 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleKD: Strong Vision Transformers Could Be Excellent Teachers
Nov 11, 2024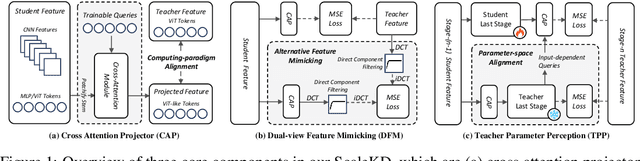
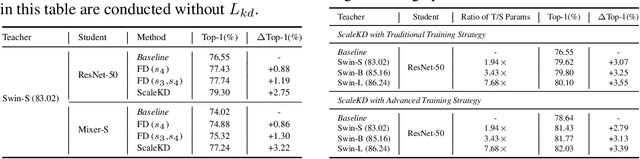
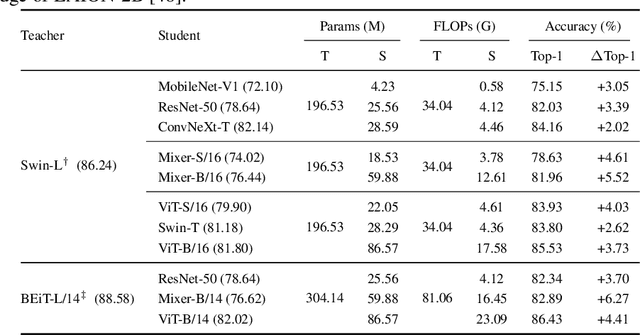
In this paper, we question if well pre-trained vision transformer (ViT) models could be used as teachers that exhibit scalable properties to advance cross architecture knowledge distillation (KD) research, in the context of using large-scale datasets for evaluation. To make this possible, our analysis underlines the importance of seeking effective strategies to align (1) feature computing paradigm differences, (2) model scale differences, and (3) knowledge density differences. By combining three coupled components namely cross attention projector, dual-view feature mimicking and teacher parameter perception tailored to address the above problems, we present a simple and effective KD method, called ScaleKD. Our method can train student backbones that span across a variety of convolutional neural network (CNN), multi-layer perceptron (MLP), and ViT architectures on image classification datasets, achieving state-of-the-art distillation performance. For instance, taking a well pre-trained Swin-L as the teacher model, our method gets 75.15%|82.03%|84.16%|78.63%|81.96%|83.93%|83.80%|85.53% top-1 accuracies for MobileNet-V1|ResNet-50|ConvNeXt-T|Mixer-S/16|Mixer-B/16|ViT-S/16|Swin-T|ViT-B/16 models trained on ImageNet-1K dataset from scratch, showing 3.05%|3.39%|2.02%|4.61%|5.52%|4.03%|2.62%|3.73% absolute gains to the individually trained counterparts. Intriguingly, when scaling up the size of teacher models or their pre-training datasets, our method showcases the desired scalable properties, bringing increasingly larger gains to student models. The student backbones trained by our method transfer well on downstream MS-COCO and ADE20K datasets. More importantly, our method could be used as a more efficient alternative to the time-intensive pre-training paradigm for any target student model if a strong pre-trained ViT is available, reducing the amount of viewed training samples up to 195x.
KernelWarehouse: Rethinking the Design of Dynamic Convolution
Jun 12, 2024



Dynamic convolution learns a linear mixture of n static kernels weighted with their input-dependent attentions, demonstrating superior performance than normal convolution. However, it increases the number of convolutional parameters by n times, and thus is not parameter efficient. This leads to no research progress that can allow researchers to explore the setting n>100 (an order of magnitude larger than the typical setting n<10) for pushing forward the performance boundary of dynamic convolution while enjoying parameter efficiency. To fill this gap, in this paper, we propose KernelWarehouse, a more general form of dynamic convolution, which redefines the basic concepts of ``kernels", ``assembling kernels" and ``attention function" through the lens of exploiting convolutional parameter dependencies within the same layer and across neighboring layers of a ConvNet. We testify the effectiveness of KernelWarehouse on ImageNet and MS-COCO datasets using various ConvNet architectures. Intriguingly, KernelWarehouse is also applicable to Vision Transformers, and it can even reduce the model size of a backbone while improving the model accuracy. For instance, KernelWarehouse (n=4) achieves 5.61%|3.90%|4.38% absolute top-1 accuracy gain on the ResNet18|MobileNetV2|DeiT-Tiny backbone, and KernelWarehouse (n=1/4) with 65.10% model size reduction still achieves 2.29% gain on the ResNet18 backbone. The code and models are available at https://github.com/OSVAI/KernelWarehouse.
Small Scale Data-Free Knowledge Distillation
Jun 12, 2024Data-free knowledge distillation is able to utilize the knowledge learned by a large teacher network to augment the training of a smaller student network without accessing the original training data, avoiding privacy, security, and proprietary risks in real applications. In this line of research, existing methods typically follow an inversion-and-distillation paradigm in which a generative adversarial network on-the-fly trained with the guidance of the pre-trained teacher network is used to synthesize a large-scale sample set for knowledge distillation. In this paper, we reexamine this common data-free knowledge distillation paradigm, showing that there is considerable room to improve the overall training efficiency through a lens of ``small-scale inverted data for knowledge distillation". In light of three empirical observations indicating the importance of how to balance class distributions in terms of synthetic sample diversity and difficulty during both data inversion and distillation processes, we propose Small Scale Data-free Knowledge Distillation SSD-KD. In formulation, SSD-KD introduces a modulating function to balance synthetic samples and a priority sampling function to select proper samples, facilitated by a dynamic replay buffer and a reinforcement learning strategy. As a result, SSD-KD can perform distillation training conditioned on an extremely small scale of synthetic samples (e.g., 10X less than the original training data scale), making the overall training efficiency one or two orders of magnitude faster than many mainstream methods while retaining superior or competitive model performance, as demonstrated on popular image classification and semantic segmentation benchmarks. The code is available at https://github.com/OSVAI/SSD-KD.
NOAH: Learning Pairwise Object Category Attentions for Image Classification
Feb 04, 2024A modern deep neural network (DNN) for image classification tasks typically consists of two parts: a backbone for feature extraction, and a head for feature encoding and class predication. We observe that the head structures of mainstream DNNs adopt a similar feature encoding pipeline, exploiting global feature dependencies while disregarding local ones. In this paper, we revisit the feature encoding problem, and propose Non-glObal Attentive Head (NOAH) that relies on a new form of dot-product attention called pairwise object category attention (POCA), efficiently exploiting spatially dense category-specific attentions to augment classification performance. NOAH introduces a neat combination of feature split, transform and merge operations to learn POCAs at local to global scales. As a drop-in design, NOAH can be easily used to replace existing heads of various types of DNNs, improving classification performance while maintaining similar model efficiency. We validate the effectiveness of NOAH on ImageNet classification benchmark with 25 DNN architectures spanning convolutional neural networks, vision transformers and multi-layer perceptrons. In general, NOAH is able to significantly improve the performance of lightweight DNNs, e.g., showing 3.14\%|5.3\%|1.9\% top-1 accuracy improvement to MobileNetV2 (0.5x)|Deit-Tiny (0.5x)|gMLP-Tiny (0.5x). NOAH also generalizes well when applied to medium-size and large-size DNNs. We further show that NOAH retains its efficacy on other popular multi-class and multi-label image classification benchmarks as well as in different training regimes, e.g., showing 3.6\%|1.1\% mAP improvement to large ResNet101|ViT-Large on MS-COCO dataset. Project page: https://github.com/OSVAI/NOAH.
Augmentation-Free Dense Contrastive Knowledge Distillation for Efficient Semantic Segmentation
Dec 07, 2023



In recent years, knowledge distillation methods based on contrastive learning have achieved promising results on image classification and object detection tasks. However, in this line of research, we note that less attention is paid to semantic segmentation. Existing methods heavily rely on data augmentation and memory buffer, which entail high computational resource demands when applying them to handle semantic segmentation that requires to preserve high-resolution feature maps for making dense pixel-wise predictions. In order to address this problem, we present Augmentation-free Dense Contrastive Knowledge Distillation (Af-DCD), a new contrastive distillation learning paradigm to train compact and accurate deep neural networks for semantic segmentation applications. Af-DCD leverages a masked feature mimicking strategy, and formulates a novel contrastive learning loss via taking advantage of tactful feature partitions across both channel and spatial dimensions, allowing to effectively transfer dense and structured local knowledge learnt by the teacher model to a target student model while maintaining training efficiency. Extensive experiments on five mainstream benchmarks with various teacher-student network pairs demonstrate the effectiveness of our approach. For instance, the DeepLabV3-Res18|DeepLabV3-MBV2 model trained by Af-DCD reaches 77.03%|76.38% mIOU on Cityscapes dataset when choosing DeepLabV3-Res101 as the teacher, setting new performance records. Besides that, Af-DCD achieves an absolute mIOU improvement of 3.26%|3.04%|2.75%|2.30%|1.42% compared with individually trained counterpart on Cityscapes|Pascal VOC|Camvid|ADE20K|COCO-Stuff-164K. Code is available at https://github.com/OSVAI/Af-DCD
KernelWarehouse: Towards Parameter-Efficient Dynamic Convolution
Aug 16, 2023Dynamic convolution learns a linear mixture of $n$ static kernels weighted with their sample-dependent attentions, demonstrating superior performance compared to normal convolution. However, existing designs are parameter-inefficient: they increase the number of convolutional parameters by $n$ times. This and the optimization difficulty lead to no research progress in dynamic convolution that can allow us to use a significant large value of $n$ (e.g., $n>100$ instead of typical setting $n<10$) to push forward the performance boundary. In this paper, we propose $KernelWarehouse$, a more general form of dynamic convolution, which can strike a favorable trade-off between parameter efficiency and representation power. Its key idea is to redefine the basic concepts of "$kernels$" and "$assembling$ $kernels$" in dynamic convolution from the perspective of reducing kernel dimension and increasing kernel number significantly. In principle, KernelWarehouse enhances convolutional parameter dependencies within the same layer and across successive layers via tactful kernel partition and warehouse sharing, yielding a high degree of freedom to fit a desired parameter budget. We validate our method on ImageNet and MS-COCO datasets with different ConvNet architectures, and show that it attains state-of-the-art results. For instance, the ResNet18|ResNet50|MobileNetV2|ConvNeXt-Tiny model trained with KernelWarehouse on ImageNet reaches 76.05%|81.05%|75.52%|82.51% top-1 accuracy. Thanks to its flexible design, KernelWarehouse can even reduce the model size of a ConvNet while improving the accuracy, e.g., our ResNet18 model with 36.45%|65.10% parameter reduction to the baseline shows 2.89%|2.29% absolute improvement to top-1 accuracy.
Ske2Grid: Skeleton-to-Grid Representation Learning for Action Recognition
Aug 15, 2023



This paper presents Ske2Grid, a new representation learning framework for improved skeleton-based action recognition. In Ske2Grid, we define a regular convolution operation upon a novel grid representation of human skeleton, which is a compact image-like grid patch constructed and learned through three novel designs. Specifically, we propose a graph-node index transform (GIT) to construct a regular grid patch through assigning the nodes in the skeleton graph one by one to the desired grid cells. To ensure that GIT is a bijection and enrich the expressiveness of the grid representation, an up-sampling transform (UPT) is learned to interpolate the skeleton graph nodes for filling the grid patch to the full. To resolve the problem when the one-step UPT is aggressive and further exploit the representation capability of the grid patch with increasing spatial size, a progressive learning strategy (PLS) is proposed which decouples the UPT into multiple steps and aligns them to multiple paired GITs through a compact cascaded design learned progressively. We construct networks upon prevailing graph convolution networks and conduct experiments on six mainstream skeleton-based action recognition datasets. Experiments show that our Ske2Grid significantly outperforms existing GCN-based solutions under different benchmark settings, without bells and whistles. Code and models are available at https://github.com/OSVAI/Ske2Grid
NORM: Knowledge Distillation via N-to-One Representation Matching
May 23, 2023Existing feature distillation methods commonly adopt the One-to-one Representation Matching between any pre-selected teacher-student layer pair. In this paper, we present N-to-One Representation (NORM), a new two-stage knowledge distillation method, which relies on a simple Feature Transform (FT) module consisting of two linear layers. In view of preserving the intact information learnt by the teacher network, during training, our FT module is merely inserted after the last convolutional layer of the student network. The first linear layer projects the student representation to a feature space having N times feature channels than the teacher representation from the last convolutional layer, and the second linear layer contracts the expanded output back to the original feature space. By sequentially splitting the expanded student representation into N non-overlapping feature segments having the same number of feature channels as the teacher's, they can be readily forced to approximate the intact teacher representation simultaneously, formulating a novel many-to-one representation matching mechanism conditioned on a single teacher-student layer pair. After training, such an FT module will be naturally merged into the subsequent fully connected layer thanks to its linear property, introducing no extra parameters or architectural modifications to the student network at inference. Extensive experiments on different visual recognition benchmarks demonstrate the leading performance of our method. For instance, the ResNet18|MobileNet|ResNet50-1/4 model trained by NORM reaches 72.14%|74.26%|68.03% top-1 accuracy on the ImageNet dataset when using a pre-trained ResNet34|ResNet50|ResNet50 model as the teacher, achieving an absolute improvement of 2.01%|4.63%|3.03% against the individually trained counterpart. Code is available at https://github.com/OSVAI/NORM
Compacting Binary Neural Networks by Sparse Kernel Selection
Mar 25, 2023Binary Neural Network (BNN) represents convolution weights with 1-bit values, which enhances the efficiency of storage and computation. This paper is motivated by a previously revealed phenomenon that the binary kernels in successful BNNs are nearly power-law distributed: their values are mostly clustered into a small number of codewords. This phenomenon encourages us to compact typical BNNs and obtain further close performance through learning non-repetitive kernels within a binary kernel subspace. Specifically, we regard the binarization process as kernel grouping in terms of a binary codebook, and our task lies in learning to select a smaller subset of codewords from the full codebook. We then leverage the Gumbel-Sinkhorn technique to approximate the codeword selection process, and develop the Permutation Straight-Through Estimator (PSTE) that is able to not only optimize the selection process end-to-end but also maintain the non-repetitive occupancy of selected codewords. Experiments verify that our method reduces both the model size and bit-wise computational costs, and achieves accuracy improvements compared with state-of-the-art BNNs under comparable budgets.
3D Human Pose Lifting with Grid Convolution
Feb 17, 2023Existing lifting networks for regressing 3D human poses from 2D single-view poses are typically constructed with linear layers based on graph-structured representation learning. In sharp contrast to them, this paper presents Grid Convolution (GridConv), mimicking the wisdom of regular convolution operations in image space. GridConv is based on a novel Semantic Grid Transformation (SGT) which leverages a binary assignment matrix to map the irregular graph-structured human pose onto a regular weave-like grid pose representation joint by joint, enabling layer-wise feature learning with GridConv operations. We provide two ways to implement SGT, including handcrafted and learnable designs. Surprisingly, both designs turn out to achieve promising results and the learnable one is better, demonstrating the great potential of this new lifting representation learning formulation. To improve the ability of GridConv to encode contextual cues, we introduce an attention module over the convolutional kernel, making grid convolution operations input-dependent, spatial-aware and grid-specific. We show that our fully convolutional grid lifting network outperforms state-of-the-art methods with noticeable margins under (1) conventional evaluation on Human3.6M and (2) cross-evaluation on MPI-INF-3DHP. Code is available at https://github.com/OSVAI/GridConv