 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Outlier Dynamics in LLM NVFP4 Pretraining
Feb 02, 2026Training large language models using 4-bit arithmetic enhances throughput and memory efficiency. Yet, the limited dynamic range of FP4 increases sensitivity to outliers. While NVFP4 mitigates quantization error via hierarchical microscaling, a persistent loss gap remains compared to BF16. This study conducts a longitudinal analysis of outlier dynamics across architecture during NVFP4 pretraining, focusing on where they localize, why they occur, and how they evolve temporally. We find that, compared with Softmax Attention (SA), Linear Attention (LA) reduces per-tensor heavy tails but still exhibits persistent block-level spikes under block quantization. Our analysis attributes outliers to specific architectural components: Softmax in SA, gating in LA, and SwiGLU in FFN, with "post-QK" operations exhibiting higher sensitivity to quantization. Notably, outliers evolve from transient spikes early in training to a small set of persistent hot channels (i.e., channels with persistently large magnitudes) in later stages. Based on these findings, we introduce Hot-Channel Patch (HCP), an online compensation mechanism that identifies hot channels and reinjects residuals using hardware-efficient kernels. We then develop CHON, an NVFP4 training recipe integrating HCP with post-QK operation protection. On GLA-1.3B model trained for 60B tokens, CHON reduces the loss gap to BF16 from 0.94% to 0.58% while maintaining downstream accuracy.
Can Compressed LLMs Truly Act? An Empirical Evaluation of Agentic Capabilities in LLM Compression
May 26, 2025


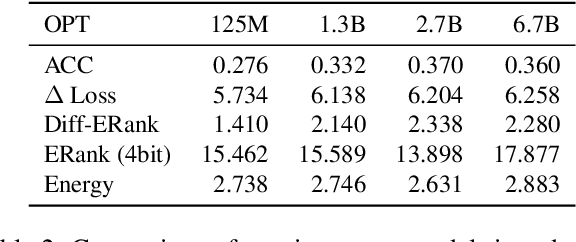
Post-training compression reduces the computational and memory costs of large language models (LLMs), enabling resource-efficient deployment. However, existing compression benchmarks only focus on language modeling (e.g., perplexity) and natural language understanding tasks (e.g., GLUE accuracy), ignoring the agentic capabilities - workflow, tool use/function call, long-context understanding and real-world application. We introduce the Agent Compression Benchmark (ACBench), the first comprehensive benchmark for evaluating how compression impacts LLMs' agentic abilities. ACBench spans (1) 12 tasks across 4 capabilities (e.g., WorfBench for workflow generation, Needle-in-Haystack for long-context retrieval), (2) quantization (GPTQ, AWQ) and pruning (Wanda, SparseGPT), and (3) 15 models, including small (Gemma-2B), standard (Qwen2.5 7B-32B), and distilled reasoning LLMs (DeepSeek-R1-Distill). Our experiments reveal compression tradeoffs: 4-bit quantization preserves workflow generation and tool use (1%-3% drop) but degrades real-world application accuracy by 10%-15%. We introduce ERank, Top-k Ranking Correlation and Energy to systematize analysis. ACBench provides actionable insights for optimizing LLM compression in agentic scenarios. The code can be found in https://github.com/pprp/ACBench.
The Lottery LLM Hypothesis, Rethinking What Abilities Should LLM Compression Preserve?
Feb 24, 2025Motivated by reducing the computational and storage costs of LLMs, model compression and KV cache compression have attracted much attention from researchers. However, current methods predominantly emphasize maintaining the performance of compressed LLMs, as measured by perplexity or simple accuracy on tasks of common sense knowledge QA and basic arithmetic reasoning. In this blog, we present a brief review of recent advancements in LLMs related to retrieval-augmented generation, multi-step reasoning, external tools, and computational expressivity, all of which substantially enhance LLM performance. Then, we propose a lottery LLM hypothesis suggesting that for a given LLM and task, there exists a smaller lottery LLM capable of producing the same performance as the original LLM with the assistance of multi-step reasoning and external tools. Based on the review of current progress in LLMs, we discuss and summarize the essential capabilities that the lottery LLM and KV cache compression must possess, which are currently overlooked in existing methods.
Perovskite-LLM: Knowledge-Enhanced Large Language Models for Perovskite Solar Cell Research
Feb 18, 2025The rapid advancement of perovskite solar cells (PSCs) has led to an exponential growth in research publications, creating an urgent need for efficient knowledge management and reasoning systems in this domain. We present a comprehensive knowledge-enhanced system for PSCs that integrates three key components. First, we develop Perovskite-KG, a domain-specific knowledge graph constructed from 1,517 research papers, containing 23,789 entities and 22,272 relationships. Second, we create two complementary datasets: Perovskite-Chat, comprising 55,101 high-quality question-answer pairs generated through a novel multi-agent framework, and Perovskite-Reasoning, containing 2,217 carefully curated materials science problems. Third, we introduce two specialized large language models: Perovskite-Chat-LLM for domain-specific knowledge assistance and Perovskite-Reasoning-LLM for scientific reasoning tasks. Experimental results demonstrate that our system significantly outperforms existing models in both domain-specific knowledge retrieval and scientific reasoning tasks, providing researchers with effective tools for literature review, experimental design, and complex problem-solving in PSC research.
Mediator: Memory-efficient LLM Merging with Less Parameter Conflicts and Uncertainty Based Routing
Feb 06, 2025Model merging aggregates Large Language Models (LLMs) finetuned on different tasks into a stronger one. However, parameter conflicts between models leads to performance degradation in averaging. While model routing addresses this issue by selecting individual models during inference, it imposes excessive storage and compute costs, and fails to leverage the common knowledge from different models. In this work, we observe that different layers exhibit varying levels of parameter conflicts. Building on this insight, we average layers with minimal parameter conflicts and use a novel task-level expert routing for layers with significant conflicts. To further reduce storage costs, inspired by task arithmetic sparsity, we decouple multiple fine-tuned experts into a dense expert and several sparse experts. Considering the out-of-distribution samples, we select and merge appropriate experts based on the task uncertainty of the input data. We conduct extensive experiments on both LLaMA and Qwen with varying parameter scales, and evaluate on real-world reasoning tasks. Results demonstrate that our method consistently achieves significant performance improvements while requiring less system cost compared to existing methods.
Can LLMs Maintain Fundamental Abilities under KV Cache Compression?
Feb 04, 2025



This paper investigates an under-explored challenge in large language models (LLMs): the impact of KV cache compression methods on LLMs' fundamental capabilities. While existing methods achieve impressive compression ratios on long-context benchmarks, their effects on core model capabilities remain understudied. We present a comprehensive empirical study evaluating prominent KV cache compression methods across diverse tasks, spanning world knowledge, commonsense reasoning, arithmetic reasoning, code generation, safety, and long-context understanding and generation.Our analysis reveals that KV cache compression methods exhibit task-specific performance degradation. Arithmetic reasoning tasks prove particularly sensitive to aggressive compression, with different methods showing performance drops of $17.4\%$-$43.3\%$. Notably, the DeepSeek R1 Distill model exhibits more robust compression tolerance compared to instruction-tuned models, showing only $9.67\%$-$25.53\%$ performance degradation. Based on our analysis of attention patterns and cross-task compression performance, we propose ShotKV, a novel compression approach that distinctly handles prefill and decoding phases while maintaining shot-level semantic coherence. Empirical results show that ShotKV achieves $9\%$-$18\%$ performance improvements on long-context generation tasks under aggressive compression ratios.
FuseFL: One-Shot Federated Learning through the Lens of Causality with Progressive Model Fusion
Oct 27, 2024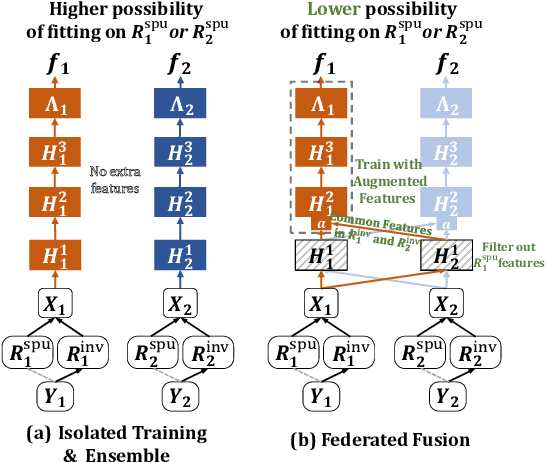
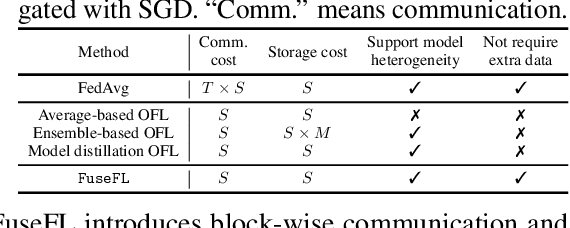
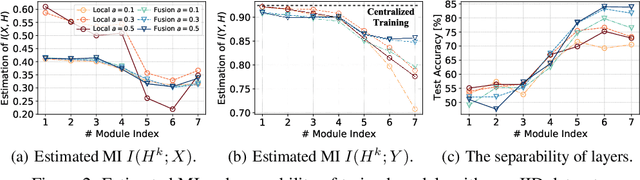
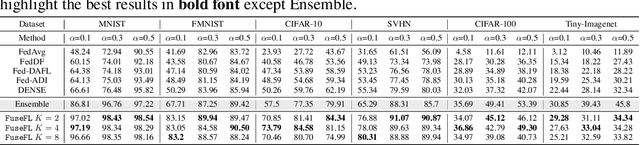
One-shot Federated Learning (OFL) significantly reduces communication costs in FL by aggregating trained models only once. However, the performance of advanced OFL methods is far behind the normal FL. In this work, we provide a causal view to find that this performance drop of OFL methods comes from the isolation problem, which means that local isolatedly trained models in OFL may easily fit to spurious correlations due to the data heterogeneity. From the causal perspective, we observe that the spurious fitting can be alleviated by augmenting intermediate features from other clients. Built upon our observation, we propose a novel learning approach to endow OFL with superb performance and low communication and storage costs, termed as FuseFL. Specifically, FuseFL decomposes neural networks into several blocks, and progressively trains and fuses each block following a bottom-up manner for feature augmentation, introducing no additional communication costs. Comprehensive experiments demonstrate that FuseFL outperforms existing OFL and ensemble FL by a significant margin. We conduct comprehensive experiments to show that FuseFL supports high scalability of clients, heterogeneous model training, and low memory costs. Our work is the first attempt using causality to analyze and alleviate data heterogeneity of OFL.
Should We Really Edit Language Models? On the Evaluation of Edited Language Models
Oct 24, 2024


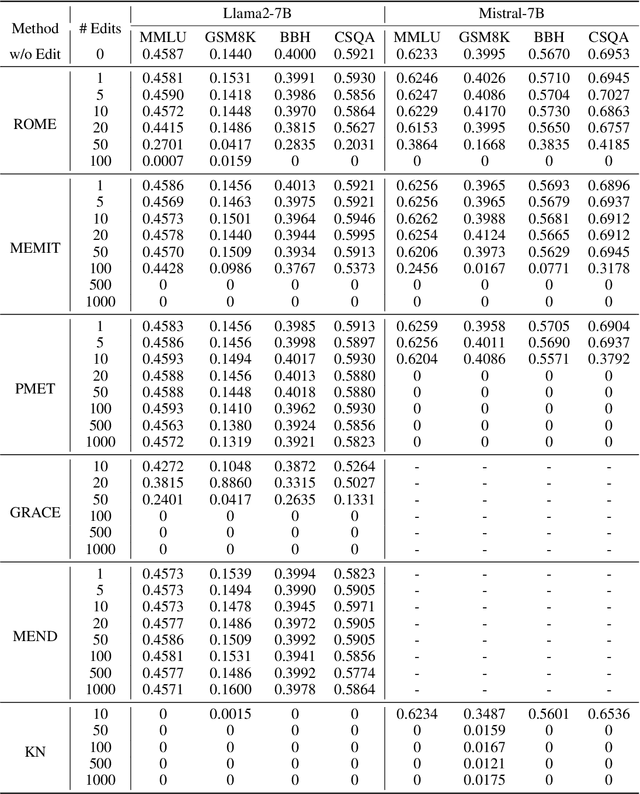
Model editing has become an increasingly popular alternative for efficiently updating knowledge within language models. Current methods mainly focus on reliability, generalization, and locality, with many methods excelling across these criteria. Some recent works disclose the pitfalls of these editing methods such as knowledge distortion or conflict. However, the general abilities of post-edited language models remain unexplored. In this paper, we perform a comprehensive evaluation on various editing methods and different language models, and have following findings. (1) Existing editing methods lead to inevitable performance deterioration on general benchmarks, indicating that existing editing methods maintain the general abilities of the model within only a few dozen edits. When the number of edits is slightly large, the intrinsic knowledge structure of the model is disrupted or even completely damaged. (2) Instruction-tuned models are more robust to editing, showing less performance drop on general knowledge after editing. (3) Language model with large scale is more resistant to editing compared to small model. (4) The safety of the edited model, is significantly weakened, even for those safety-aligned models. Our findings indicate that current editing methods are only suitable for small-scale knowledge updates within language models, which motivates further research on more practical and reliable editing methods. The details of code and reproduction can be found in https://github.com/lqinfdim/EditingEvaluation.
LPZero: Language Model Zero-cost Proxy Search from Zero
Oct 07, 2024
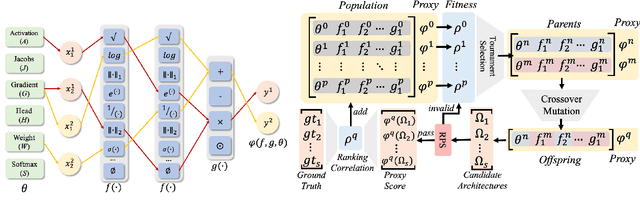
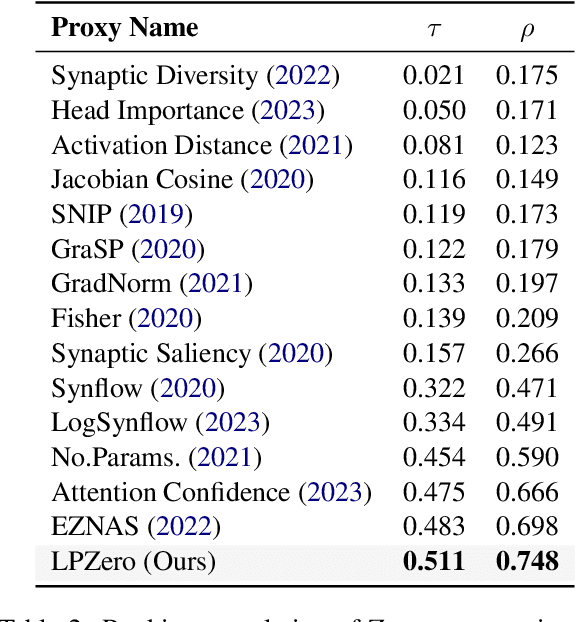
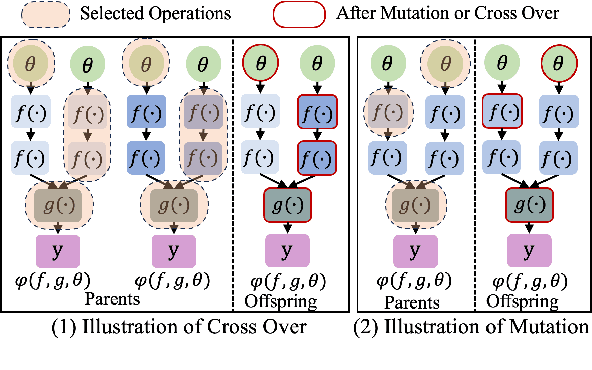
In spite of the outstanding performance, Neural Architecture Search (NAS) is criticized for massive computation. Recently, Zero-shot NAS has emerged as a promising approach by exploiting Zero-cost (ZC) proxies, which markedly reduce computational demands. Despite this, existing ZC proxies heavily rely on expert knowledge and incur significant trial-and-error costs. Particularly in NLP tasks, most existing ZC proxies fail to surpass the performance of the naive baseline. To address these challenges, we introduce a novel framework, \textbf{LPZero}, which is the first to automatically design ZC proxies for various tasks, achieving higher ranking consistency than human-designed proxies. Specifically, we model the ZC proxy as a symbolic equation and incorporate a unified proxy search space that encompasses existing ZC proxies, which are composed of a predefined set of mathematical symbols. To heuristically search for the best ZC proxy, LPZero incorporates genetic programming to find the optimal symbolic composition. We propose a \textit{Rule-based Pruning Strategy (RPS),} which preemptively eliminates unpromising proxies, thereby mitigating the risk of proxy degradation. Extensive experiments on FlexiBERT, GPT-2, and LLaMA-7B demonstrate LPZero's superior ranking ability and performance on downstream tasks compared to current approaches.
LongGenBench: Long-context Generation Benchmark
Oct 05, 2024Current long-context benchmarks primarily focus on retrieval-based tests, requiring Large Language Models (LLMs) to locate specific information within extensive input contexts, such as the needle-in-a-haystack (NIAH) benchmark. Long-context generation refers to the ability of a language model to generate coherent and contextually accurate text that spans across lengthy passages or documents. While recent studies show strong performance on NIAH and other retrieval-based long-context benchmarks, there is a significant lack of benchmarks for evaluating long-context generation capabilities. To bridge this gap and offer a comprehensive assessment, we introduce a synthetic benchmark, LongGenBench, which allows for flexible configurations of customized generation context lengths. LongGenBench advances beyond traditional benchmarks by redesigning the format of questions and necessitating that LLMs respond with a single, cohesive long-context answer. Upon extensive evaluation using LongGenBench, we observe that: (1) both API accessed and open source models exhibit performance degradation in long-context generation scenarios, ranging from 1.2% to 47.1%; (2) different series of LLMs exhibit varying trends of performance degradation, with the Gemini-1.5-Flash model showing the least degradation among API accessed models, and the Qwen2 series exhibiting the least degradation in LongGenBench among open source models.