 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning
Jul 29, 2025Retrieval-Augmented Generation (RAG) mitigates hallucination in LLMs by incorporating external knowledge, but relies on chunk-based retrieval that lacks structural semantics. GraphRAG methods improve RAG by modeling knowledge as entity-relation graphs, but still face challenges in high construction cost, fixed one-time retrieval, and reliance on long-context reasoning and prompt design. To address these challenges, we propose Graph-R1, an agentic GraphRAG framework via end-to-end reinforcement learning (RL). It introduces lightweight knowledge hypergraph construction, models retrieval as a multi-turn agent-environment interaction, and optimizes the agent process via an end-to-end reward mechanism. Experiments on standard RAG datasets show that Graph-R1 outperforms traditional GraphRAG and RL-enhanced RAG methods in reasoning accuracy, retrieval efficiency, and generation quality.
HyperGraphRAG: Retrieval-Augmented Generation with Hypergraph-Structured Knowledge Representation
Mar 27, 2025While standard Retrieval-Augmented Generation (RAG) based on chunks, GraphRAG structures knowledge as graphs to leverage the relations among entities. However, previous GraphRAG methods are limited by binary relations: one edge in the graph only connects two entities, which cannot well model the n-ary relations among more than two entities that widely exist in reality. To address this limitation, we propose HyperGraphRAG, a novel hypergraph-based RAG method that represents n-ary relational facts via hyperedges, modeling the complicated n-ary relations in the real world. To retrieve and generate over hypergraphs, we introduce a complete pipeline with a hypergraph construction method, a hypergraph retrieval strategy, and a hypergraph-guided generation mechanism. Experiments across medicine, agriculture, computer science, and law demonstrate that HyperGraphRAG outperforms standard RAG and GraphRAG in accuracy and generation quality.
KBQA-o1: Agentic Knowledge Base Question Answering with Monte Carlo Tree Search
Jan 31, 2025



Knowledge Base Question Answering (KBQA) aims to answer natural language questions with a large-scale structured knowledge base (KB). Despite advancements with large language models (LLMs), KBQA still faces challenges in weak KB awareness, imbalance between effectiveness and efficiency, and high reliance on annotated data. To address these challenges, we propose KBQA-o1, a novel agentic KBQA method with Monte Carlo Tree Search (MCTS). It introduces a ReAct-based agent process for stepwise logical form generation with KB environment exploration. Moreover, it employs MCTS, a heuristic search method driven by policy and reward models, to balance agentic exploration's performance and search space. With heuristic exploration, KBQA-o1 generates high-quality annotations for further improvement by incremental fine-tuning. Experimental results show that KBQA-o1 outperforms previous low-resource KBQA methods with limited annotated data, boosting Llama-3.1-8B model's GrailQA F1 performance to 78.5% compared to 48.5% of the previous sota method with GPT-3.5-turbo.
Meta In-Context Learning Makes Large Language Models Better Zero and Few-Shot Relation Extractors
Apr 27, 2024



Relation extraction (RE) is an important task that aims to identify the relationships between entities in texts. While large language models (LLMs) have revealed remarkable in-context learning (ICL) capability for general zero and few-shot learning, recent studies indicate that current LLMs still struggle with zero and few-shot RE. Previous studies are mainly dedicated to design prompt formats and select good examples for improving ICL-based RE. Although both factors are vital for ICL, if one can fundamentally boost the ICL capability of LLMs in RE, the zero and few-shot RE performance via ICL would be significantly improved. To this end, we introduce \textsc{Micre} (\textbf{M}eta \textbf{I}n-\textbf{C}ontext learning of LLMs for \textbf{R}elation \textbf{E}xtraction), a new meta-training framework for zero and few-shot RE where an LLM is tuned to do ICL on a diverse collection of RE datasets (i.e., learning to learn in context for RE). Through meta-training, the model becomes more effectively to learn a new RE task in context by conditioning on a few training examples with no parameter updates or task-specific templates at inference time, enabling better zero and few-shot task generalization. We experiment \textsc{Micre} on various LLMs with different model scales and 12 public RE datasets, and then evaluate it on unseen RE benchmarks under zero and few-shot settings. \textsc{Micre} delivers comparable or superior performance compared to a range of baselines including supervised fine-tuning and typical in-context learning methods. We find that the gains are particular significant for larger model scales, and using a diverse set of the meta-training RE datasets is key to improvements. Empirically, we show that \textsc{Micre} can transfer the relation semantic knowledge via relation label name during inference on target RE datasets.
Recall, Retrieve and Reason: Towards Better In-Context Relation Extraction
Apr 27, 2024
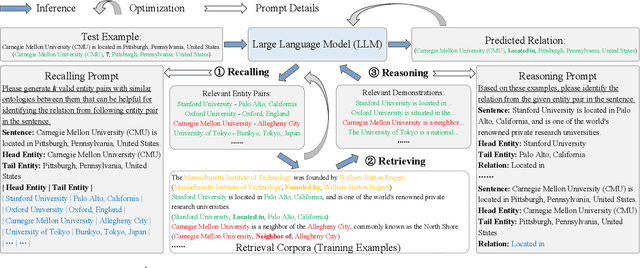
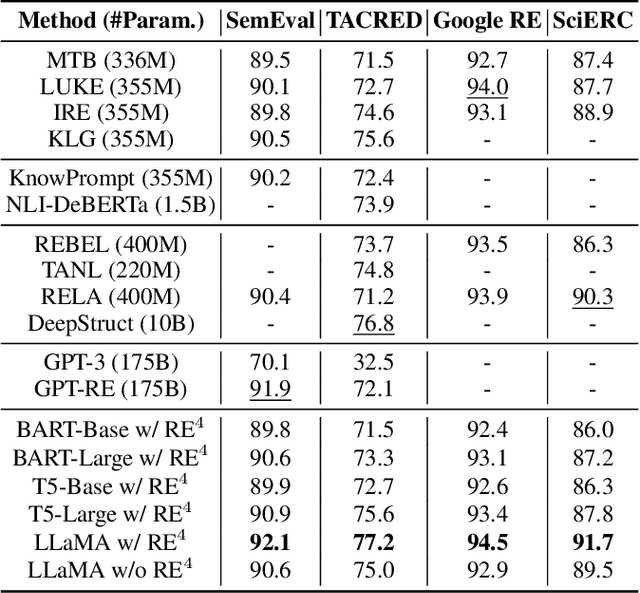
Relation extraction (RE) aims to identify relations between entities mentioned in texts. Although large language models (LLMs) have demonstrated impressive in-context learning (ICL) abilities in various tasks, they still suffer from poor performances compared to most supervised fine-tuned RE methods. Utilizing ICL for RE with LLMs encounters two challenges: (1) retrieving good demonstrations from training examples, and (2) enabling LLMs exhibit strong ICL abilities in RE. On the one hand, retrieving good demonstrations is a non-trivial process in RE, which easily results in low relevance regarding entities and relations. On the other hand, ICL with an LLM achieves poor performance in RE while RE is different from language modeling in nature or the LLM is not large enough. In this work, we propose a novel recall-retrieve-reason RE framework that synergizes LLMs with retrieval corpora (training examples) to enable relevant retrieving and reliable in-context reasoning. Specifically, we distill the consistently ontological knowledge from training datasets to let LLMs generate relevant entity pairs grounded by retrieval corpora as valid queries. These entity pairs are then used to retrieve relevant training examples from the retrieval corpora as demonstrations for LLMs to conduct better ICL via instruction tuning. Extensive experiments on different LLMs and RE datasets demonstrate that our method generates relevant and valid entity pairs and boosts ICL abilities of LLMs, achieving competitive or new state-of-the-art performance on sentence-level RE compared to previous supervised fine-tuning methods and ICL-based methods.
Empirical Analysis of Dialogue Relation Extraction with Large Language Models
Apr 27, 2024Dialogue relation extraction (DRE) aims to extract relations between two arguments within a dialogue, which is more challenging than standard RE due to the higher person pronoun frequency and lower information density in dialogues. However, existing DRE methods still suffer from two serious issues: (1) hard to capture long and sparse multi-turn information, and (2) struggle to extract golden relations based on partial dialogues, which motivates us to discover more effective methods that can alleviate the above issues. We notice that the rise of large language models (LLMs) has sparked considerable interest in evaluating their performance across diverse tasks. To this end, we initially investigate the capabilities of different LLMs in DRE, considering both proprietary models and open-source models. Interestingly, we discover that LLMs significantly alleviate two issues in existing DRE methods. Generally, we have following findings: (1) scaling up model size substantially boosts the overall DRE performance and achieves exceptional results, tackling the difficulty of capturing long and sparse multi-turn information; (2) LLMs encounter with much smaller performance drop from entire dialogue setting to partial dialogue setting compared to existing methods; (3) LLMs deliver competitive or superior performances under both full-shot and few-shot settings compared to current state-of-the-art; (4) LLMs show modest performances on inverse relations but much stronger improvements on general relations, and they can handle dialogues of various lengths especially for longer sequences.
ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models
Oct 13, 2023



Knowledge Base Question Answering (KBQA) aims to derive answers to natural language questions over large-scale knowledge bases (KBs), which are generally divided into two research components: knowledge retrieval and semantic parsing. However, three core challenges remain, including inefficient knowledge retrieval, retrieval errors adversely affecting semantic parsing, and the complexity of previous KBQA methods. In the era of large language models (LLMs), we introduce ChatKBQA, a novel generate-then-retrieve KBQA framework built on fine-tuning open-source LLMs such as Llama-2, ChatGLM2 and Baichuan2. ChatKBQA proposes generating the logical form with fine-tuned LLMs first, then retrieving and replacing entities and relations through an unsupervised retrieval method, which improves both generation and retrieval more straightforwardly. Experimental results reveal that ChatKBQA achieves new state-of-the-art performance on standard KBQA datasets, WebQSP, and ComplexWebQuestions (CWQ). This work also provides a new paradigm for combining LLMs with knowledge graphs (KGs) for interpretable and knowledge-required question answering. Our code is publicly available.
Text2NKG: Fine-Grained N-ary Relation Extraction for N-ary relational Knowledge Graph Construction
Oct 12, 2023Beyond traditional binary relational facts, n-ary relational knowledge graphs (NKGs) are comprised of n-ary relational facts containing more than two entities, which are closer to real-world facts with broader applications. However, the construction of NKGs still significantly relies on manual labor, and n-ary relation extraction still remains at a course-grained level, which is always in a single schema and fixed arity of entities. To address these restrictions, we propose Text2NKG, a novel fine-grained n-ary relation extraction framework for n-ary relational knowledge graph construction. We introduce a span-tuple classification approach with hetero-ordered merging to accomplish fine-grained n-ary relation extraction in different arity. Furthermore, Text2NKG supports four typical NKG schemas: hyper-relational schema, event-based schema, role-based schema, and hypergraph-based schema, with high flexibility and practicality. Experimental results demonstrate that Text2NKG outperforms the previous state-of-the-art model by nearly 20\% points in the $F_1$ scores on the fine-grained n-ary relation extraction benchmark in the hyper-relational schema. Our code and datasets are publicly available.
HAHE: Hierarchical Attention for Hyper-Relational Knowledge Graphs in Global and Local Level
May 15, 2023Link Prediction on Hyper-relational Knowledge Graphs (HKG) is a worthwhile endeavor. HKG consists of hyper-relational facts (H-Facts), composed of a main triple and several auxiliary attribute-value qualifiers, which can effectively represent factually comprehensive information. The internal structure of HKG can be represented as a hypergraph-based representation globally and a semantic sequence-based representation locally. However, existing research seldom simultaneously models the graphical and sequential structure of HKGs, limiting HKGs' representation. To overcome this limitation, we propose a novel Hierarchical Attention model for HKG Embedding (HAHE), including global-level and local-level attention. The global-level attention can model the graphical structure of HKG using hypergraph dual-attention layers, while the local-level attention can learn the sequential structure inside H-Facts via heterogeneous self-attention layers. Experiment results indicate that HAHE achieves state-of-the-art performance in link prediction tasks on HKG standard datasets. In addition, HAHE addresses the issue of HKG multi-position prediction for the first time, increasing the applicability of the HKG link prediction task. Our code is publicly available.
NQE: N-ary Query Embedding for Complex Query Answering over Hyper-relational Knowledge Graphs
Nov 24, 2022Complex query answering (CQA) is an essential task for multi-hop and logical reasoning on knowledge graphs (KGs). Currently, most approaches are limited to queries among binary relational facts and pay less attention to n-ary facts (n>=2) containing more than two entities, which are more prevalent in the real world. Moreover, previous CQA methods can only make predictions for a few given types of queries and cannot be flexibly extended to more complex logical queries, which significantly limits their applications. To overcome these challenges, in this work, we propose a novel N-ary Query Embedding (NQE) model for CQA over hyper-relational knowledge graphs (HKGs), which include massive n-ary facts. The NQE utilizes a dual-heterogeneous Transformer encoder and fuzzy logic theory to satisfy all n-ary FOL queries, including existential quantifiers, conjunction, disjunction, and negation. We also propose a parallel processing algorithm that can train or predict arbitrary n-ary FOL queries in a single batch, regardless of the kind of each query, with good flexibility and extensibility. In addition, we generate a new CQA dataset WD50K-NFOL, including diverse n-ary FOL queries over WD50K. Experimental results on WD50K-NFOL and other standard CQA datasets show that NQE is the state-of-the-art CQA method over HKGs with good generalization capability. Our code and dataset are publicly available.