 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning
Jul 29, 2025Retrieval-Augmented Generation (RAG) mitigates hallucination in LLMs by incorporating external knowledge, but relies on chunk-based retrieval that lacks structural semantics. GraphRAG methods improve RAG by modeling knowledge as entity-relation graphs, but still face challenges in high construction cost, fixed one-time retrieval, and reliance on long-context reasoning and prompt design. To address these challenges, we propose Graph-R1, an agentic GraphRAG framework via end-to-end reinforcement learning (RL). It introduces lightweight knowledge hypergraph construction, models retrieval as a multi-turn agent-environment interaction, and optimizes the agent process via an end-to-end reward mechanism. Experiments on standard RAG datasets show that Graph-R1 outperforms traditional GraphRAG and RL-enhanced RAG methods in reasoning accuracy, retrieval efficiency, and generation quality.
HyperGraphRAG: Retrieval-Augmented Generation with Hypergraph-Structured Knowledge Representation
Mar 27, 2025While standard Retrieval-Augmented Generation (RAG) based on chunks, GraphRAG structures knowledge as graphs to leverage the relations among entities. However, previous GraphRAG methods are limited by binary relations: one edge in the graph only connects two entities, which cannot well model the n-ary relations among more than two entities that widely exist in reality. To address this limitation, we propose HyperGraphRAG, a novel hypergraph-based RAG method that represents n-ary relational facts via hyperedges, modeling the complicated n-ary relations in the real world. To retrieve and generate over hypergraphs, we introduce a complete pipeline with a hypergraph construction method, a hypergraph retrieval strategy, and a hypergraph-guided generation mechanism. Experiments across medicine, agriculture, computer science, and law demonstrate that HyperGraphRAG outperforms standard RAG and GraphRAG in accuracy and generation quality.
SQL-o1: A Self-Reward Heuristic Dynamic Search Method for Text-to-SQL
Feb 17, 2025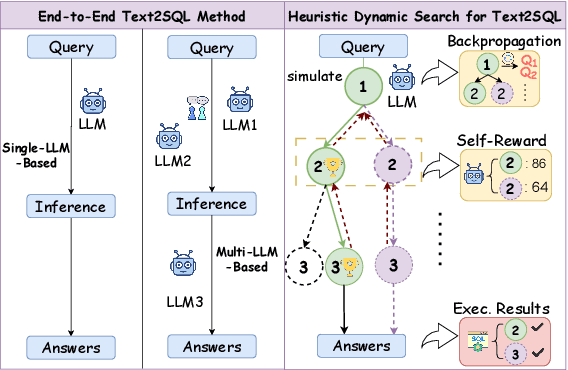


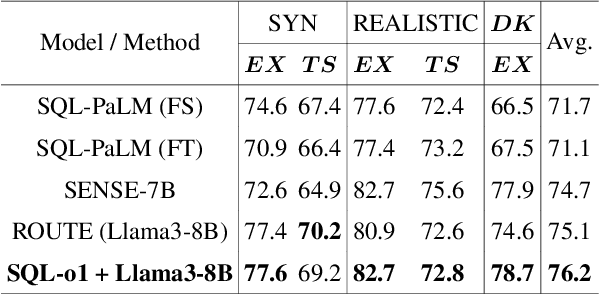
The Text-to-SQL(Text2SQL) task aims to convert natural language queries into executable SQL queries. Thanks to the application of large language models (LLMs), significant progress has been made in this field. However, challenges such as model scalability, limited generation space, and coherence issues in SQL generation still persist. To address these issues, we propose SQL-o1, a Self-Reward-based heuristic search method designed to enhance the reasoning ability of LLMs in SQL query generation. SQL-o1 combines Monte Carlo Tree Search (MCTS) for heuristic process-level search and constructs a Schema-Aware dataset to help the model better understand database schemas. Extensive experiments on the Bird and Spider datasets demonstrate that SQL-o1 improves execution accuracy by 10.8\% on the complex Bird dataset compared to the latest baseline methods, even outperforming GPT-4-based approaches. Additionally, SQL-o1 excels in few-shot learning scenarios and shows strong cross-model transferability. Our code is publicly available at:https://github.com/ShuaiLyu0110/SQL-o1.
KBQA-o1: Agentic Knowledge Base Question Answering with Monte Carlo Tree Search
Jan 31, 2025



Knowledge Base Question Answering (KBQA) aims to answer natural language questions with a large-scale structured knowledge base (KB). Despite advancements with large language models (LLMs), KBQA still faces challenges in weak KB awareness, imbalance between effectiveness and efficiency, and high reliance on annotated data. To address these challenges, we propose KBQA-o1, a novel agentic KBQA method with Monte Carlo Tree Search (MCTS). It introduces a ReAct-based agent process for stepwise logical form generation with KB environment exploration. Moreover, it employs MCTS, a heuristic search method driven by policy and reward models, to balance agentic exploration's performance and search space. With heuristic exploration, KBQA-o1 generates high-quality annotations for further improvement by incremental fine-tuning. Experimental results show that KBQA-o1 outperforms previous low-resource KBQA methods with limited annotated data, boosting Llama-3.1-8B model's GrailQA F1 performance to 78.5% compared to 48.5% of the previous sota method with GPT-3.5-turbo.
TSVC:Tripartite Learning with Semantic Variation Consistency for Robust Image-Text Retrieval
Jan 19, 2025Cross-modal retrieval maps data under different modality via semantic relevance. Existing approaches implicitly assume that data pairs are well-aligned and ignore the widely existing annotation noise, i.e., noisy correspondence (NC). Consequently, it inevitably causes performance degradation. Despite attempts that employ the co-teaching paradigm with identical architectures to provide distinct data perspectives, the differences between these architectures are primarily stemmed from random initialization. Thus, the model becomes increasingly homogeneous along with the training process. Consequently, the additional information brought by this paradigm is severely limited. In order to resolve this problem, we introduce a Tripartite learning with Semantic Variation Consistency (TSVC) for robust image-text retrieval. We design a tripartite cooperative learning mechanism comprising a Coordinator, a Master, and an Assistant model. The Coordinator distributes data, and the Assistant model supports the Master model's noisy label prediction with diverse data. Moreover, we introduce a soft label estimation method based on mutual information variation, which quantifies the noise in new samples and assigns corresponding soft labels. We also present a new loss function to enhance robustness and optimize training effectiveness. Extensive experiments on three widely used datasets demonstrate that, even at increasing noise ratios, TSVC exhibits significant advantages in retrieval accuracy and maintains stable training performance.
CP-Prompt: Composition-Based Cross-modal Prompting for Domain-Incremental Continual Learning
Aug 02, 2024The key challenge of cross-modal domain-incremental learning (DIL) is to enable the learning model to continuously learn from novel data with different feature distributions under the same task without forgetting old ones. However, existing top-performing methods still cause high forgetting rates, by lacking intra-domain knowledge extraction and inter-domain common prompting strategy. In this paper, we propose a simple yet effective framework, CP-Prompt, by training limited parameters to instruct a pre-trained model to learn new domains and avoid forgetting existing feature distributions. CP-Prompt captures intra-domain knowledge by compositionally inserting personalized prompts on multi-head self-attention layers and then learns the inter-domain knowledge with a common prompting strategy. CP-Prompt shows superiority compared with state-of-the-art baselines among three widely evaluated DIL tasks. The source code is available at https://github.com/dannis97500/CP_Prompt.
Augmentation-Free Dense Contrastive Knowledge Distillation for Efficient Semantic Segmentation
Dec 07, 2023



In recent years, knowledge distillation methods based on contrastive learning have achieved promising results on image classification and object detection tasks. However, in this line of research, we note that less attention is paid to semantic segmentation. Existing methods heavily rely on data augmentation and memory buffer, which entail high computational resource demands when applying them to handle semantic segmentation that requires to preserve high-resolution feature maps for making dense pixel-wise predictions. In order to address this problem, we present Augmentation-free Dense Contrastive Knowledge Distillation (Af-DCD), a new contrastive distillation learning paradigm to train compact and accurate deep neural networks for semantic segmentation applications. Af-DCD leverages a masked feature mimicking strategy, and formulates a novel contrastive learning loss via taking advantage of tactful feature partitions across both channel and spatial dimensions, allowing to effectively transfer dense and structured local knowledge learnt by the teacher model to a target student model while maintaining training efficiency. Extensive experiments on five mainstream benchmarks with various teacher-student network pairs demonstrate the effectiveness of our approach. For instance, the DeepLabV3-Res18|DeepLabV3-MBV2 model trained by Af-DCD reaches 77.03%|76.38% mIOU on Cityscapes dataset when choosing DeepLabV3-Res101 as the teacher, setting new performance records. Besides that, Af-DCD achieves an absolute mIOU improvement of 3.26%|3.04%|2.75%|2.30%|1.42% compared with individually trained counterpart on Cityscapes|Pascal VOC|Camvid|ADE20K|COCO-Stuff-164K. Code is available at https://github.com/OSVAI/Af-DCD
ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models
Oct 13, 2023



Knowledge Base Question Answering (KBQA) aims to derive answers to natural language questions over large-scale knowledge bases (KBs), which are generally divided into two research components: knowledge retrieval and semantic parsing. However, three core challenges remain, including inefficient knowledge retrieval, retrieval errors adversely affecting semantic parsing, and the complexity of previous KBQA methods. In the era of large language models (LLMs), we introduce ChatKBQA, a novel generate-then-retrieve KBQA framework built on fine-tuning open-source LLMs such as Llama-2, ChatGLM2 and Baichuan2. ChatKBQA proposes generating the logical form with fine-tuned LLMs first, then retrieving and replacing entities and relations through an unsupervised retrieval method, which improves both generation and retrieval more straightforwardly. Experimental results reveal that ChatKBQA achieves new state-of-the-art performance on standard KBQA datasets, WebQSP, and ComplexWebQuestions (CWQ). This work also provides a new paradigm for combining LLMs with knowledge graphs (KGs) for interpretable and knowledge-required question answering. Our code is publicly available.
Text2NKG: Fine-Grained N-ary Relation Extraction for N-ary relational Knowledge Graph Construction
Oct 12, 2023Beyond traditional binary relational facts, n-ary relational knowledge graphs (NKGs) are comprised of n-ary relational facts containing more than two entities, which are closer to real-world facts with broader applications. However, the construction of NKGs still significantly relies on manual labor, and n-ary relation extraction still remains at a course-grained level, which is always in a single schema and fixed arity of entities. To address these restrictions, we propose Text2NKG, a novel fine-grained n-ary relation extraction framework for n-ary relational knowledge graph construction. We introduce a span-tuple classification approach with hetero-ordered merging to accomplish fine-grained n-ary relation extraction in different arity. Furthermore, Text2NKG supports four typical NKG schemas: hyper-relational schema, event-based schema, role-based schema, and hypergraph-based schema, with high flexibility and practicality. Experimental results demonstrate that Text2NKG outperforms the previous state-of-the-art model by nearly 20\% points in the $F_1$ scores on the fine-grained n-ary relation extraction benchmark in the hyper-relational schema. Our code and datasets are publicly available.
HAHE: Hierarchical Attention for Hyper-Relational Knowledge Graphs in Global and Local Level
May 15, 2023



Link Prediction on Hyper-relational Knowledge Graphs (HKG) is a worthwhile endeavor. HKG consists of hyper-relational facts (H-Facts), composed of a main triple and several auxiliary attribute-value qualifiers, which can effectively represent factually comprehensive information. The internal structure of HKG can be represented as a hypergraph-based representation globally and a semantic sequence-based representation locally. However, existing research seldom simultaneously models the graphical and sequential structure of HKGs, limiting HKGs' representation. To overcome this limitation, we propose a novel Hierarchical Attention model for HKG Embedding (HAHE), including global-level and local-level attention. The global-level attention can model the graphical structure of HKG using hypergraph dual-attention layers, while the local-level attention can learn the sequential structure inside H-Facts via heterogeneous self-attention layers. Experiment results indicate that HAHE achieves state-of-the-art performance in link prediction tasks on HKG standard datasets. In addition, HAHE addresses the issue of HKG multi-position prediction for the first time, increasing the applicability of the HKG link prediction task. Our code is publicly available.