 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Preference Learning for Personalized Multimodal Generation
Apr 22, 2026The emergence of generative models enables the creation of texts and images tailored to users' preferences. Existing personalized generative models have two critical limitations: lacking a dedicated paradigm for accurate preference modeling, and generating unimodal content despite real-world multimodal-driven user interactions. Therefore, we propose personalized multimodal generation, which captures modal-specific preferences via a dedicated preference model from multimodal interactions, and then feeds them into downstream generators for personalized multimodal content. However, this task presents two challenges: (1) Gap between continuous preferences from dedicated modeling and discrete token inputs intrinsic to generator architectures; (2) Potential inconsistency between generated images and texts. To tackle these, we present a two-stage framework called Discrete Preference learning for Personalized Multimodal Generation (DPPMG). In the first stage, to accurately learn discrete modal-specific preferences, we introduce a modal-specific graph neural network (a dedicated preference model) to learn users' modal-specific preferences, which preferences are then quantized into discrete preference tokens. In the second stage, the discrete modal-specific preference tokens are injected into downstream text and image generators. To further enhance cross-modal consistency while preserving personalization, we design a cross-modal consistent and personalized reward to fine-tune token-associated parameters. Extensive experiments on two real-world datasets demonstrate the effectiveness of our model in generating personalized and consistent multimodal content.
TSEmbed: Unlocking Task Scaling in Universal Multimodal Embeddings
Mar 05, 2026Despite the exceptional reasoning capabilities of Multimodal Large Language Models (MLLMs), their adaptation into universal embedding models is significantly impeded by task conflict. To address this, we propose TSEmbed, a universal multimodal embedding framework that synergizes Mixture-of-Experts (MoE) with Low-Rank Adaptation (LoRA) to explicitly disentangle conflicting task objectives. Moreover, we introduce Expert-Aware Negative Sampling (EANS), a novel strategy that leverages expert routing distributions as an intrinsic proxy for semantic similarity. By dynamically prioritizing informative hard negatives that share expert activation patterns with the query, EANS effectively sharpens the model's discriminative power and refines embedding boundaries. To ensure training stability, we further devise a two-stage learning paradigm that solidifies expert specialization before optimizing representations via EANS. TSEmbed achieves state-of-the-art performance on both the Massive Multimodal Embedding Benchmark (MMEB) and real-world industrial production datasets, laying a foundation for task-level scaling in universal multimodal embeddings.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
Audience Expansion for Multi-show Release Based on an Edge-prompted Heterogeneous Graph Network
Apr 08, 2023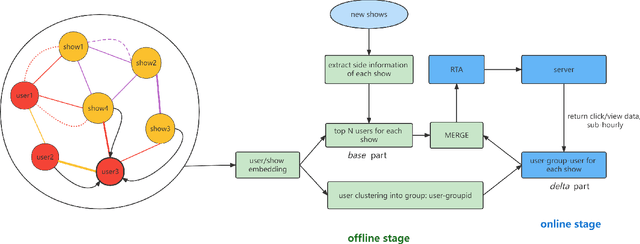

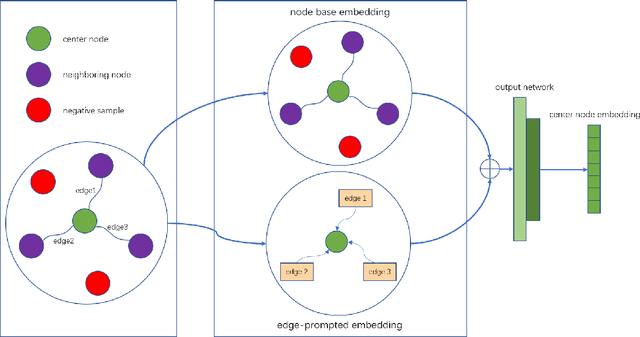
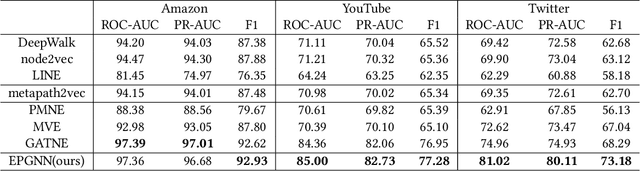
In the user targeting and expanding of new shows on a video platform, the key point is how their embeddings are generated. It's supposed to be personalized from the perspective of both users and shows. Furthermore, the pursue of both instant (click) and long-time (view time) rewards, and the cold-start problem for new shows bring additional challenges. Such a problem is suitable for processing by heterogeneous graph models, because of the natural graph structure of data. But real-world networks usually have billions of nodes and various types of edges. Few existing methods focus on handling large-scale data and exploiting different types of edges, especially the latter. In this paper, we propose a two-stage audience expansion scheme based on an edge-prompted heterogeneous graph network which can take different double-sided interactions and features into account. In the offline stage, to construct the graph, user IDs and specific side information combinations of the shows are chosen to be the nodes, and click/co-click relations and view time are used to build the edges. Embeddings and clustered user groups are then calculated. When new shows arrive, their embeddings and subsequent matching users can be produced within a consistent space. In the online stage, posterior data including click/view users are employed as seeds to look for similar users. The results on the public datasets and our billion-scale data demonstrate the accuracy and efficiency of our approach.
RA V-Net: Deep learning network for automated liver segmentation
Dec 16, 2021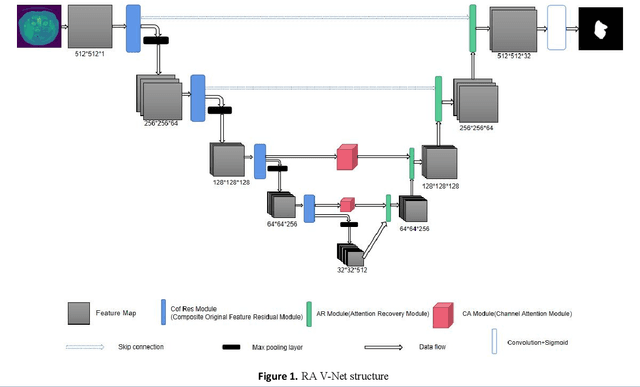

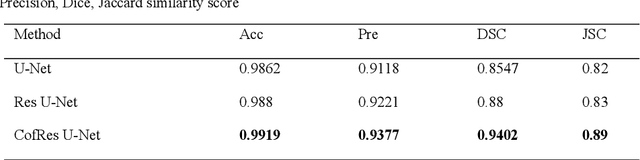

Accurate segmentation of the liver is a prerequisite for the diagnosis of disease. Automated segmentation is an important application of computer-aided detection and diagnosis of liver disease. In recent years, automated processing of medical images has gained breakthroughs. However, the low contrast of abdominal scan CT images and the complexity of liver morphology make accurate automatic segmentation challenging. In this paper, we propose RA V-Net, which is an improved medical image automatic segmentation model based on U-Net. It has the following three main innovations. CofRes Module (Composite Original Feature Residual Module) is proposed. With more complex convolution layers and skip connections to make it obtain a higher level of image feature extraction capability and prevent gradient disappearance or explosion. AR Module (Attention Recovery Module) is proposed to reduce the computational effort of the model. In addition, the spatial features between the data pixels of the encoding and decoding modules are sensed by adjusting the channels and LSTM convolution. Finally, the image features are effectively retained. CA Module (Channel Attention Module) is introduced, which used to extract relevant channels with dependencies and strengthen them by matrix dot product, while weakening irrelevant channels without dependencies. The purpose of channel attention is achieved. The attention mechanism provided by LSTM convolution and CA Module are strong guarantees for the performance of the neural network. The accuracy of U-Net network: 0.9862, precision: 0.9118, DSC: 0.8547, JSC: 0.82. The evaluation metrics of RA V-Net, accuracy: 0.9968, precision: 0.9597, DSC: 0.9654, JSC: 0.9414. The most representative metric for the segmentation effect is DSC, which improves 0.1107 over U-Net, and JSC improves 0.1214.
Component Divide-and-Conquer for Real-World Image Super-Resolution
Aug 05, 2020In this paper, we present a large-scale Diverse Real-world image Super-Resolution dataset, i.e., DRealSR, as well as a divide-and-conquer Super-Resolution (SR) network, exploring the utility of guiding SR model with low-level image components. DRealSR establishes a new SR benchmark with diverse real-world degradation processes, mitigating the limitations of conventional simulated image degradation. In general, the targets of SR vary with image regions with different low-level image components, e.g., smoothness preserving for flat regions, sharpening for edges, and detail enhancing for textures. Learning an SR model with conventional pixel-wise loss usually is easily dominated by flat regions and edges, and fails to infer realistic details of complex textures. We propose a Component Divide-and-Conquer (CDC) model and a Gradient-Weighted (GW) loss for SR. Our CDC parses an image with three components, employs three Component-Attentive Blocks (CABs) to learn attentive masks and intermediate SR predictions with an intermediate supervision learning strategy, and trains an SR model following a divide-and-conquer learning principle. Our GW loss also provides a feasible way to balance the difficulties of image components for SR. Extensive experiments validate the superior performance of our CDC and the challenging aspects of our DRealSR dataset related to diverse real-world scenarios. Our dataset and codes are publicly available at https://github.com/xiezw5/Component-Divide-and-Conquer-for-Real-World-Image-Super-Resolution
Difficulty-aware Image Super Resolution via Deep Adaptive Dual-Network
May 01, 2019

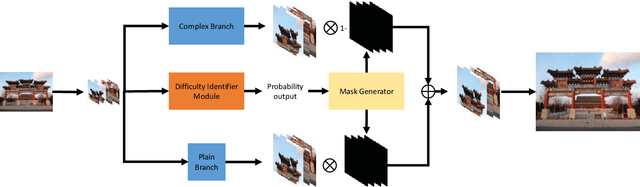
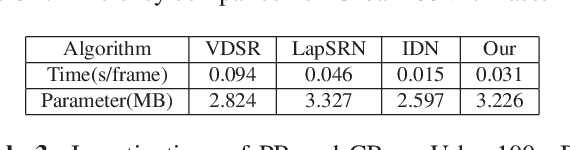
Recently, deep learning based single image super-resolution(SR) approaches have achieved great development. The state-of-the-art SR methods usually adopt a feed-forward pipeline to establish a non-linear mapping between low-res(LR) and high-res(HR) images. However, due to treating all image regions equally without considering the difficulty diversity, these approaches meet an upper bound for optimization. To address this issue, we propose a novel SR approach that discriminately processes each image region within an image by its difficulty. Specifically, we propose a dual-way SR network that one way is trained to focus on easy image regions and another is trained to handle hard image regions. To identify whether a region is easy or hard, we propose a novel image difficulty recognition network based on PSNR prior. Our SR approach that uses the region mask to adaptively enforce the dual-way SR network yields superior results. Extensive experiments on several standard benchmarks (e.g., Set5, Set14, BSD100, and Urban100) show that our approach achieves state-of-the-art performance.
Predicting protein inter-residue contacts using composite likelihood maximization and deep learning
Aug 31, 2018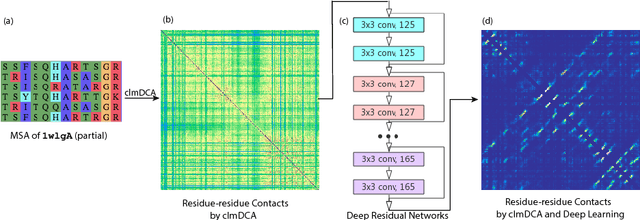
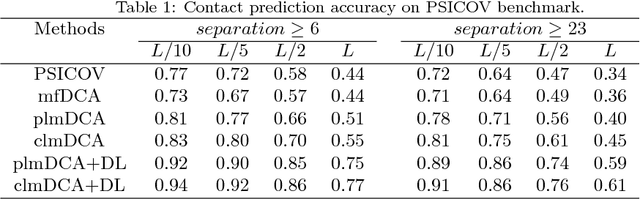
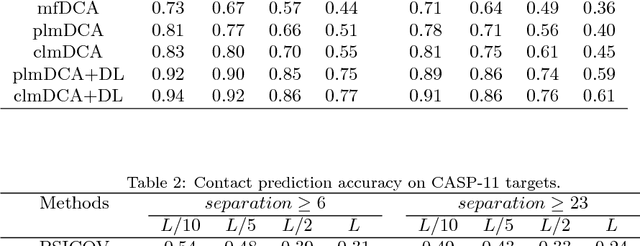
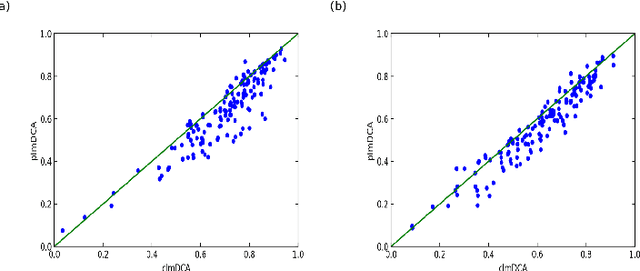
Accurate prediction of inter-residue contacts of a protein is important to calcu- lating its tertiary structure. Analysis of co-evolutionary events among residues has been proved effective to inferring inter-residue contacts. The Markov ran- dom field (MRF) technique, although being widely used for contact prediction, suffers from the following dilemma: the actual likelihood function of MRF is accurate but time-consuming to calculate, in contrast, approximations to the actual likelihood, say pseudo-likelihood, are efficient to calculate but inaccu- rate. Thus, how to achieve both accuracy and efficiency simultaneously remains a challenge. In this study, we present such an approach (called clmDCA) for contact prediction. Unlike plmDCA using pseudo-likelihood, i.e., the product of conditional probability of individual residues, our approach uses composite- likelihood, i.e., the product of conditional probability of all residue pairs. Com- posite likelihood has been theoretically proved as a better approximation to the actual likelihood function than pseudo-likelihood. Meanwhile, composite likelihood is still efficient to maximize, thus ensuring the efficiency of clmDCA. We present comprehensive experiments on popular benchmark datasets, includ- ing PSICOV dataset and CASP-11 dataset, to show that: i) clmDCA alone outperforms the existing MRF-based approaches in prediction accuracy. ii) When equipped with deep learning technique for refinement, the prediction ac- curacy of clmDCA was further significantly improved, suggesting the suitability of clmDCA for subsequent refinement procedure. We further present successful application of the predicted contacts to accurately build tertiary structures for proteins in the PSICOV dataset. Accessibility: The software clmDCA and a server are publicly accessible through http://protein.ict.ac.cn/clmDCA/.