 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaterVideoQA: ASV-Centric Perception and Rule-Compliant Reasoning via Multi-Modal Agents
Feb 26, 2026While autonomous navigation has achieved remarkable success in passive perception (e.g., object detection and segmentation), it remains fundamentally constrained by a void in knowledge-driven, interactive environmental cognition. In the high-stakes domain of maritime navigation, the ability to bridge the gap between raw visual perception and complex cognitive reasoning is not merely an enhancement but a critical prerequisite for Autonomous Surface Vessels to execute safe and precise maneuvers. To this end, we present WaterVideoQA, the first large-scale, comprehensive Video Question Answering benchmark specifically engineered for all-waterway environments. This benchmark encompasses 3,029 video clips across six distinct waterway categories, integrating multifaceted variables such as volatile lighting and dynamic weather to rigorously stress-test ASV capabilities across a five-tier hierarchical cognitive framework. Furthermore, we introduce NaviMind, a pioneering multi-agent neuro-symbolic system designed for open-ended maritime reasoning. By synergizing Adaptive Semantic Routing, Situation-Aware Hierarchical Reasoning, and Autonomous Self-Reflective Verification, NaviMind transitions ASVs from superficial pattern matching to regulation-compliant, interpretable decision-making. Experimental results demonstrate that our framework significantly transcends existing baselines, establishing a new paradigm for intelligent, trustworthy interaction in dynamic maritime environments.
Janus-Q: End-to-End Event-Driven Trading via Hierarchical-Gated Reward Modeling
Feb 23, 2026Financial market movements are often driven by discrete financial events conveyed through news, whose impacts are heterogeneous, abrupt, and difficult to capture under purely numerical prediction objectives. These limitations have motivated growing interest in using textual information as the primary source of trading signals in learning-based systems. Two key challenges hinder existing approaches: (1) the absence of large-scale, event-centric datasets that jointly model news semantics and statistically grounded market reactions, and (2) the misalignment between language model reasoning and financially valid trading behavior under dynamic market conditions. To address these challenges, we propose Janus-Q, an end-to-end event-driven trading framework that elevates financial news events from auxiliary signals to primary decision units. Janus-Q unifies event-centric data construction and model optimization under a two-stage paradigm. Stage I focuses on event-centric data construction, building a large-scale financial news event dataset comprising 62,400 articles annotated with 10 fine-grained event types, associated stocks, sentiment labels, and event-driven cumulative abnormal return (CAR). Stage II performs decision-oriented fine-tuning, combining supervised learning with reinforcement learning guided by a Hierarchical Gated Reward Model (HGRM), which explicitly captures trade-offs among multiple trading objectives. Extensive experiments demonstrate that Janus-Q achieves more consistent, interpretable, and profitable trading decisions than market indices and LLM baselines, improving the Sharpe Ratio by up to 102.0% while increasing direction accuracy by over 17.5% compared to the strongest competing strategies.
OmniReview: A Large-scale Benchmark and LLM-enhanced Framework for Realistic Reviewer Recommendation
Feb 09, 2026Academic peer review remains the cornerstone of scholarly validation, yet the field faces some challenges in data and methods. From the data perspective, existing research is hindered by the scarcity of large-scale, verified benchmarks and oversimplified evaluation metrics that fail to reflect real-world editorial workflows. To bridge this gap, we present OmniReview, a comprehensive dataset constructed by integrating multi-source academic platforms encompassing comprehensive scholarly profiles through the disambiguation pipeline, yielding 202, 756 verified review records. Based on this data, we introduce a three-tier hierarchical evaluaion framework to assess recommendations from recall to precise expert identification. From the method perspective, existing embedding-based approaches suffer from the information bottleneck of semantic compression and limited interpretability. To resolve these method limitations, we propose Profiling Scholars with Multi-gate Mixture-of-Experts (Pro-MMoE), a novel framework that synergizes Large Language Models (LLMs) with Multi-task Learning. Specifically, it utilizes LLM-generated semantic profiles to preserve fine-grained expertise nuances and interpretability, while employing a Task-Adaptive MMoE architecture to dynamically balance conflicting evaluation goals. Comprehensive experiments demonstrate that Pro-MMoE achieves state-of-the-art performance across six of seven metrics, establishing a new benchmark for realistic reviewer recommendation.
MRD-RAG: Enhancing Medical Diagnosis with Multi-Round Retrieval-Augmented Generation
Apr 10, 2025In recent years, accurately and quickly deploying medical large language models (LLMs) has become a significant trend. Among these, retrieval-augmented generation (RAG) has garnered significant attention due to its features of rapid deployment and privacy protection. However, existing medical RAG frameworks still have shortcomings. Most existing medical RAG frameworks are designed for single-round question answering tasks and are not suitable for multi-round diagnostic dialogue. On the other hand, existing medical multi-round RAG frameworks do not consider the interconnections between potential diseases to inquire precisely like a doctor. To address these issues, we propose a Multi-Round Diagnostic RAG (MRD-RAG) framework that mimics the doctor's diagnostic process. This RAG framework can analyze diagnosis information of potential diseases and accurately conduct multi-round diagnosis like a doctor. To evaluate the effectiveness of our proposed frameworks, we conduct experiments on two modern medical datasets and two traditional Chinese medicine datasets, with evaluations by GPT and human doctors on different methods. The results indicate that our RAG framework can significantly enhance the diagnostic performance of LLMs, highlighting the potential of our approach in medical diagnosis. The code and data can be found in our project website https://github.com/YixiangCh/MRD-RAG/tree/master.
Perovskite-LLM: Knowledge-Enhanced Large Language Models for Perovskite Solar Cell Research
Feb 18, 2025



The rapid advancement of perovskite solar cells (PSCs) has led to an exponential growth in research publications, creating an urgent need for efficient knowledge management and reasoning systems in this domain. We present a comprehensive knowledge-enhanced system for PSCs that integrates three key components. First, we develop Perovskite-KG, a domain-specific knowledge graph constructed from 1,517 research papers, containing 23,789 entities and 22,272 relationships. Second, we create two complementary datasets: Perovskite-Chat, comprising 55,101 high-quality question-answer pairs generated through a novel multi-agent framework, and Perovskite-Reasoning, containing 2,217 carefully curated materials science problems. Third, we introduce two specialized large language models: Perovskite-Chat-LLM for domain-specific knowledge assistance and Perovskite-Reasoning-LLM for scientific reasoning tasks. Experimental results demonstrate that our system significantly outperforms existing models in both domain-specific knowledge retrieval and scientific reasoning tasks, providing researchers with effective tools for literature review, experimental design, and complex problem-solving in PSC research.
Evaluating Semantic Variation in Text-to-Image Synthesis: A Causal Perspective
Oct 14, 2024
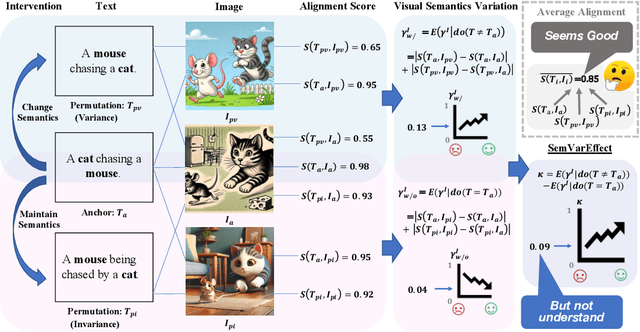
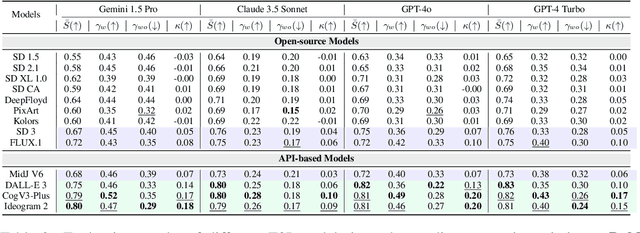
Accurate interpretation and visualization of human instructions are crucial for text-to-image (T2I) synthesis. However, current models struggle to capture semantic variations from word order changes, and existing evaluations, relying on indirect metrics like text-image similarity, fail to reliably assess these challenges. This often obscures poor performance on complex or uncommon linguistic patterns by the focus on frequent word combinations. To address these deficiencies, we propose a novel metric called SemVarEffect and a benchmark named SemVarBench, designed to evaluate the causality between semantic variations in inputs and outputs in T2I synthesis. Semantic variations are achieved through two types of linguistic permutations, while avoiding easily predictable literal variations. Experiments reveal that the CogView-3-Plus and Ideogram 2 performed the best, achieving a score of 0.2/1. Semantic variations in object relations are less understood than attributes, scoring 0.07/1 compared to 0.17-0.19/1. We found that cross-modal alignment in UNet or Transformers plays a crucial role in handling semantic variations, a factor previously overlooked by a focus on textual encoders. Our work establishes an effective evaluation framework that advances the T2I synthesis community's exploration of human instruction understanding.
3D Question Answering for City Scene Understanding
Jul 24, 20243D multimodal question answering (MQA) plays a crucial role in scene understanding by enabling intelligent agents to comprehend their surroundings in 3D environments. While existing research has primarily focused on indoor household tasks and outdoor roadside autonomous driving tasks, there has been limited exploration of city-level scene understanding tasks. Furthermore, existing research faces challenges in understanding city scenes, due to the absence of spatial semantic information and human-environment interaction information at the city level.To address these challenges, we investigate 3D MQA from both dataset and method perspectives. From the dataset perspective, we introduce a novel 3D MQA dataset named City-3DQA for city-level scene understanding, which is the first dataset to incorporate scene semantic and human-environment interactive tasks within the city. From the method perspective, we propose a Scene graph enhanced City-level Understanding method (Sg-CityU), which utilizes the scene graph to introduce the spatial semantic. A new benchmark is reported and our proposed Sg-CityU achieves accuracy of 63.94 % and 63.76 % in different settings of City-3DQA. Compared to indoor 3D MQA methods and zero-shot using advanced large language models (LLMs), Sg-CityU demonstrates state-of-the-art (SOTA) performance in robustness and generalization.
Multi-Task Domain Adaptation for Language Grounding with 3D Objects
Jul 03, 2024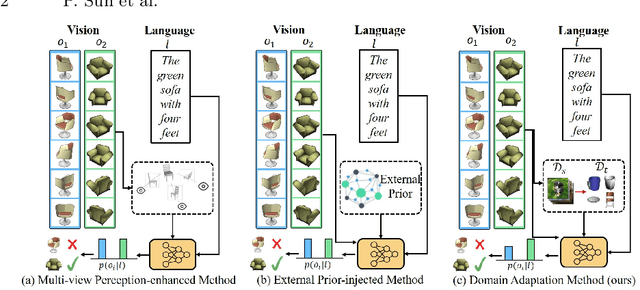
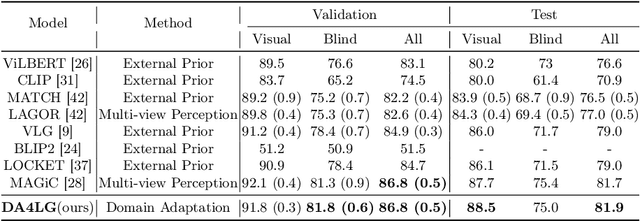
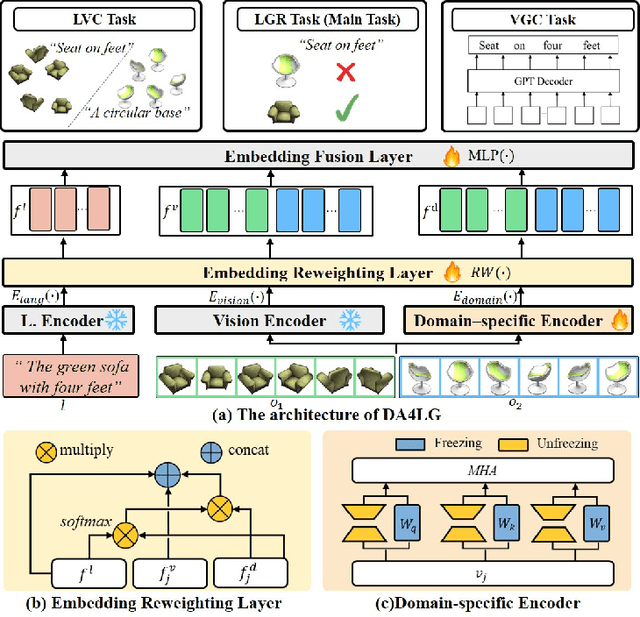
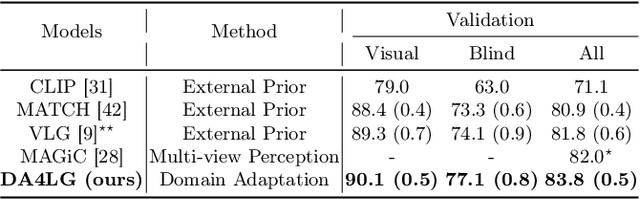
The existing works on object-level language grounding with 3D objects mostly focus on improving performance by utilizing the off-the-shelf pre-trained models to capture features, such as viewpoint selection or geometric priors. However, they have failed to consider exploring the cross-modal representation of language-vision alignment in the cross-domain field. To answer this problem, we propose a novel method called Domain Adaptation for Language Grounding (DA4LG) with 3D objects. Specifically, the proposed DA4LG consists of a visual adapter module with multi-task learning to realize vision-language alignment by comprehensive multimodal feature representation. Experimental results demonstrate that DA4LG competitively performs across visual and non-visual language descriptions, independent of the completeness of observation. DA4LG achieves state-of-the-art performance in the single-view setting and multi-view setting with the accuracy of 83.8% and 86.8% respectively in the language grounding benchmark SNARE. The simulation experiments show the well-practical and generalized performance of DA4LG compared to the existing methods. Our project is available at https://sites.google.com/view/da4lg.
A Contrastive Compositional Benchmark for Text-to-Image Synthesis: A Study with Unified Text-to-Image Fidelity Metrics
Dec 04, 2023Text-to-image (T2I) synthesis has recently achieved significant advancements. However, challenges remain in the model's compositionality, which is the ability to create new combinations from known components. We introduce Winoground-T2I, a benchmark designed to evaluate the compositionality of T2I models. This benchmark includes 11K complex, high-quality contrastive sentence pairs spanning 20 categories. These contrastive sentence pairs with subtle differences enable fine-grained evaluations of T2I synthesis models. Additionally, to address the inconsistency across different metrics, we propose a strategy that evaluates the reliability of various metrics by using comparative sentence pairs. We use Winoground-T2I with a dual objective: to evaluate the performance of T2I models and the metrics used for their evaluation. Finally, we provide insights into the strengths and weaknesses of these metrics and the capabilities of current T2I models in tackling challenges across a range of complex compositional categories. Our benchmark is publicly available at https://github.com/zhuxiangru/Winoground-T2I .
Learning 6-DoF Fine-grained Grasp Detection Based on Part Affordance Grounding
Jan 27, 2023Robotic grasping is a fundamental ability for a robot to interact with the environment. Current methods focus on how to obtain a stable and reliable grasping pose in object wise, while little work has been studied on part (shape)-wise grasping which is related to fine-grained grasping and robotic affordance. Parts can be seen as atomic elements to compose an object, which contains rich semantic knowledge and a strong correlation with affordance. However, lacking a large part-wise 3D robotic dataset limits the development of part representation learning and downstream application. In this paper, we propose a new large Language-guided SHape grAsPing datasEt (named Lang-SHAPE) to learn 3D part-wise affordance and grasping ability. We design a novel two-stage fine-grained robotic grasping network (named PIONEER), including a novel 3D part language grounding model, and a part-aware grasp pose detection model. To evaluate the effectiveness, we perform multi-level difficulty part language grounding grasping experiments and deploy our proposed model on a real robot. Results show our method achieves satisfactory performance and efficiency in reference identification, affordance inference, and 3D part-aware grasping. Our dataset and code are available on our project website https://sites.google.com/view/lang-shape