 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRO: Enhancing Reasoning in Diffusion Language Models via Multi-Reward Optimization
Oct 24, 2025


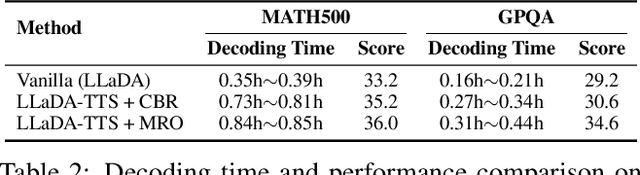
Recent advances in diffusion language models (DLMs) have presented a promising alternative to traditional autoregressive large language models (LLMs). However, DLMs still lag behind LLMs in reasoning performance, especially as the number of denoising steps decreases. Our analysis reveals that this shortcoming arises primarily from the independent generation of masked tokens across denoising steps, which fails to capture the token correlation. In this paper, we define two types of token correlation: intra-sequence correlation and inter-sequence correlation, and demonstrate that enhancing these correlations improves reasoning performance. To this end, we propose a Multi-Reward Optimization (MRO) approach, which encourages DLMs to consider the token correlation during the denoising process. More specifically, our MRO approach leverages test-time scaling, reject sampling, and reinforcement learning to directly optimize the token correlation with multiple elaborate rewards. Additionally, we introduce group step and importance sampling strategies to mitigate reward variance and enhance sampling efficiency. Through extensive experiments, we demonstrate that MRO not only improves reasoning performance but also achieves significant sampling speedups while maintaining high performance on reasoning benchmarks.
Teaching Language Models to Self-Improve by Learning from Language Feedback
Jun 11, 2024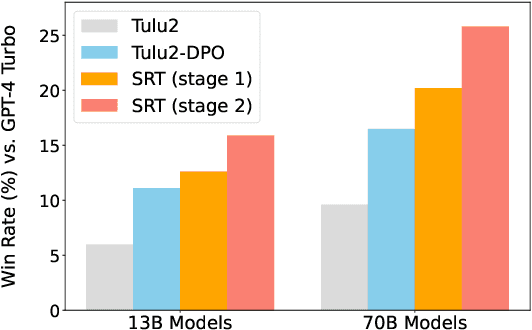

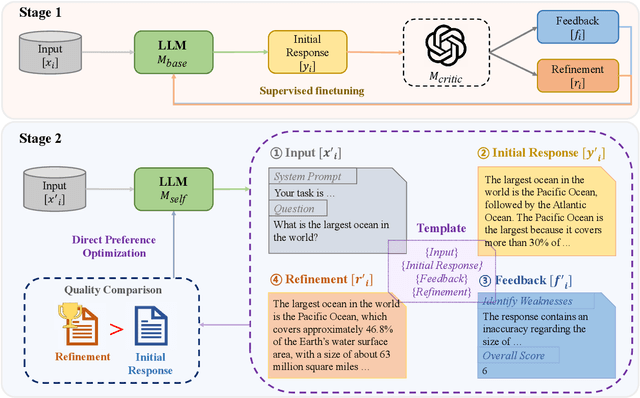

Aligning Large Language Models (LLMs) with human intentions and values is crucial yet challenging. Current methods primarily rely on human preferences, which are costly and insufficient in capturing nuanced feedback expressed in natural language. In this paper, we present Self-Refinement Tuning (SRT), a method that leverages model feedback for alignment, thereby reducing reliance on human annotations. SRT uses a base language model (e.g., Tulu2) to generate initial responses, which are critiqued and refined by a more advanced model (e.g., GPT-4-Turbo). This process enables the base model to self-evaluate and improve its outputs, facilitating continuous learning. SRT further optimizes the model by learning from its self-generated feedback and refinements, creating a feedback loop that promotes model improvement. Our empirical evaluations demonstrate that SRT significantly outperforms strong baselines across diverse tasks and model sizes. When applied to a 70B parameter model, SRT increases the win rate from 9.6\% to 25.8\% on the AlpacaEval 2.0 benchmark, surpassing well-established systems such as GPT-4-0314, Claude 2, and Gemini. Our analysis highlights the crucial role of language feedback in the success of SRT, suggesting potential for further exploration in this direction.
RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners
Mar 22, 2024



Large Language Models (LLMs) have achieved impressive performance across various reasoning tasks. However, even state-of-the-art LLMs such as ChatGPT are prone to logical errors during their reasoning processes. Existing solutions, such as deploying task-specific verifiers or voting over multiple reasoning paths, either require extensive human annotations or fail in scenarios with inconsistent responses. To address these challenges, we introduce RankPrompt, a new prompting method that enables LLMs to self-rank their responses without additional resources. RankPrompt breaks down the ranking problem into a series of comparisons among diverse responses, leveraging the inherent capabilities of LLMs to generate chains of comparison as contextual exemplars. Our experiments across 11 arithmetic and commonsense reasoning tasks show that RankPrompt significantly enhances the reasoning performance of ChatGPT and GPT-4, with improvements of up to 13%. Moreover, RankPrompt excels in LLM-based automatic evaluations for open-ended tasks, aligning with human judgments 74% of the time in the AlpacaEval dataset. It also exhibits robustness to variations in response order and consistency. Collectively, our results validate RankPrompt as an effective method for eliciting high-quality feedback from language models.
Clustering and Ranking: Diversity-preserved Instruction Selection through Expert-aligned Quality Estimation
Feb 28, 2024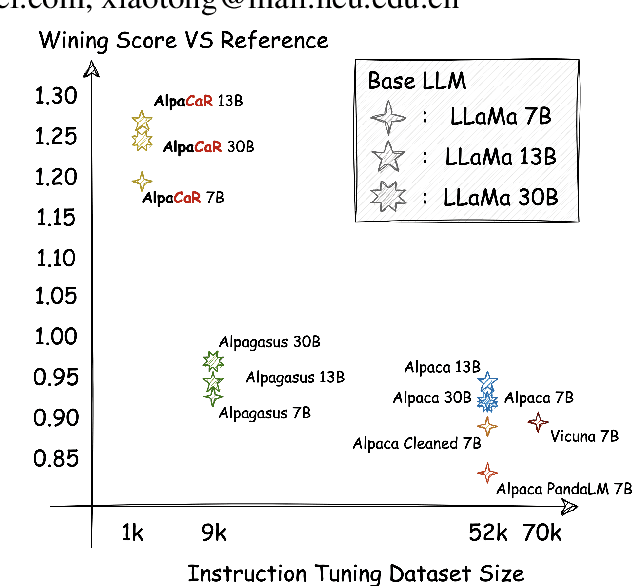

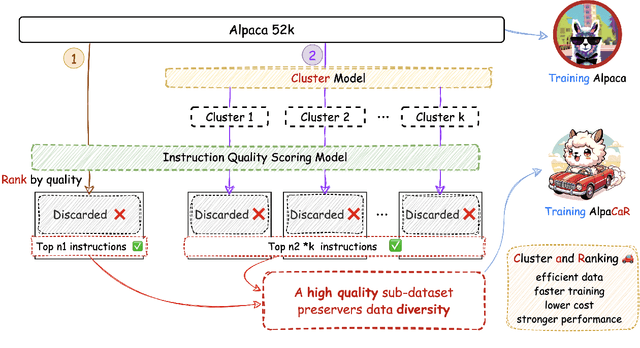
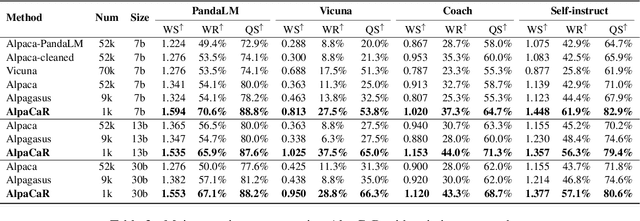
With contributions from the open-source community, a vast amount of instruction tuning (IT) data has emerged. Given the significant resource allocation required by training and evaluating models, it is advantageous to have an efficient method for selecting high-quality IT data. However, existing methods for instruction data selection have limitations such as relying on fragile external APIs, being affected by biases in GPT models, or reducing the diversity of the selected instruction dataset. In this paper, we propose an industrial-friendly, expert-aligned and diversity-preserved instruction data selection method: Clustering and Ranking (CaR). CaR consists of two steps. The first step involves ranking instruction pairs using a scoring model that is well aligned with expert preferences (achieving an accuracy of 84.25%). The second step involves preserving dataset diversity through a clustering process.In our experiment, CaR selected a subset containing only 1.96% of Alpaca's IT data, yet the underlying AlpaCaR model trained on this subset outperforms Alpaca by an average of 32.1% in GPT-4 evaluations. Furthermore, our method utilizes small models (355M parameters) and requires only 11.2% of the monetary cost compared to existing methods, making it easily deployable in industrial scenarios.
Bridging the Granularity Gap for Acoustic Modeling
May 27, 2023



While Transformer has become the de-facto standard for speech, modeling upon the fine-grained frame-level features remains an open challenge of capturing long-distance dependencies and distributing the attention weights. We propose \textit{Progressive Down-Sampling} (PDS) which gradually compresses the acoustic features into coarser-grained units containing more complete semantic information, like text-level representation. In addition, we develop a representation fusion method to alleviate information loss that occurs inevitably during high compression. In this way, we compress the acoustic features into 1/32 of the initial length while achieving better or comparable performances on the speech recognition task. And as a bonus, it yields inference speedups ranging from 1.20$\times$ to 1.47$\times$. By reducing the modeling burden, we also achieve competitive results when training on the more challenging speech translation task.
The NiuTrans Machine Translation Systems for WMT21
Sep 22, 2021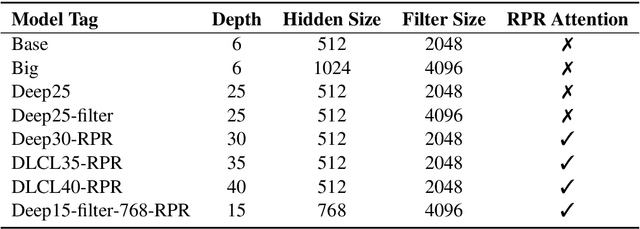
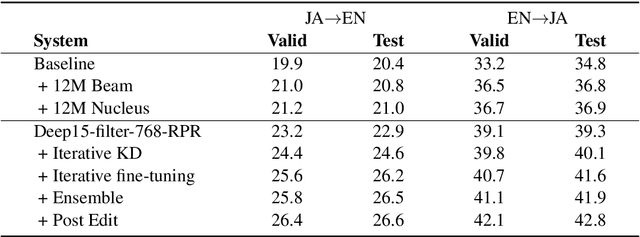
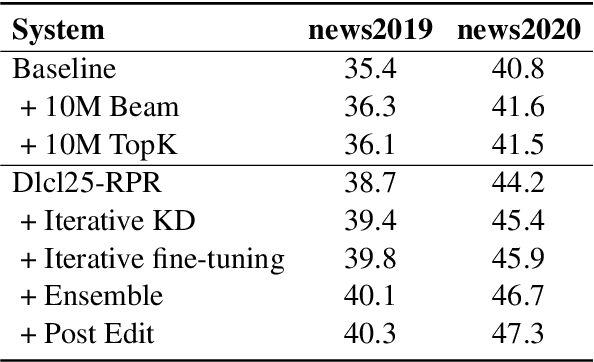
This paper describes NiuTrans neural machine translation systems of the WMT 2021 news translation tasks. We made submissions to 9 language directions, including English$\leftrightarrow$$\{$Chinese, Japanese, Russian, Icelandic$\}$ and English$\rightarrow$Hausa tasks. Our primary systems are built on several effective variants of Transformer, e.g., Transformer-DLCL, ODE-Transformer. We also utilize back-translation, knowledge distillation, post-ensemble, and iterative fine-tuning techniques to enhance the model performance further.
RankNAS: Efficient Neural Architecture Search by Pairwise Ranking
Sep 17, 2021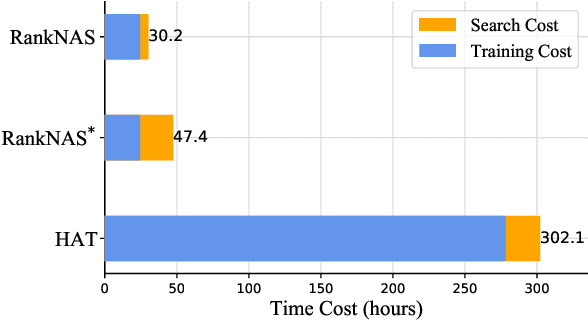

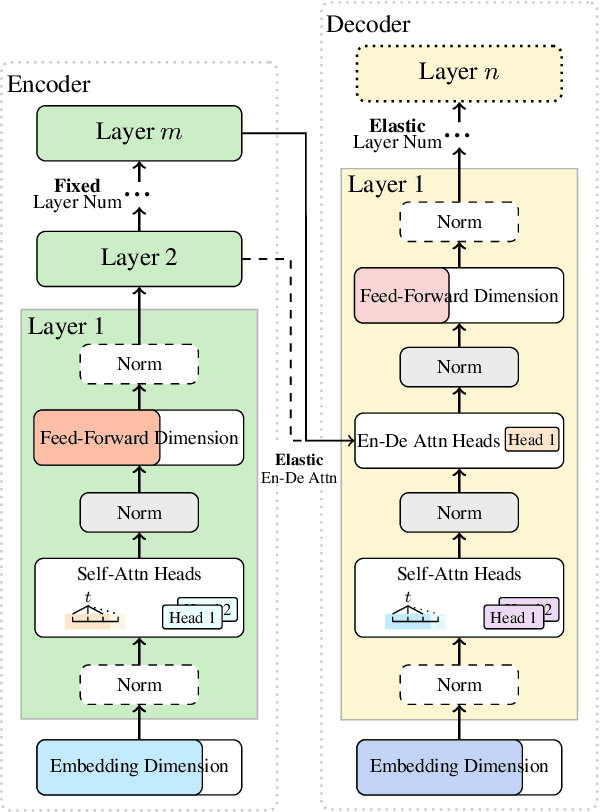
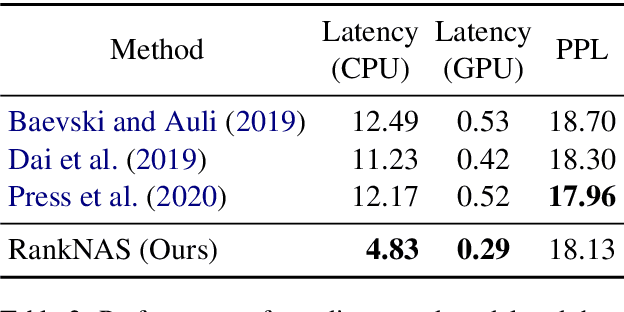
This paper addresses the efficiency challenge of Neural Architecture Search (NAS) by formulating the task as a ranking problem. Previous methods require numerous training examples to estimate the accurate performance of architectures, although the actual goal is to find the distinction between "good" and "bad" candidates. Here we do not resort to performance predictors. Instead, we propose a performance ranking method (RankNAS) via pairwise ranking. It enables efficient architecture search using much fewer training examples. Moreover, we develop an architecture selection method to prune the search space and concentrate on more promising candidates. Extensive experiments on machine translation and language modeling tasks show that RankNAS can design high-performance architectures while being orders of magnitude faster than state-of-the-art NAS systems.
The NiuTrans System for WNGT 2020 Efficiency Task
Sep 16, 2021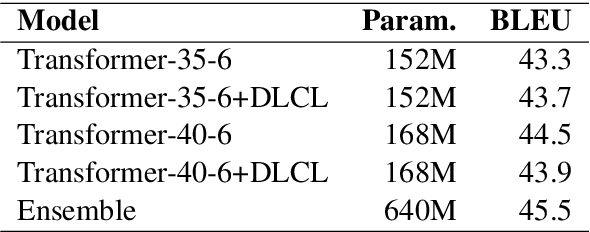

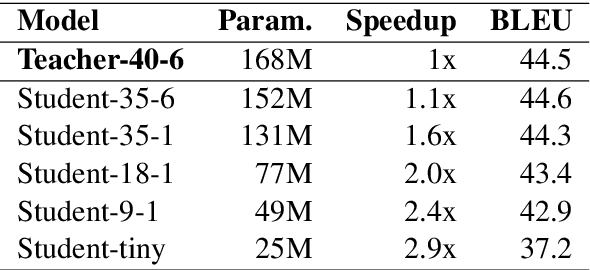
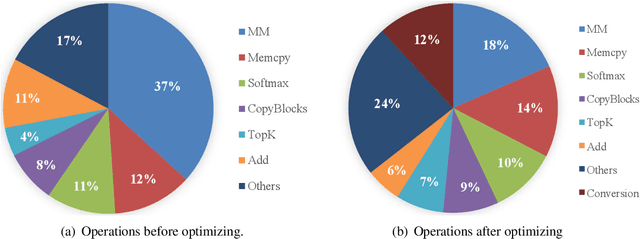
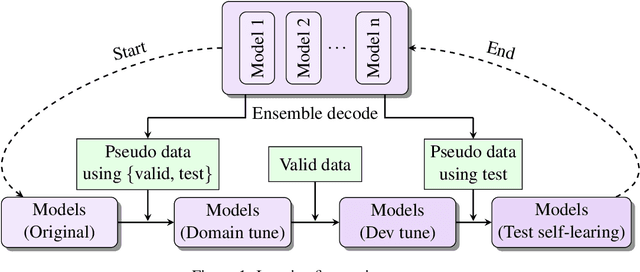
This paper describes the submissions of the NiuTrans Team to the WNGT 2020 Efficiency Shared Task. We focus on the efficient implementation of deep Transformer models \cite{wang-etal-2019-learning, li-etal-2019-niutrans} using NiuTensor (https://github.com/NiuTrans/NiuTensor), a flexible toolkit for NLP tasks. We explored the combination of deep encoder and shallow decoder in Transformer models via model compression and knowledge distillation. The neural machine translation decoding also benefits from FP16 inference, attention caching, dynamic batching, and batch pruning. Our systems achieve promising results in both translation quality and efficiency, e.g., our fastest system can translate more than 40,000 tokens per second with an RTX 2080 Ti while maintaining 42.9 BLEU on \textit{newstest2018}. The code, models, and docker images are available at NiuTrans.NMT (https://github.com/NiuTrans/NiuTrans.NMT).
The NiuTrans System for the WMT21 Efficiency Task
Sep 16, 2021

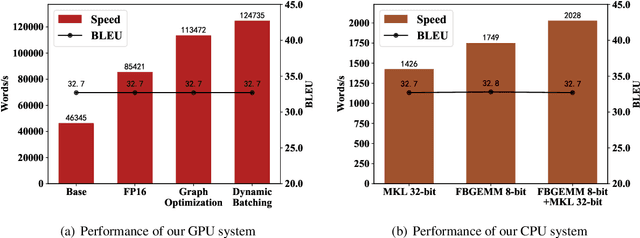
This paper describes the NiuTrans system for the WMT21 translation efficiency task (http://statmt.org/wmt21/efficiency-task.html). Following last year's work, we explore various techniques to improve efficiency while maintaining translation quality. We investigate the combinations of lightweight Transformer architectures and knowledge distillation strategies. Also, we improve the translation efficiency with graph optimization, low precision, dynamic batching, and parallel pre/post-processing. Our system can translate 247,000 words per second on an NVIDIA A100, being 3$\times$ faster than last year's system. Our system is the fastest and has the lowest memory consumption on the GPU-throughput track. The code, model, and pipeline will be available at NiuTrans.NMT (https://github.com/NiuTrans/NiuTrans.NMT).
Learning Architectures from an Extended Search Space for Language Modeling
Jun 05, 2020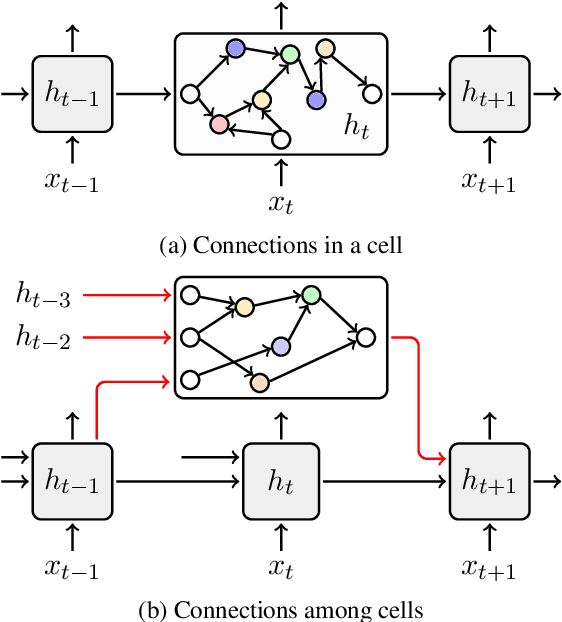


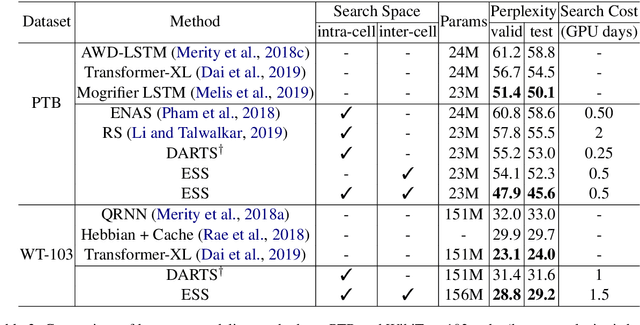
Neural architecture search (NAS) has advanced significantly in recent years but most NAS systems restrict search to learning architectures of a recurrent or convolutional cell. In this paper, we extend the search space of NAS. In particular, we present a general approach to learn both intra-cell and inter-cell architectures (call it ESS). For a better search result, we design a joint learning method to perform intra-cell and inter-cell NAS simultaneously. We implement our model in a differentiable architecture search system. For recurrent neural language modeling, it outperforms a strong baseline significantly on the PTB and WikiText data, with a new state-of-the-art on PTB. Moreover, the learned architectures show good transferability to other systems. E.g., they improve state-of-the-art systems on the CoNLL and WNUT named entity recognition (NER) tasks and CoNLL chunking task, indicating a promising line of research on large-scale pre-learned architectures.