 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinMMDocR: Benchmarking Financial Multimodal Reasoning with Scenario Awareness, Document Understanding, and Multi-Step Computation
Dec 31, 2025We introduce FinMMDocR, a novel bilingual multimodal benchmark for evaluating multimodal large language models (MLLMs) on real-world financial numerical reasoning. Compared to existing benchmarks, our work delivers three major advancements. (1) Scenario Awareness: 57.9% of 1,200 expert-annotated problems incorporate 12 types of implicit financial scenarios (e.g., Portfolio Management), challenging models to perform expert-level reasoning based on assumptions; (2) Document Understanding: 837 Chinese/English documents spanning 9 types (e.g., Company Research) average 50.8 pages with rich visual elements, significantly surpassing existing benchmarks in both breadth and depth of financial documents; (3) Multi-Step Computation: Problems demand 11-step reasoning on average (5.3 extraction + 5.7 calculation steps), with 65.0% requiring cross-page evidence (2.4 pages average). The best-performing MLLM achieves only 58.0% accuracy, and different retrieval-augmented generation (RAG) methods show significant performance variations on this task. We expect FinMMDocR to drive improvements in MLLMs and reasoning-enhanced methods on complex multimodal reasoning tasks in real-world scenarios.
FinMMR: Make Financial Numerical Reasoning More Multimodal, Comprehensive, and Challenging
Aug 06, 2025We present FinMMR, a novel bilingual multimodal benchmark tailored to evaluate the reasoning capabilities of multimodal large language models (MLLMs) in financial numerical reasoning tasks. Compared to existing benchmarks, our work introduces three significant advancements. (1) Multimodality: We meticulously transform existing financial reasoning benchmarks, and construct novel questions from the latest Chinese financial research reports. FinMMR comprises 4.3K questions and 8.7K images spanning 14 categories, including tables, bar charts, and ownership structure charts. (2) Comprehensiveness: FinMMR encompasses 14 financial subdomains, including corporate finance, banking, and industry analysis, significantly exceeding existing benchmarks in financial domain knowledge breadth. (3) Challenge: Models are required to perform multi-step precise numerical reasoning by integrating financial knowledge with the understanding of complex financial images and text. The best-performing MLLM achieves only 53.0% accuracy on Hard problems. We believe that FinMMR will drive advancements in enhancing the reasoning capabilities of MLLMs in real-world scenarios.
FinanceReasoning: Benchmarking Financial Numerical Reasoning More Credible, Comprehensive and Challenging
Jun 06, 2025We introduce FinanceReasoning, a novel benchmark designed to evaluate the reasoning capabilities of large reasoning models (LRMs) in financial numerical reasoning problems. Compared to existing benchmarks, our work provides three key advancements. (1) Credibility: We update 15.6% of the questions from four public datasets, annotating 908 new questions with detailed Python solutions and rigorously refining evaluation standards. This enables an accurate assessment of the reasoning improvements of LRMs. (2) Comprehensiveness: FinanceReasoning covers 67.8% of financial concepts and formulas, significantly surpassing existing datasets. Additionally, we construct 3,133 Python-formatted functions, which enhances LRMs' financial reasoning capabilities through refined knowledge (e.g., 83.2% $\rightarrow$ 91.6% for GPT-4o). (3) Challenge: Models are required to apply multiple financial formulas for precise numerical reasoning on 238 Hard problems. The best-performing model (i.e., OpenAI o1 with PoT) achieves 89.1% accuracy, yet LRMs still face challenges in numerical precision. We demonstrate that combining Reasoner and Programmer models can effectively enhance LRMs' performance (e.g., 83.2% $\rightarrow$ 87.8% for DeepSeek-R1). Our work paves the way for future research on evaluating and improving LRMs in domain-specific complex reasoning tasks.
GaussianIP: Identity-Preserving Realistic 3D Human Generation via Human-Centric Diffusion Prior
Mar 14, 2025Text-guided 3D human generation has advanced with the development of efficient 3D representations and 2D-lifting methods like Score Distillation Sampling (SDS). However, current methods suffer from prolonged training times and often produce results that lack fine facial and garment details. In this paper, we propose GaussianIP, an effective two-stage framework for generating identity-preserving realistic 3D humans from text and image prompts. Our core insight is to leverage human-centric knowledge to facilitate the generation process. In stage 1, we propose a novel Adaptive Human Distillation Sampling (AHDS) method to rapidly generate a 3D human that maintains high identity consistency with the image prompt and achieves a realistic appearance. Compared to traditional SDS methods, AHDS better aligns with the human-centric generation process, enhancing visual quality with notably fewer training steps. To further improve the visual quality of the face and clothes regions, we design a View-Consistent Refinement (VCR) strategy in stage 2. Specifically, it produces detail-enhanced results of the multi-view images from stage 1 iteratively, ensuring the 3D texture consistency across views via mutual attention and distance-guided attention fusion. Then a polished version of the 3D human can be achieved by directly perform reconstruction with the refined images. Extensive experiments demonstrate that GaussianIP outperforms existing methods in both visual quality and training efficiency, particularly in generating identity-preserving results. Our code is available at: https://github.com/silence-tang/GaussianIP.
3D$^2$-Actor: Learning Pose-Conditioned 3D-Aware Denoiser for Realistic Gaussian Avatar Modeling
Dec 16, 2024



Advancements in neural implicit representations and differentiable rendering have markedly improved the ability to learn animatable 3D avatars from sparse multi-view RGB videos. However, current methods that map observation space to canonical space often face challenges in capturing pose-dependent details and generalizing to novel poses. While diffusion models have demonstrated remarkable zero-shot capabilities in 2D image generation, their potential for creating animatable 3D avatars from 2D inputs remains underexplored. In this work, we introduce 3D$^2$-Actor, a novel approach featuring a pose-conditioned 3D-aware human modeling pipeline that integrates iterative 2D denoising and 3D rectifying steps. The 2D denoiser, guided by pose cues, generates detailed multi-view images that provide the rich feature set necessary for high-fidelity 3D reconstruction and pose rendering. Complementing this, our Gaussian-based 3D rectifier renders images with enhanced 3D consistency through a two-stage projection strategy and a novel local coordinate representation. Additionally, we propose an innovative sampling strategy to ensure smooth temporal continuity across frames in video synthesis. Our method effectively addresses the limitations of traditional numerical solutions in handling ill-posed mappings, producing realistic and animatable 3D human avatars. Experimental results demonstrate that 3D$^2$-Actor excels in high-fidelity avatar modeling and robustly generalizes to novel poses. Code is available at: https://github.com/silence-tang/GaussianActor.
Bandwidth-Aware and Overlap-Weighted Compression for Communication-Efficient Federated Learning
Aug 27, 2024
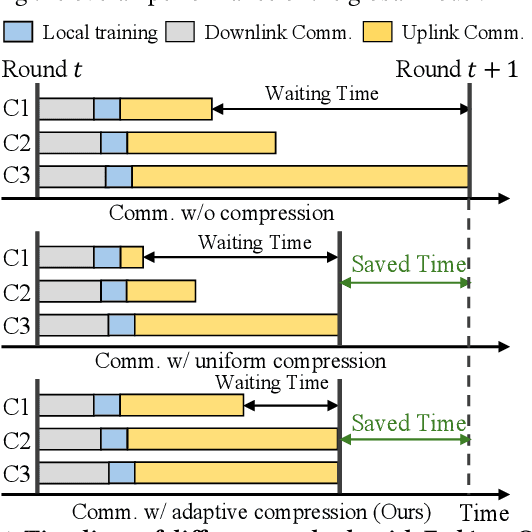

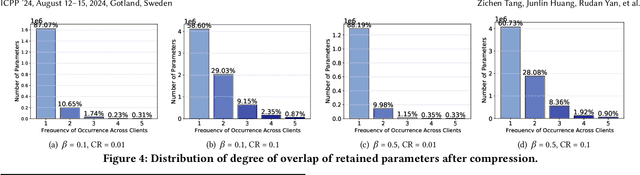
Current data compression methods, such as sparsification in Federated Averaging (FedAvg), effectively enhance the communication efficiency of Federated Learning (FL). However, these methods encounter challenges such as the straggler problem and diminished model performance due to heterogeneous bandwidth and non-IID (Independently and Identically Distributed) data. To address these issues, we introduce a bandwidth-aware compression framework for FL, aimed at improving communication efficiency while mitigating the problems associated with non-IID data. First, our strategy dynamically adjusts compression ratios according to bandwidth, enabling clients to upload their models at a close pace, thus exploiting the otherwise wasted time to transmit more data. Second, we identify the non-overlapped pattern of retained parameters after compression, which results in diminished client update signals due to uniformly averaged weights. Based on this finding, we propose a parameter mask to adjust the client-averaging coefficients at the parameter level, thereby more closely approximating the original updates, and improving the training convergence under heterogeneous environments. Our evaluations reveal that our method significantly boosts model accuracy, with a maximum improvement of 13% over the uncompressed FedAvg. Moreover, it achieves a $3.37\times$ speedup in reaching the target accuracy compared to FedAvg with a Top-K compressor, demonstrating its effectiveness in accelerating convergence with compression. The integration of common compression techniques into our framework further establishes its potential as a versatile foundation for future cross-device, communication-efficient FL research, addressing critical challenges in FL and advancing the field of distributed machine learning.
ArtNeRF: A Stylized Neural Field for 3D-Aware Cartoonized Face Synthesis
Apr 26, 2024



Recent advances in generative visual models and neural radiance fields have greatly boosted 3D-aware image synthesis and stylization tasks. However, previous NeRF-based work is limited to single scene stylization, training a model to generate 3D-aware cartoon faces with arbitrary styles remains unsolved. We propose ArtNeRF, a novel face stylization framework derived from 3D-aware GAN to tackle this problem. In this framework, we utilize an expressive generator to synthesize stylized faces and a triple-branch discriminator module to improve the visual quality and style consistency of the generated faces. Specifically, a style encoder based on contrastive learning is leveraged to extract robust low-dimensional embeddings of style images, empowering the generator with the knowledge of various styles. To smooth the training process of cross-domain transfer learning, we propose an adaptive style blending module which helps inject style information and allows users to freely tune the level of stylization. We further introduce a neural rendering module to achieve efficient real-time rendering of images with higher resolutions. Extensive experiments demonstrate that ArtNeRF is versatile in generating high-quality 3D-aware cartoon faces with arbitrary styles.
ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models
Oct 13, 2023



Knowledge Base Question Answering (KBQA) aims to derive answers to natural language questions over large-scale knowledge bases (KBs), which are generally divided into two research components: knowledge retrieval and semantic parsing. However, three core challenges remain, including inefficient knowledge retrieval, retrieval errors adversely affecting semantic parsing, and the complexity of previous KBQA methods. In the era of large language models (LLMs), we introduce ChatKBQA, a novel generate-then-retrieve KBQA framework built on fine-tuning open-source LLMs such as Llama-2, ChatGLM2 and Baichuan2. ChatKBQA proposes generating the logical form with fine-tuned LLMs first, then retrieving and replacing entities and relations through an unsupervised retrieval method, which improves both generation and retrieval more straightforwardly. Experimental results reveal that ChatKBQA achieves new state-of-the-art performance on standard KBQA datasets, WebQSP, and ComplexWebQuestions (CWQ). This work also provides a new paradigm for combining LLMs with knowledge graphs (KGs) for interpretable and knowledge-required question answering. Our code is publicly available.
Text2NKG: Fine-Grained N-ary Relation Extraction for N-ary relational Knowledge Graph Construction
Oct 12, 2023Beyond traditional binary relational facts, n-ary relational knowledge graphs (NKGs) are comprised of n-ary relational facts containing more than two entities, which are closer to real-world facts with broader applications. However, the construction of NKGs still significantly relies on manual labor, and n-ary relation extraction still remains at a course-grained level, which is always in a single schema and fixed arity of entities. To address these restrictions, we propose Text2NKG, a novel fine-grained n-ary relation extraction framework for n-ary relational knowledge graph construction. We introduce a span-tuple classification approach with hetero-ordered merging to accomplish fine-grained n-ary relation extraction in different arity. Furthermore, Text2NKG supports four typical NKG schemas: hyper-relational schema, event-based schema, role-based schema, and hypergraph-based schema, with high flexibility and practicality. Experimental results demonstrate that Text2NKG outperforms the previous state-of-the-art model by nearly 20\% points in the $F_1$ scores on the fine-grained n-ary relation extraction benchmark in the hyper-relational schema. Our code and datasets are publicly available.
HAHE: Hierarchical Attention for Hyper-Relational Knowledge Graphs in Global and Local Level
May 15, 2023Link Prediction on Hyper-relational Knowledge Graphs (HKG) is a worthwhile endeavor. HKG consists of hyper-relational facts (H-Facts), composed of a main triple and several auxiliary attribute-value qualifiers, which can effectively represent factually comprehensive information. The internal structure of HKG can be represented as a hypergraph-based representation globally and a semantic sequence-based representation locally. However, existing research seldom simultaneously models the graphical and sequential structure of HKGs, limiting HKGs' representation. To overcome this limitation, we propose a novel Hierarchical Attention model for HKG Embedding (HAHE), including global-level and local-level attention. The global-level attention can model the graphical structure of HKG using hypergraph dual-attention layers, while the local-level attention can learn the sequential structure inside H-Facts via heterogeneous self-attention layers. Experiment results indicate that HAHE achieves state-of-the-art performance in link prediction tasks on HKG standard datasets. In addition, HAHE addresses the issue of HKG multi-position prediction for the first time, increasing the applicability of the HKG link prediction task. Our code is publicly available.