 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-efficient Transfer Reinforcement Learning via Adaptive Reward Shaping and Policy-Ratio Reweighting Strategy
Jun 25, 2026Transfer learning improves policy learning efficiency by reusing knowledge from source tasks, providing a feasible paradigm for safe and efficient autonomous highway lane changing decision-making. Existing methods frequently encounter transfer mismatch induced by distribution shifts between source and target domains, leading to training oscillation and performance decline. Besides, target domain adaptation depends on exploratory interactions, which struggles to guarantee training safety in safety-critical lane changing cases. To tackle these limitations, this paper proposes a safe transfer reinforcement learning framework for autonomous highway lane changing. First, we design an adaptive teacher intervention mechanism based on instantaneous safety cost to restrain risky exploration and fade intervention strength progressively, with theoretical analysis on return bounds for mixed behavior policy. This intervention also produces dual-source samples for joint training. Second, a teacher-guided safe transfer module embeds action evaluation information of teacher policy into student learning via reward shaping to boost training safety and efficiency, with teacher guidance decaying as policy safety rises. Third, a teacher-guided weighted optimization mechanism adjusts sample weights in policy optimization using a likelihood ratio factor to stabilize transfer performance. Experiments under varied traffic densities and validations on real-world NGSIM dataset reveal that our method surpasses baseline approaches by over 52.2% in safety and 5.0% in learning efficiency. Results verify the efficacy and robustness of our safety-aware transfer strategy for autonomous highway lane changing under various traffic conditions.
Stepwise Reasoning Enhancement for LLMs via External Subgraph Generation
Jun 03, 2026Large language models have shown strong performance in natural language generation and downstream reasoning tasks, but they still struggle with logical consistency, factual grounding, and interpretability in complex multi-step reasoning. To address these limitations, this paper proposes SGR, a stepwise reasoning enhancement framework that integrates large language models with external knowledge graphs through query-relevant subgraph generation. Given an input question, SGR first extracts key entities, relations, and constraints to construct a structured schema, then retrieves compact subgraphs from a knowledge graph using schema-guided querying. The generated subgraphs provide explicit relational evidence that guides the language model through step-by-step reasoning. In addition, SGR combines direct Cypher-based reasoning with collaborative reasoning integration, allowing candidate answers from multiple reasoning paths to be validated and aggregated according to both model confidence and graph consistency. Experiments on benchmark datasets including CWQ, WebQSP, GrailQA, and KQA Pro demonstrate that SGR improves reasoning accuracy and Hits@1 performance over standard prompting and several knowledge-enhanced baselines. Ablation studies further show that schema guidance and Neo4j-based retrieval are both crucial to the effectiveness of the framework. These results indicate that dynamically generated external subgraphs can improve the accuracy, robustness, and interpretability of LLM-based reasoning.
Prism: Spectral-Aware Block-Sparse Attention
Feb 09, 2026Block-sparse attention is promising for accelerating long-context LLM pre-filling, yet identifying relevant blocks efficiently remains a bottleneck. Existing methods typically employ coarse-grained attention as a proxy for block importance estimation, but often resort to expensive token-level searching or scoring, resulting in significant selection overhead. In this work, we trace the inaccuracy of standard coarse-grained attention via mean pooling to a theoretical root cause: the interaction between mean pooling and Rotary Positional Embeddings (RoPE). We prove that mean pooling acts as a low-pass filter that induces destructive interference in high-frequency dimensions, effectively creating a "blind spot" for local positional information (e.g., slash patterns). To address this, we introduce Prism, a training-free spectral-aware approach that decomposes block selection into high-frequency and low-frequency branches. By applying energy-based temperature calibration, Prism restores the attenuated positional signals directly from pooled representations, enabling block importance estimation using purely block-level operations, thereby improving efficiency. Extensive evaluations confirm that Prism maintains accuracy parity with full attention while delivering up to $\mathbf{5.1\times}$ speedup.
ROG: Retrieval-Augmented LLM Reasoning for Complex First-Order Queries over Knowledge Graphs
Feb 02, 2026Answering first-order logic (FOL) queries over incomplete knowledge graphs (KGs) is difficult, especially for complex query structures that compose projection, intersection, union, and negation. We propose ROG, a retrieval-augmented framework that combines query-aware neighborhood retrieval with large language model (LLM) chain-of-thought reasoning. ROG decomposes a multi-operator query into a sequence of single-operator sub-queries and grounds each step in compact, query-relevant neighborhood evidence. Intermediate answer sets are cached and reused across steps, improving consistency on deep reasoning chains. This design reduces compounding errors and yields more robust inference on complex and negation-heavy queries. Overall, ROG provides a practical alternative to embedding-based logical reasoning by replacing learned operators with retrieval-grounded, step-wise inference. Experiments on standard KG reasoning benchmarks show consistent gains over strong embedding-based baselines, with the largest improvements on high-complexity and negation-heavy query types.
A Stepwise-Enhanced Reasoning Framework for Large Language Models Based on External Subgraph Generation
Dec 29, 2025Large Language Models (LLMs) have achieved strong performance across a wide range of natural language processing tasks in recent years, including machine translation, text generation, and question answering. As their applications extend to increasingly complex scenarios, however, LLMs continue to face challenges in tasks that require deep reasoning and logical inference. In particular, models trained on large scale textual corpora may incorporate noisy or irrelevant information during generation, which can lead to incorrect predictions or outputs that are inconsistent with factual knowledge. To address this limitation, we propose a stepwise reasoning enhancement framework for LLMs based on external subgraph generation, termed SGR. The proposed framework dynamically constructs query relevant subgraphs from external knowledge bases and leverages their semantic structure to guide the reasoning process. By performing reasoning in a step by step manner over structured subgraphs, SGR reduces the influence of noisy information and improves reasoning accuracy. Specifically, the framework first generates an external subgraph tailored to the input query, then guides the model to conduct multi step reasoning grounded in the subgraph, and finally integrates multiple reasoning paths to produce the final answer. Experimental results on multiple benchmark datasets demonstrate that SGR consistently outperforms strong baselines, indicating its effectiveness in enhancing the reasoning capabilities of LLMs.
A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
Dec 22, 2025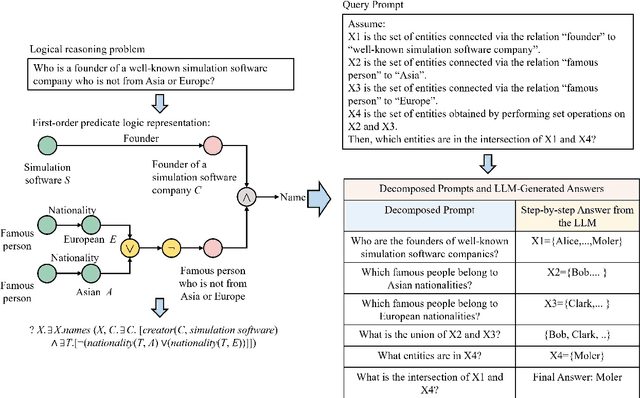
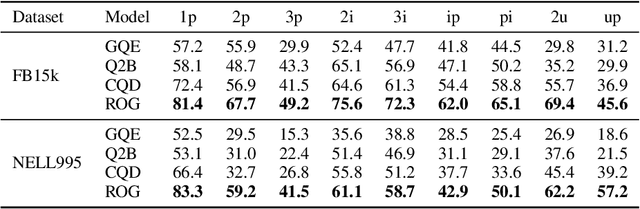
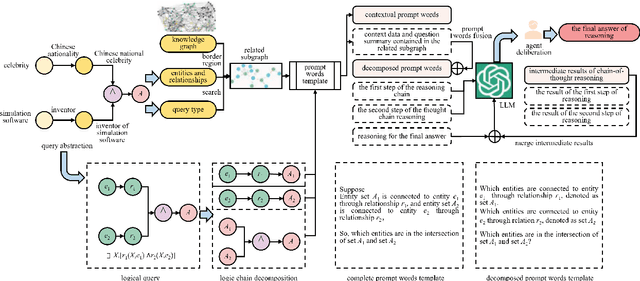
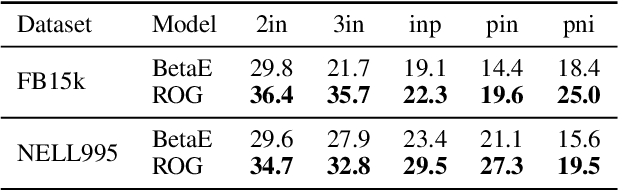
Reasoning over knowledge graphs (KGs) with first-order logic (FOL) queries is challenging due to the inherent incompleteness of real-world KGs and the compositional complexity of logical query structures. Most existing methods rely on embedding entities and relations into continuous geometric spaces and answer queries via differentiable set operations. While effective for simple query patterns, these approaches often struggle to generalize to complex queries involving multiple operators, deeper reasoning chains, or heterogeneous KG schemas. We propose ROG (Reasoning Over knowledge Graphs with large language models), an ensemble-style framework that combines query-aware KG neighborhood retrieval with large language model (LLM)-based chain-of-thought reasoning. ROG decomposes complex FOL queries into sequences of simpler sub-queries, retrieves compact, query-relevant subgraphs as contextual evidence, and performs step-by-step logical inference using an LLM, avoiding the need for task-specific embedding optimization. Experiments on standard KG reasoning benchmarks demonstrate that ROG consistently outperforms strong embedding-based baselines in terms of mean reciprocal rank (MRR), with particularly notable gains on high-complexity query types. These results suggest that integrating structured KG retrieval with LLM-driven logical reasoning offers a robust and effective alternative for complex KG reasoning tasks.
MRO: Enhancing Reasoning in Diffusion Language Models via Multi-Reward Optimization
Oct 24, 2025


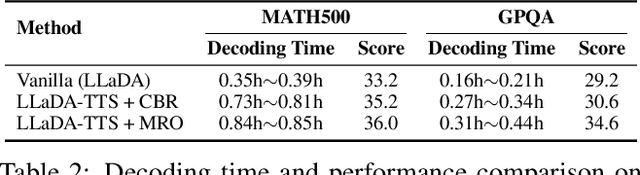
Recent advances in diffusion language models (DLMs) have presented a promising alternative to traditional autoregressive large language models (LLMs). However, DLMs still lag behind LLMs in reasoning performance, especially as the number of denoising steps decreases. Our analysis reveals that this shortcoming arises primarily from the independent generation of masked tokens across denoising steps, which fails to capture the token correlation. In this paper, we define two types of token correlation: intra-sequence correlation and inter-sequence correlation, and demonstrate that enhancing these correlations improves reasoning performance. To this end, we propose a Multi-Reward Optimization (MRO) approach, which encourages DLMs to consider the token correlation during the denoising process. More specifically, our MRO approach leverages test-time scaling, reject sampling, and reinforcement learning to directly optimize the token correlation with multiple elaborate rewards. Additionally, we introduce group step and importance sampling strategies to mitigate reward variance and enhance sampling efficiency. Through extensive experiments, we demonstrate that MRO not only improves reasoning performance but also achieves significant sampling speedups while maintaining high performance on reasoning benchmarks.
ConvSearch-R1: Enhancing Query Reformulation for Conversational Search with Reasoning via Reinforcement Learning
May 21, 2025Conversational search systems require effective handling of context-dependent queries that often contain ambiguity, omission, and coreference. Conversational Query Reformulation (CQR) addresses this challenge by transforming these queries into self-contained forms suitable for off-the-shelf retrievers. However, existing CQR approaches suffer from two critical constraints: high dependency on costly external supervision from human annotations or large language models, and insufficient alignment between the rewriting model and downstream retrievers. We present ConvSearch-R1, the first self-driven framework that completely eliminates dependency on external rewrite supervision by leveraging reinforcement learning to optimize reformulation directly through retrieval signals. Our novel two-stage approach combines Self-Driven Policy Warm-Up to address the cold-start problem through retrieval-guided self-distillation, followed by Retrieval-Guided Reinforcement Learning with a specially designed rank-incentive reward shaping mechanism that addresses the sparsity issue in conventional retrieval metrics. Extensive experiments on TopiOCQA and QReCC datasets demonstrate that ConvSearch-R1 significantly outperforms previous state-of-the-art methods, achieving over 10% improvement on the challenging TopiOCQA dataset while using smaller 3B parameter models without any external supervision.
Semformer: Transformer Language Models with Semantic Planning
Sep 17, 2024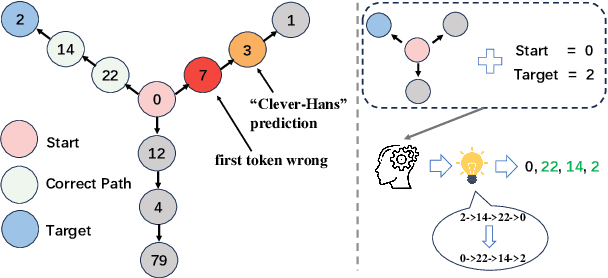
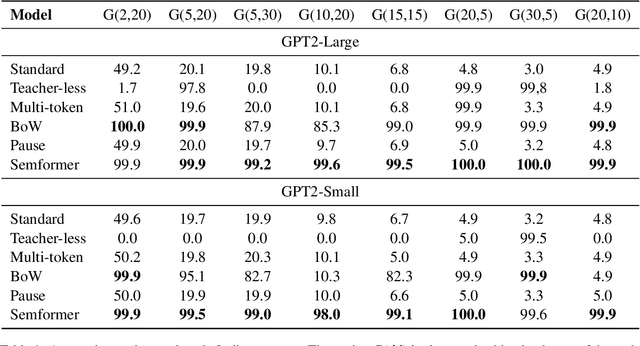
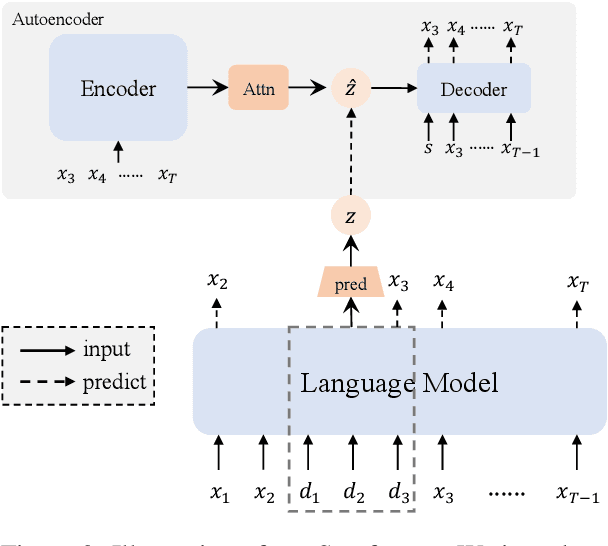
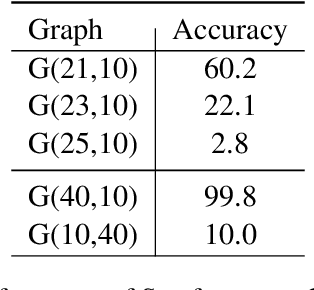
Next-token prediction serves as the dominant component in current neural language models. During the training phase, the model employs teacher forcing, which predicts tokens based on all preceding ground truth tokens. However, this approach has been found to create shortcuts, utilizing the revealed prefix to spuriously fit future tokens, potentially compromising the accuracy of the next-token predictor. In this paper, we introduce Semformer, a novel method of training a Transformer language model that explicitly models the semantic planning of response. Specifically, we incorporate a sequence of planning tokens into the prefix, guiding the planning token representations to predict the latent semantic representations of the response, which are induced by an autoencoder. In a minimal planning task (i.e., graph path-finding), our model exhibits near-perfect performance and effectively mitigates shortcut learning, a feat that standard training methods and baseline models have been unable to accomplish. Furthermore, we pretrain Semformer from scratch with 125M parameters, demonstrating its efficacy through measures of perplexity, in-context learning, and fine-tuning on summarization tasks.
Large Language Models are Parallel Multilingual Learners
Mar 14, 2024In this study, we reveal an in-context learning (ICL) capability of multilingual large language models (LLMs): by translating the input to several languages, we provide Parallel Input in Multiple Languages (PiM) to LLMs, which significantly enhances their comprehension abilities. To test this capability, we design extensive experiments encompassing 8 typical datasets, 7 languages and 8 state-of-the-art multilingual LLMs. Experimental results show that (1) incorporating more languages help PiM surpass the conventional ICL further; (2) even combining with the translations that are inferior to baseline performance can also help. Moreover, by examining the activated neurons in LLMs, we discover a counterintuitive but interesting phenomenon. Contrary to the common thought that PiM would activate more neurons than monolingual input to leverage knowledge learned from diverse languages, PiM actually inhibits neurons and promotes more precise neuron activation especially when more languages are added. This phenomenon aligns with the neuroscience insight about synaptic pruning, which removes less used neural connections, strengthens remainders, and then enhances brain intelligence.