 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimary ICD Category Prediction using LLM-based Probing
Jun 27, 2026Objective: ICD codes are central to reimbursement, research, and population health surveillance, yet automated coding systems often struggle to integrate diagnostic signals from both clinical narratives and structured electronic health record (EHR) variables. We evaluated whether frozen medical large language model (LLM) representations can serve as a shared embedding space for multimodal primary diagnosis category prediction. Materials and Methods: We constructed a MIMIC-IV cohort of 13,645 admissions from the 10 most frequent primary ICD-10 codes, consolidated into seven categories. Structured variables were serialized into clinical narratives and combined with leakage-pruned discharge notes. Using a frozen MedFound-Llama3-8B-finetuned backbone, we extracted hidden states from five transformer layers and trained linear probes for structured-only, unstructured-only, and combined inputs, comparing against XGBoost and information-matched PLM-ICD baselines and evaluating MIMIC-III adaptation with a compact bottleneck adapter. Results: The combined probe performed best on MIMIC-IV (87.69% strict; 91.45% medical accuracy), exceeding both single-modality probes and baselines. The structured-only probe outperformed its standard baseline by 6.19 points in medical accuracy. Diagnostic information became increasingly linearly separable in deeper layers, and a 2M-parameter adapter restored cross-dataset transfer to MIMIC-III using only 5% of target labels. Discussion: LLM embeddings can unify structured and narrative EHR information for multimodal diagnosis prediction, supporting efficient reuse of clinical representations across modalities and datasets through a small representation-level module. Conclusion: Multimodal probing of frozen medical LLM representations provides a practical approach for studying EHR modalities and adapting clinical representations across datasets.
Calibrating conditional risk
Apr 22, 2026We introduce and study the problem of calibrating conditional risk, which involves estimating the expected loss of a prediction model conditional on input features. We analyze this problem in both classification and regression settings and show that it is fundamentally equivalent to a standard regression task. For classification settings, we further establish a connection between conditional risk calibration and individual/conditional probability calibration, and develop theoretical insights for the performance metric. This reveals that while conditional risk calibration is related to existing uncertainty quantification problems, it remains a distinct and standalone machine learning problem. Empirically, we validate our theoretical findings and demonstrate the practical implications of conditional risk calibration in the learning to defer (L2D) framework. Our systematic experiments provide both qualitative and quantitative assessments, offering guidance for future research in uncertainty-aware decision-making.
HiFlow: Hierarchical Feedback-Driven Optimization for Constrained Long-Form Text Generation
Mar 05, 2026Large language models perform well in short text generation but still struggle with long text generation, particularly under complex constraints. Such tasks involve multiple tightly coupled objectives, including global structural consistency, local semantic coherence, and constraint feasibility, forming a challenging constrained optimization problem. Existing approaches mainly rely on static planning or offline supervision, limiting effective coordination between global and local objectives during generation. To address these challenges, we propose HiFlow, a hierarchical feedback-driven optimization framework for constrained long text generation. HiFlow formulates generation as a two-level optimization process, consisting of a planning layer for global structure and constraint modeling, and a generation layer for conditioned text generation. By incorporating constraint-aware plan screening and closed-loop feedback at both levels, HiFlow enables joint optimization of planning quality and generation behavior, progressively guiding the model toward high-quality, constraint-satisfying outputs. Experiments on multiple backbones confirm HiFlow's effectiveness over baseline methods.
CleanUpBench: Embodied Sweeping and Grasping Benchmark
Aug 07, 2025Embodied AI benchmarks have advanced navigation, manipulation, and reasoning, but most target complex humanoid agents or large-scale simulations that are far from real-world deployment. In contrast, mobile cleaning robots with dual mode capabilities, such as sweeping and grasping, are rapidly emerging as realistic and commercially viable platforms. However, no benchmark currently exists that systematically evaluates these agents in structured, multi-target cleaning tasks, revealing a critical gap between academic research and real-world applications. We introduce CleanUpBench, a reproducible and extensible benchmark for evaluating embodied agents in realistic indoor cleaning scenarios. Built on NVIDIA Isaac Sim, CleanUpBench simulates a mobile service robot equipped with a sweeping mechanism and a six-degree-of-freedom robotic arm, enabling interaction with heterogeneous objects. The benchmark includes manually designed environments and one procedurally generated layout to assess generalization, along with a comprehensive evaluation suite covering task completion, spatial efficiency, motion quality, and control performance. To support comparative studies, we provide baseline agents based on heuristic strategies and map-based planning. CleanUpBench bridges the gap between low-level skill evaluation and full-scene testing, offering a scalable testbed for grounded, embodied intelligence in everyday settings.
Graph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning
Jul 29, 2025Retrieval-Augmented Generation (RAG) mitigates hallucination in LLMs by incorporating external knowledge, but relies on chunk-based retrieval that lacks structural semantics. GraphRAG methods improve RAG by modeling knowledge as entity-relation graphs, but still face challenges in high construction cost, fixed one-time retrieval, and reliance on long-context reasoning and prompt design. To address these challenges, we propose Graph-R1, an agentic GraphRAG framework via end-to-end reinforcement learning (RL). It introduces lightweight knowledge hypergraph construction, models retrieval as a multi-turn agent-environment interaction, and optimizes the agent process via an end-to-end reward mechanism. Experiments on standard RAG datasets show that Graph-R1 outperforms traditional GraphRAG and RL-enhanced RAG methods in reasoning accuracy, retrieval efficiency, and generation quality.
Collaborative Prediction: To Join or To Disjoin Datasets
Jun 12, 2025With the recent rise of generative Artificial Intelligence (AI), the need of selecting high-quality dataset to improve machine learning models has garnered increasing attention. However, some part of this topic remains underexplored, even for simple prediction models. In this work, we study the problem of developing practical algorithms that select appropriate dataset to minimize population loss of our prediction model with high probability. Broadly speaking, we investigate when datasets from different sources can be effectively merged to enhance the predictive model's performance, and propose a practical algorithm with theoretical guarantees. By leveraging an oracle inequality and data-driven estimators, the algorithm reduces population loss with high probability. Numerical experiments demonstrate its effectiveness in both standard linear regression and broader machine learning applications. Code is available at https://github.com/kkrokii/collaborative_prediction.
OMGPT: A Sequence Modeling Framework for Data-driven Operational Decision Making
May 19, 2025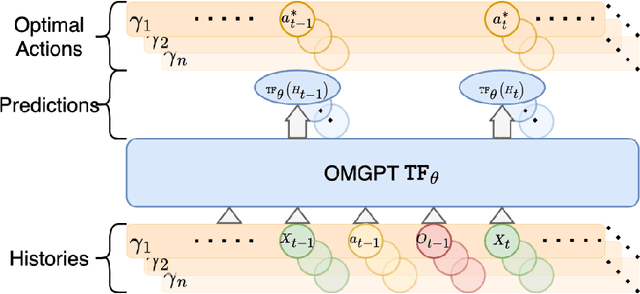



We build a Generative Pre-trained Transformer (GPT) model from scratch to solve sequential decision making tasks arising in contexts of operations research and management science which we call OMGPT. We first propose a general sequence modeling framework to cover several operational decision making tasks as special cases, such as dynamic pricing, inventory management, resource allocation, and queueing control. Under the framework, all these tasks can be viewed as a sequential prediction problem where the goal is to predict the optimal future action given all the historical information. Then we train a transformer-based neural network model (OMGPT) as a natural and powerful architecture for sequential modeling. This marks a paradigm shift compared to the existing methods for these OR/OM tasks in that (i) the OMGPT model can take advantage of the huge amount of pre-trained data; (ii) when tackling these problems, OMGPT does not assume any analytical model structure and enables a direct and rich mapping from the history to the future actions. Either of these two aspects, to the best of our knowledge, is not achieved by any existing method. We establish a Bayesian perspective to theoretically understand the working mechanism of the OMGPT on these tasks, which relates its performance with the pre-training task diversity and the divergence between the testing task and pre-training tasks. Numerically, we observe a surprising performance of the proposed model across all the above tasks.
HyperGraphRAG: Retrieval-Augmented Generation with Hypergraph-Structured Knowledge Representation
Mar 27, 2025While standard Retrieval-Augmented Generation (RAG) based on chunks, GraphRAG structures knowledge as graphs to leverage the relations among entities. However, previous GraphRAG methods are limited by binary relations: one edge in the graph only connects two entities, which cannot well model the n-ary relations among more than two entities that widely exist in reality. To address this limitation, we propose HyperGraphRAG, a novel hypergraph-based RAG method that represents n-ary relational facts via hyperedges, modeling the complicated n-ary relations in the real world. To retrieve and generate over hypergraphs, we introduce a complete pipeline with a hypergraph construction method, a hypergraph retrieval strategy, and a hypergraph-guided generation mechanism. Experiments across medicine, agriculture, computer science, and law demonstrate that HyperGraphRAG outperforms standard RAG and GraphRAG in accuracy and generation quality.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Reward Modeling with Ordinal Feedback: Wisdom of the Crowd
Nov 19, 2024



Learning a reward model (RM) from human preferences has been an important component in aligning large language models (LLMs). The canonical setup of learning RMs from pairwise preference data is rooted in the classic Bradley-Terry (BT) model that accepts binary feedback, i.e., the label being either Response 1 is better than Response 2, or the opposite. Such a setup inevitably discards potentially useful samples (such as "tied" between the two responses) and loses more fine-grained information (such as "slightly better"). In this paper, we propose a framework for learning RMs under ordinal feedback which generalizes the case of binary preference feedback to any arbitrary granularity. Specifically, we first identify a marginal unbiasedness condition, which generalizes the assumption of the BT model in the existing binary feedback setting. The condition validates itself via the sociological concept of the wisdom of the crowd. Under the condition, we develop a natural probability model for pairwise preference data under ordinal feedback and analyze its properties. We prove the statistical benefits of ordinal feedback in terms of reducing the Rademacher complexity compared to the case of binary feedback. The proposed learning objective and the theory also extend to hinge loss and direct policy optimization (DPO). In particular, the theoretical analysis may be of independent interest when applying to a seemingly unrelated problem of knowledge distillation to interpret the bias-variance trade-off therein. The framework also sheds light on writing guidance for human annotators. Our numerical experiments validate that fine-grained feedback leads to better reward learning for both in-distribution and out-of-distribution settings. Further experiments show that incorporating a certain proportion of samples with tied preference boosts RM learning.