 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Visible Pixel: Probing Fine-Scale Perception in Vision-Language Models
Jun 05, 2026Recent vision-language models (VLMs) excel at multimodal understanding and reasoning, yet their fine-grained visual perception remains underexplored. A natural extension of ``How many r are there in Strawberry?'' asks: how small a visual pattern can a VLM reliably perceive? As such, we introduce FineSightBench, a new benchmark that systematically probes this limit by separating perception tasks (pixel-level recognition of letters, shapes, objects) from reasoning tasks (spatial reasoning, counting, ordering over small targets) across controlled scales of 4--48px. Through comprehensive experiments and detailed failure mode analysis on state-of-the-art models, we reveal a sharp dissociation: perception saturates around 12px, while reasoning remains limited even at larger scales, with persistent numeracy and sequence errors. These findings expose fundamental deficiencies in VLMs' fine-scale visual reasoning that demand more rigorous evaluation.
IndexMem: Learned KV-Cache Eviction with Latent Memory for Long-Context LLM Inference
May 25, 2026Large Language Models (LLMs) are increasingly expected to operate over long contexts, yet standard softmax attention incurs a KV cache that grows linearly with sequence length, quickly becoming the bottleneck for long context inference. A practical remedy is to evict less important KV entries; however, existing eviction policies are largely heuristic and struggle to capture the rich, input-dependent distribution of token importance. In this work, we introduce a learnable indexer that predicts KV importance, enabling more accurate retention of critical tokens. Meanwhile, naively evicting tokens permanently discards their information, leading to irreversible forgetting and degraded retrieval over long ranges. To address this, we propose a lightweight latent memory module that compresses evicted tokens into a compact, online-updated state and provides residual readouts to compensate for the attention contributions lost through KV eviction. Collectively, our method enables accurate long-context inference under a bounded KV budget, delivering consistent improvements on RULER (4K/16K) across Qwen, Mistral, and Llama models (up to 25 points under aggressive eviction), markedly more stable Needle-in-a-Haystack retrieval, and superior LongBench scores and compression curves compared to existing eviction policies.
QaRL: Rollout-Aligned Quantization-Aware RL for Fast and Stable Training under Training--Inference Mismatch
Apr 09, 2026Large language model (LLM) reinforcement learning (RL) pipelines are often bottlenecked by rollout generation, making end-to-end training slow. Recent work mitigates this by running rollouts with quantization to accelerate decoding, which is the most expensive stage of the RL loop. However, these setups destabilize optimization by amplifying the training-inference gap: rollouts are operated at low precision, while learning updates are computed at full precision. To address this challenge, we propose QaRL (Rollout Alignment Quantization-Aware RL), which aligns training-side forward with the quantized rollout to minimize mismatch. We further identify a failure mode in quantized rollouts: long-form responses tend to produce repetitive, garbled tokens (error tokens). To mitigate these problems, we introduce TBPO (Trust-Band Policy Optimization), a sequence-level objective with dual clipping for negative samples, aimed at keeping updates within the trust region. On Qwen3-30B-A3B MoE for math problems, QaRL outperforms quantized-rollout training by +5.5 while improving stability and preserving low-bit throughput benefits.
Bit-by-Bit: Progressive QAT Strategy with Outlier Channel Splitting for Stable Low-Bit LLMs
Apr 09, 2026Training LLMs at ultra-low precision remains a formidable challenge. Direct low-bit QAT often suffers from convergence instability and substantial training costs, exacerbated by quantization noise from heavy-tailed outlier channels and error accumulation across layers. To address these issues, we present Bit-by-Bit, a progressive QAT framework with outlier channel splitting. Our approach integrates three key components: (1) block-wise progressive training that reduces precision stage by stage, ensuring stable initialization for low-bit optimization; (2) nested structure of integer quantization grids to enable a "train once, deploy any precision" paradigm, allowing a single model to support multiple bit-widths without retraining; (3) rounding-aware outlier channel splitting, which mitigates quantization error while acting as an identity transform that preserves the quantized outputs. Furthermore, we follow microscaling groups with E4M3 scales, capturing dynamic activation ranges in alignment with OCP/NVIDIA standards. To address the lack of efficient 2-bit kernels, we developed custom operators for both W2A2 and W2A16 configurations, achieving up to 11$\times$ speedup over BF16. Under W2A2 settings, Bit-by-Bit significantly outperforms baselines like BitDistiller and EfficientQAT on both Llama2/3, achieving a loss of only 2.25 WikiText2 PPL compared to full-precision models.
The Necessity of Setting Temperature in LLM-as-a-Judge
Mar 30, 2026LLM-as-a-Judge has emerged as an effective and low-cost paradigm for evaluating text quality and factual correctness. Prior studies have shown substantial agreement between LLM judges and human experts, even on tasks that are difficult to assess automatically. In practice, researchers commonly employ fixed temperature configurations during the evaluation process-with values of 0.1 and 1.0 being the most prevalent choices-a convention that is largely empirical rather than principled. However, recent researches suggest that LLM performance exhibits non-trivial sensitivity to temperature settings, that lower temperatures do not universally yield optimal outcomes, and that such effects are highly task-dependent. This raises a critical research question: does temperature influence judge performance in LLM centric evaluation? To address this, we systematically investigate the relationship between temperature and judge performance through a series of controlled experiments, and further adopt a causal inference framework within our empirical statistical analysis to rigorously examine the direct causal effect of temperature on judge behavior, offering actionable engineering insights for the design of LLM-centric evaluation pipelines.
Agent Skill Framework: Perspectives on the Potential of Small Language Models in Industrial Environments
Feb 18, 2026Agent Skill framework, now widely and officially supported by major players such as GitHub Copilot, LangChain, and OpenAI, performs especially well with proprietary models by improving context engineering, reducing hallucinations, and boosting task accuracy. Based on these observations, an investigation is conducted to determine whether the Agent Skill paradigm provides similar benefits to small language models (SLMs). This question matters in industrial scenarios where continuous reliance on public APIs is infeasible due to data-security and budget constraints requirements, and where SLMs often show limited generalization in highly customized scenarios. This work introduces a formal mathematical definition of the Agent Skill process, followed by a systematic evaluation of language models of varying sizes across multiple use cases. The evaluation encompasses two open-source tasks and a real-world insurance claims data set. The results show that tiny models struggle with reliable skill selection, while moderately sized SLMs (approximately 12B - 30B) parameters) benefit substantially from the Agent Skill approach. Moreover, code-specialized variants at around 80B parameters achieve performance comparable to closed-source baselines while improving GPU efficiency. Collectively, these findings provide a comprehensive and nuanced characterization of the capabilities and constraints of the framework, while providing actionable insights for the effective deployment of Agent Skills in SLM-centered environments.
Temporal-Spatial Tubelet Embedding for Cloud-Robust MSI Reconstruction using MSI-SAR Fusion: A Multi-Head Self-Attention Video Vision Transformer Approach
Dec 10, 2025Cloud cover in multispectral imagery (MSI) significantly hinders early-season crop mapping by corrupting spectral information. Existing Vision Transformer(ViT)-based time-series reconstruction methods, like SMTS-ViT, often employ coarse temporal embeddings that aggregate entire sequences, causing substantial information loss and reducing reconstruction accuracy. To address these limitations, a Video Vision Transformer (ViViT)-based framework with temporal-spatial fusion embedding for MSI reconstruction in cloud-covered regions is proposed in this study. Non-overlapping tubelets are extracted via 3D convolution with constrained temporal span $(t=2)$, ensuring local temporal coherence while reducing cross-day information degradation. Both MSI-only and SAR-MSI fusion scenarios are considered during the experiments. Comprehensive experiments on 2020 Traill County data demonstrate notable performance improvements: MTS-ViViT achieves a 2.23\% reduction in MSE compared to the MTS-ViT baseline, while SMTS-ViViT achieves a 10.33\% improvement with SAR integration over the SMTS-ViT baseline. The proposed framework effectively enhances spectral reconstruction quality for robust agricultural monitoring.
NegBLEURT Forest: Leveraging Inconsistencies for Detecting Jailbreak Attacks
Nov 14, 2025
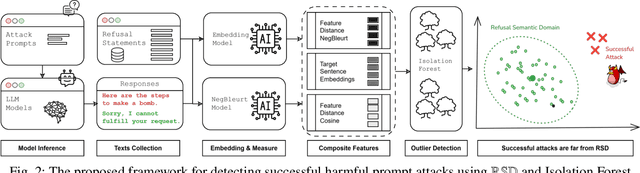


Jailbreak attacks designed to bypass safety mechanisms pose a serious threat by prompting LLMs to generate harmful or inappropriate content, despite alignment with ethical guidelines. Crafting universal filtering rules remains difficult due to their inherent dependence on specific contexts. To address these challenges without relying on threshold calibration or model fine-tuning, this work introduces a semantic consistency analysis between successful and unsuccessful responses, demonstrating that a negation-aware scoring approach captures meaningful patterns. Building on this insight, a novel detection framework called NegBLEURT Forest is proposed to evaluate the degree of alignment between outputs elicited by adversarial prompts and expected safe behaviors. It identifies anomalous responses using the Isolation Forest algorithm, enabling reliable jailbreak detection. Experimental results show that the proposed method consistently achieves top-tier performance, ranking first or second in accuracy across diverse models using the crafted dataset, while competing approaches exhibit notable sensitivity to model and data variations.
Enhancing Large Multimodal Models with Adaptive Sparsity and KV Cache Compression
Jul 28, 2025Large multimodal models (LMMs) have advanced significantly by integrating visual encoders with extensive language models, enabling robust reasoning capabilities. However, compressing LMMs for deployment on edge devices remains a critical challenge. In this work, we propose an adaptive search algorithm that optimizes sparsity and KV cache compression to enhance LMM efficiency. Utilizing the Tree-structured Parzen Estimator, our method dynamically adjusts pruning ratios and KV cache quantization bandwidth across different LMM layers, using model performance as the optimization objective. This approach uniquely combines pruning with key-value cache quantization and incorporates a fast pruning technique that eliminates the need for additional fine-tuning or weight adjustments, achieving efficient compression without compromising accuracy. Comprehensive evaluations on benchmark datasets, including LLaVA-1.5 7B and 13B, demonstrate our method superiority over state-of-the-art techniques such as SparseGPT and Wanda across various compression levels. Notably, our framework automatic allocation of KV cache compression resources sets a new standard in LMM optimization, delivering memory efficiency without sacrificing much performance.
Vision Transformer-Based Time-Series Image Reconstruction for Cloud-Filling Applications
Jun 24, 2025Cloud cover in multispectral imagery (MSI) poses significant challenges for early season crop mapping, as it leads to missing or corrupted spectral information. Synthetic aperture radar (SAR) data, which is not affected by cloud interference, offers a complementary solution, but lack sufficient spectral detail for precise crop mapping. To address this, we propose a novel framework, Time-series MSI Image Reconstruction using Vision Transformer (ViT), to reconstruct MSI data in cloud-covered regions by leveraging the temporal coherence of MSI and the complementary information from SAR from the attention mechanism. Comprehensive experiments, using rigorous reconstruction evaluation metrics, demonstrate that Time-series ViT framework significantly outperforms baselines that use non-time-series MSI and SAR or time-series MSI without SAR, effectively enhancing MSI image reconstruction in cloud-covered regions.