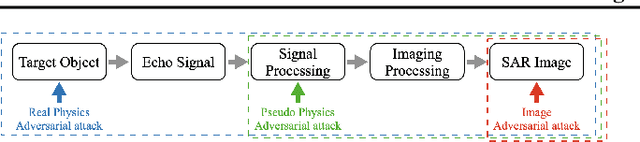



Deep neural network-based Synthetic Aperture Radar (SAR) target recognition models are susceptible to adversarial examples. Current adversarial example generation methods for SAR imagery primarily operate in the 2D digital domain, known as image adversarial examples. Recent work, while considering SAR imaging scatter mechanisms, fails to account for the actual imaging process, rendering attacks in the three-dimensional physical domain infeasible, termed pseudo physics adversarial examples. To address these challenges, this paper proposes SAR-AE-SFP-Attack, a method to generate real physics adversarial examples by altering the scattering feature parameters of target objects. Specifically, we iteratively optimize the coherent energy accumulation of the target echo by perturbing the reflection coefficient and scattering coefficient in the scattering feature parameters of the three-dimensional target object, and obtain the adversarial example after echo signal processing and imaging processing in the RaySAR simulator. Experimental results show that compared to digital adversarial attack methods, SAR-AE-SFP Attack significantly improves attack efficiency on CNN-based models (over 30\%) and Transformer-based models (over 13\%), demonstrating significant transferability of attack effects across different models and perspectives.
The NiuTrans System for the WMT21 Efficiency Task
Sep 16, 2021

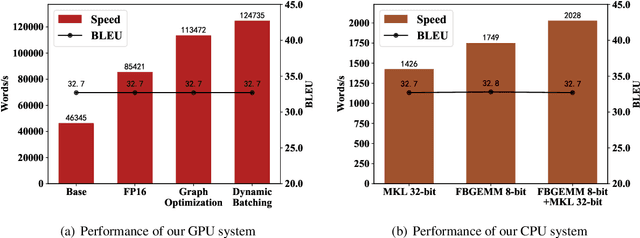
This paper describes the NiuTrans system for the WMT21 translation efficiency task (http://statmt.org/wmt21/efficiency-task.html). Following last year's work, we explore various techniques to improve efficiency while maintaining translation quality. We investigate the combinations of lightweight Transformer architectures and knowledge distillation strategies. Also, we improve the translation efficiency with graph optimization, low precision, dynamic batching, and parallel pre/post-processing. Our system can translate 247,000 words per second on an NVIDIA A100, being 3$\times$ faster than last year's system. Our system is the fastest and has the lowest memory consumption on the GPU-throughput track. The code, model, and pipeline will be available at NiuTrans.NMT (https://github.com/NiuTrans/NiuTrans.NMT).