 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIL++: Multi-Modal Bi-directional Agent Layer for Vision-Language Models
May 25, 2026Adapting large vision-language models (VLMs) such as CLIP to downstream tasks remains challenging, as full fine-tuning is computationally prohibitive and prone to overfitting in low-data regimes. Parameter-efficient fine-tuning (PEFT) alleviates these issues with lightweight prompt- or adapter-based modules, and cross-modal coupling has proven especially effective by strengthening interactions between vision and language. However, existing coupling mechanisms predominantly rely on external auxiliary modules, leading to indirect, coarse-grained interactions that are structurally decoupled from the original VLM and thus limit representational expressiveness. In this paper, we propose Multi-Modal Interactive Agent Layer (MAIL), a PEFT paradigm that embeds cross-modal coupling directly into the intrinsic computation modules of VLMs. MAIL freezes the backbone and inserts lightweight agent layers after core modules, such as LayerNorm, to approximate the parameter updates induced by full fine-tuning. To couple visual and textual streams at this level, we introduce a bottleneck-based text-to-image bridge that jointly optimizes paired agent layers across modalities, coordinating the adaptation of corresponding computation modules. We further present MAIL++, which enables bidirectional cross-modal exchange through a meta agent layer, a meta-text bridge, and a meta-image bridge. At inference time, all agent layers are re-parameterized into the frozen backbone, preserving the original computational efficiency. Extensive experiments on few-shot image classification and few-shot universal cross-domain retrieval demonstrate that MAIL and MAIL++ consistently outperform state-of-the-art PEFT methods.
EpiAgent: An Agent-Centric System for Ancient Inscription Restoration
Apr 10, 2026Ancient inscriptions, as repositories of cultural memory, have suffered from centuries of environmental and human-induced degradation. Restoring their intertwined visual and textual integrity poses one of the most demanding challenges in digital heritage preservation. However, existing AI-based approaches often rely on rigid pipelines, struggling to generalize across such complex and heterogeneous real-world degradations. Inspired by the skill-coordinated workflow of human epigraphers, we propose EpiAgent, an agent-centric system that formulates inscription restoration as a hierarchical planning problem. Following an Observe-Conceive-Execute-Reevaluate paradigm, an LLM-based central planner orchestrates collaboration among multimodal analysis, historical experience, specialized restoration tools, and iterative self-refinement. This agent-centric coordination enables a flexible and adaptive restoration process beyond conventional single-pass methods. Across real-world degraded inscriptions, EpiAgent achieves superior restoration quality and stronger generalization compared to existing methods. Our work marks an important step toward expert-level agent-driven restoration of cultural heritage. The code is available at https://github.com/blackprotoss/EpiAgent.
Text-Phase Synergy Network with Dual Priors for Unsupervised Cross-Domain Image Retrieval
Mar 13, 2026This paper studies unsupervised cross-domain image retrieval (UCDIR), which aims to retrieve images of the same category across different domains without relying on labeled data. Existing methods typically utilize pseudo-labels, derived from clustering algorithms, as supervisory signals for intra-domain representation learning and cross-domain feature alignment. However, these discrete pseudo-labels often fail to provide accurate and comprehensive semantic guidance. Moreover, the alignment process frequently overlooks the entanglement between domain-specific and semantic information, leading to semantic degradation in the learned representations and ultimately impairing retrieval performance. This paper addresses the limitations by proposing a Text-Phase Synergy Network with Dual Priors(TPSNet). Specifically, we first employ CLIP to generate a set of class-specific prompts per domain, termed as domain prompt, serving as a text prior that offers more precise semantic supervision. In parallel, we further introduce a phase prior, represented by domain-invariant phase features, which is integrated into the original image representations to bridge the domain distribution gaps while preserving semantic integrity. Leveraging the synergy of these dual priors, TPSNet significantly outperforms state-of-the-art methods on UCDIR benchmarks.
SRasP: Self-Reorientation Adversarial Style Perturbation for Cross-Domain Few-Shot Learning
Mar 05, 2026Cross-Domain Few-Shot Learning (CD-FSL) aims to transfer knowledge from a seen source domain to unseen target domains, serving as a key benchmark for evaluating the robustness and transferability of models. Existing style-based perturbation methods mitigate domain shift but often suffer from gradient instability and convergence to sharp minima.To address these limitations, we propose a novel crop-global style perturbation network, termed Self-Reorientation Adversarial \underline{S}tyle \underline{P}erturbation (SRasP). Specifically, SRasP leverages global semantic guidance to identify incoherent crops, followed by reorienting and aggregating the style gradients of these crops with the global style gradients within one image. Furthermore, we propose a novel multi-objective optimization function to maximize visual discrepancy while enforcing semantic consistency among global, crop, and adversarial features. Applying the stabilized perturbations during training encourages convergence toward flatter and more transferable solutions, improving generalization to unseen domains. Extensive experiments are conducted on multiple CD-FSL benchmarks, demonstrating consistent improvements over state-of-the-art methods.
Adaptive Hyperbolic Kernels: Modulated Embedding in de Branges-Rovnyak Spaces
Nov 13, 2025Hierarchical data pervades diverse machine learning applications, including natural language processing, computer vision, and social network analysis. Hyperbolic space, characterized by its negative curvature, has demonstrated strong potential in such tasks due to its capacity to embed hierarchical structures with minimal distortion. Previous evidence indicates that the hyperbolic representation capacity can be further enhanced through kernel methods. However, existing hyperbolic kernels still suffer from mild geometric distortion or lack adaptability. This paper addresses these issues by introducing a curvature-aware de Branges-Rovnyak space, a reproducing kernel Hilbert space (RKHS) that is isometric to a Poincare ball. We design an adjustable multiplier to select the appropriate RKHS corresponding to the hyperbolic space with any curvature adaptively. Building on this foundation, we further construct a family of adaptive hyperbolic kernels, including the novel adaptive hyperbolic radial kernel, whose learnable parameters modulate hyperbolic features in a task-aware manner. Extensive experiments on visual and language benchmarks demonstrate that our proposed kernels outperform existing hyperbolic kernels in modeling hierarchical dependencies.
On Distilling the Displacement Knowledge for Few-Shot Class-Incremental Learning
Dec 17, 2024Few-shot Class-Incremental Learning (FSCIL) addresses the challenges of evolving data distributions and the difficulty of data acquisition in real-world scenarios. To counteract the catastrophic forgetting typically encountered in FSCIL, knowledge distillation is employed as a way to maintain the knowledge from learned data distribution. Recognizing the limitations of generating discriminative feature representations in a few-shot context, our approach incorporates structural information between samples into knowledge distillation. This structural information serves as a remedy for the low quality of features. Diverging from traditional structured distillation methods that compute sample similarity, we introduce the Displacement Knowledge Distillation (DKD) method. DKD utilizes displacement rather than similarity between samples, incorporating both distance and angular information to significantly enhance the information density retained through knowledge distillation. Observing performance disparities in feature distribution between base and novel classes, we propose the Dual Distillation Network (DDNet). This network applies traditional knowledge distillation to base classes and DKD to novel classes, challenging the conventional integration of novel classes with base classes. Additionally, we implement an instance-aware sample selector during inference to dynamically adjust dual branch weights, thereby leveraging the complementary strengths of each approach. Extensive testing on three benchmarks demonstrates that DDNet achieves state-of-the-art results. Moreover, through rigorous experimentation and comparison, we establish the robustness and general applicability of our proposed DKD method.
PEARL: Input-Agnostic Prompt Enhancement with Negative Feedback Regulation for Class-Incremental Learning
Dec 14, 2024Class-incremental learning (CIL) aims to continuously introduce novel categories into a classification system without forgetting previously learned ones, thus adapting to evolving data distributions. Researchers are currently focusing on leveraging the rich semantic information of pre-trained models (PTMs) in CIL tasks. Prompt learning has been adopted in CIL for its ability to adjust data distribution to better align with pre-trained knowledge. This paper critically examines the limitations of existing methods from the perspective of prompt learning, which heavily rely on input information. To address this issue, we propose a novel PTM-based CIL method called Input-Agnostic Prompt Enhancement with Negative Feedback Regulation (PEARL). In PEARL, we implement an input-agnostic global prompt coupled with an adaptive momentum update strategy to reduce the model's dependency on data distribution, thereby effectively mitigating catastrophic forgetting. Guided by negative feedback regulation, this adaptive momentum update addresses the parameter sensitivity inherent in fixed-weight momentum updates. Furthermore, it fosters the continuous enhancement of the prompt for new tasks by harnessing correlations between different tasks in CIL. Experiments on six benchmarks demonstrate that our method achieves state-of-the-art performance. The code is available at: https://github.com/qinyongchun/PEARL.
SVasP: Self-Versatility Adversarial Style Perturbation for Cross-Domain Few-Shot Learning
Dec 12, 2024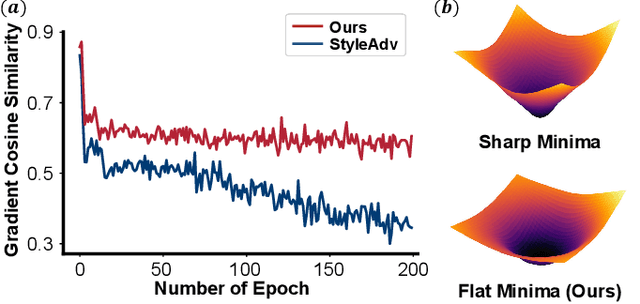

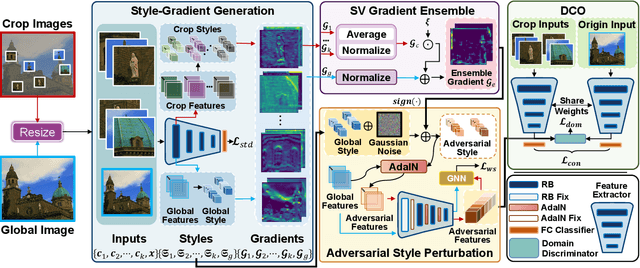

Cross-Domain Few-Shot Learning (CD-FSL) aims to transfer knowledge from seen source domains to unseen target domains, which is crucial for evaluating the generalization and robustness of models. Recent studies focus on utilizing visual styles to bridge the domain gap between different domains. However, the serious dilemma of gradient instability and local optimization problem occurs in those style-based CD-FSL methods. This paper addresses these issues and proposes a novel crop-global style perturbation method, called \underline{\textbf{S}}elf-\underline{\textbf{V}}ersatility \underline{\textbf{A}}dversarial \underline{\textbf{S}}tyle \underline{\textbf{P}}erturbation (\textbf{SVasP}), which enhances the gradient stability and escapes from poor sharp minima jointly. Specifically, SVasP simulates more diverse potential target domain adversarial styles via diversifying input patterns and aggregating localized crop style gradients, to serve as global style perturbation stabilizers within one image, a concept we refer to as self-versatility. Then a novel objective function is proposed to maximize visual discrepancy while maintaining semantic consistency between global, crop, and adversarial features. Having the stabilized global style perturbation in the training phase, one can obtain a flattened minima in the loss landscape, boosting the transferability of the model to the target domains. Extensive experiments on multiple benchmark datasets demonstrate that our method significantly outperforms existing state-of-the-art methods. Our codes are available at https://github.com/liwenqianSEU/SVasP.
Towards Few-Shot Learning in the Open World: A Review and Beyond
Aug 19, 2024



Human intelligence is characterized by our ability to absorb and apply knowledge from the world around us, especially in rapidly acquiring new concepts from minimal examples, underpinned by prior knowledge. Few-shot learning (FSL) aims to mimic this capacity by enabling significant generalizations and transferability. However, traditional FSL frameworks often rely on assumptions of clean, complete, and static data, conditions that are seldom met in real-world environments. Such assumptions falter in the inherently uncertain, incomplete, and dynamic contexts of the open world. This paper presents a comprehensive review of recent advancements designed to adapt FSL for use in open-world settings. We categorize existing methods into three distinct types of open-world few-shot learning: those involving varying instances, varying classes, and varying distributions. Each category is discussed in terms of its specific challenges and methods, as well as its strengths and weaknesses. We standardize experimental settings and metric benchmarks across scenarios, and provide a comparative analysis of the performance of various methods. In conclusion, we outline potential future research directions for this evolving field. It is our hope that this review will catalyze further development of effective solutions to these complex challenges, thereby advancing the field of artificial intelligence.
Text Image Inpainting via Global Structure-Guided Diffusion Models
Feb 02, 2024



Real-world text can be damaged by corrosion issues caused by environmental or human factors, which hinder the preservation of the complete styles of texts, e.g., texture and structure. These corrosion issues, such as graffiti signs and incomplete signatures, bring difficulties in understanding the texts, thereby posing significant challenges to downstream applications, e.g., scene text recognition and signature identification. Notably, current inpainting techniques often fail to adequately address this problem and have difficulties restoring accurate text images along with reasonable and consistent styles. Formulating this as an open problem of text image inpainting, this paper aims to build a benchmark to facilitate its study. In doing so, we establish two specific text inpainting datasets which contain scene text images and handwritten text images, respectively. Each of them includes images revamped by real-life and synthetic datasets, featuring pairs of original images, corrupted images, and other assistant information. On top of the datasets, we further develop a novel neural framework, Global Structure-guided Diffusion Model (GSDM), as a potential solution. Leveraging the global structure of the text as a prior, the proposed GSDM develops an efficient diffusion model to recover clean texts. The efficacy of our approach is demonstrated by thorough empirical study, including a substantial boost in both recognition accuracy and image quality. These findings not only highlight the effectiveness of our method but also underscore its potential to enhance the broader field of text image understanding and processing. Code and datasets are available at: https://github.com/blackprotoss/GSDM.