 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
Sep 30, 2025



Large Language Models (LLMs), despite being trained on text alone, surprisingly develop rich visual priors. These priors allow latent visual capabilities to be unlocked for vision tasks with a relatively small amount of multimodal data, and in some cases, to perform visual tasks without ever having seen an image. Through systematic analysis, we reveal that visual priors-the implicit, emergent knowledge about the visual world acquired during language pre-training-are composed of separable perception and reasoning priors with unique scaling trends and origins. We show that an LLM's latent visual reasoning ability is predominantly developed by pre-training on reasoning-centric data (e.g., code, math, academia) and scales progressively. This reasoning prior acquired from language pre-training is transferable and universally applicable to visual reasoning. In contrast, a perception prior emerges more diffusely from broad corpora, and perception ability is more sensitive to the vision encoder and visual instruction tuning data. In parallel, text describing the visual world proves crucial, though its performance impact saturates rapidly. Leveraging these insights, we propose a data-centric recipe for pre-training vision-aware LLMs and verify it in 1T token scale pre-training. Our findings are grounded in over 100 controlled experiments consuming 500,000 GPU-hours, spanning the full MLLM construction pipeline-from LLM pre-training to visual alignment and supervised multimodal fine-tuning-across five model scales, a wide range of data categories and mixtures, and multiple adaptation setups. Along with our main findings, we propose and investigate several hypotheses, and introduce the Multi-Level Existence Bench (MLE-Bench). Together, this work provides a new way of deliberately cultivating visual priors from language pre-training, paving the way for the next generation of multimodal LLMs.
Hallucination at a Glance: Controlled Visual Edits and Fine-Grained Multimodal Learning
Jun 08, 2025Multimodal large language models (MLLMs) have achieved strong performance on vision-language tasks but still struggle with fine-grained visual differences, leading to hallucinations or missed semantic shifts. We attribute this to limitations in both training data and learning objectives. To address these issues, we propose a controlled data generation pipeline that produces minimally edited image pairs with semantically aligned captions. Using this pipeline, we construct the Micro Edit Dataset (MED), containing over 50K image-text pairs spanning 11 fine-grained edit categories, including attribute, count, position, and object presence changes. Building on MED, we introduce a supervised fine-tuning (SFT) framework with a feature-level consistency loss that promotes stable visual embeddings under small edits. We evaluate our approach on the Micro Edit Detection benchmark, which includes carefully balanced evaluation pairs designed to test sensitivity to subtle visual variations across the same edit categories. Our method improves difference detection accuracy and reduces hallucinations compared to strong baselines, including GPT-4o. Moreover, it yields consistent gains on standard vision-language tasks such as image captioning and visual question answering. These results demonstrate the effectiveness of combining targeted data and alignment objectives for enhancing fine-grained visual reasoning in MLLMs.
VGRP-Bench: Visual Grid Reasoning Puzzle Benchmark for Large Vision-Language Models
Apr 02, 2025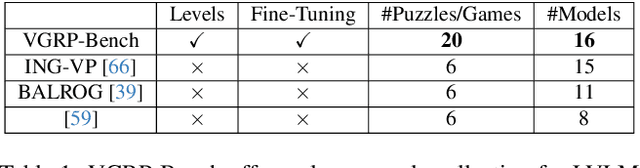
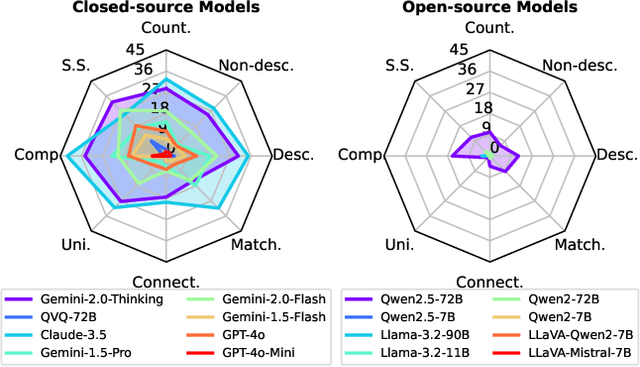
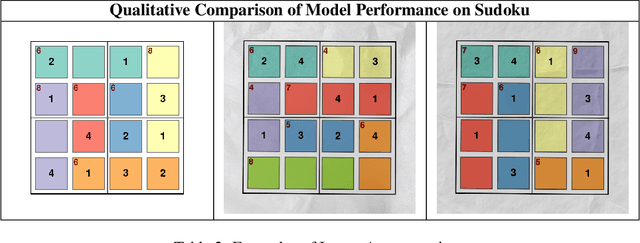
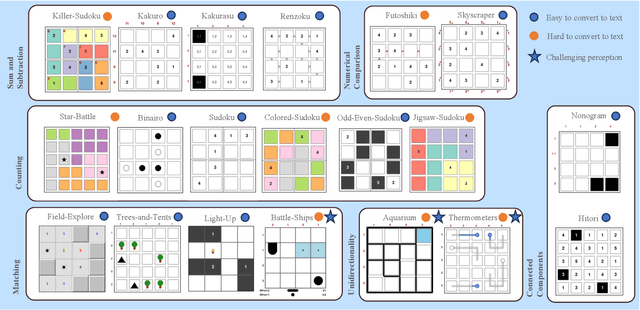
Large Vision-Language Models (LVLMs) struggle with puzzles, which require precise perception, rule comprehension, and logical reasoning. Assessing and enhancing their performance in this domain is crucial, as it reflects their ability to engage in structured reasoning - an essential skill for real-world problem-solving. However, existing benchmarks primarily evaluate pre-trained models without additional training or fine-tuning, often lack a dedicated focus on reasoning, and fail to establish a systematic evaluation framework. To address these limitations, we introduce VGRP-Bench, a Visual Grid Reasoning Puzzle Benchmark featuring 20 diverse puzzles. VGRP-Bench spans multiple difficulty levels, and includes extensive experiments not only on existing chat LVLMs (e.g., GPT-4o), but also on reasoning LVLMs (e.g., Gemini-Thinking). Our results reveal that even the state-of-the-art LVLMs struggle with these puzzles, highlighting fundamental limitations in their puzzle-solving capabilities. Most importantly, through systematic experiments, we identify and analyze key factors influencing LVLMs' puzzle-solving performance, including the number of clues, grid size, and rule complexity. Furthermore, we explore two Supervised Fine-Tuning (SFT) strategies that can be used in post-training: SFT on solutions (S-SFT) and SFT on synthetic reasoning processes (R-SFT). While both methods significantly improve performance on trained puzzles, they exhibit limited generalization to unseen ones. We will release VGRP-Bench to facilitate further research on LVLMs for complex, real-world problem-solving. Project page: https://yufan-ren.com/subpage/VGRP-Bench/.
Generalized Few-shot 3D Point Cloud Segmentation with Vision-Language Model
Mar 20, 2025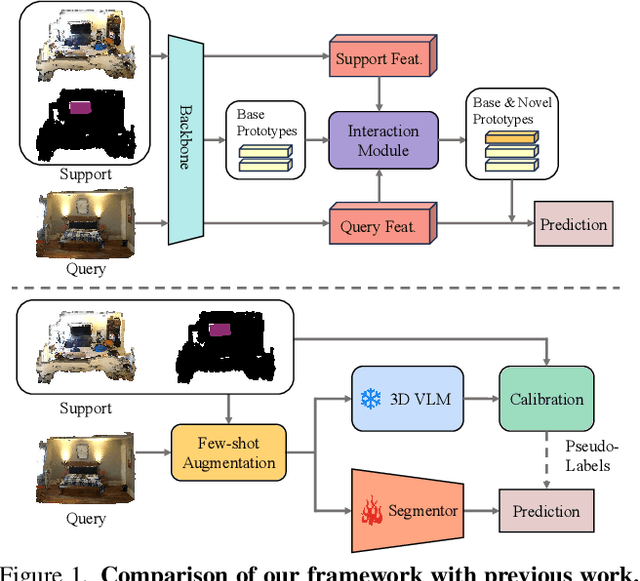
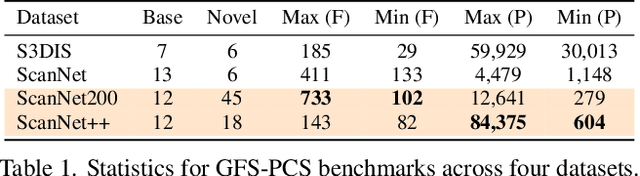
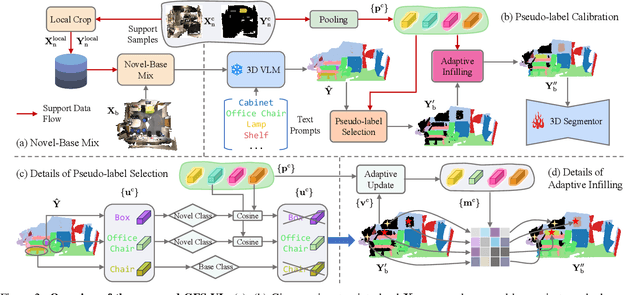
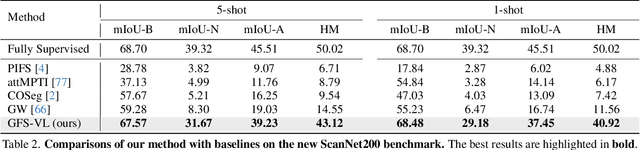
Generalized few-shot 3D point cloud segmentation (GFS-PCS) adapts models to new classes with few support samples while retaining base class segmentation. Existing GFS-PCS methods enhance prototypes via interacting with support or query features but remain limited by sparse knowledge from few-shot samples. Meanwhile, 3D vision-language models (3D VLMs), generalizing across open-world novel classes, contain rich but noisy novel class knowledge. In this work, we introduce a GFS-PCS framework that synergizes dense but noisy pseudo-labels from 3D VLMs with precise yet sparse few-shot samples to maximize the strengths of both, named GFS-VL. Specifically, we present a prototype-guided pseudo-label selection to filter low-quality regions, followed by an adaptive infilling strategy that combines knowledge from pseudo-label contexts and few-shot samples to adaptively label the filtered, unlabeled areas. Additionally, we design a novel-base mix strategy to embed few-shot samples into training scenes, preserving essential context for improved novel class learning. Moreover, recognizing the limited diversity in current GFS-PCS benchmarks, we introduce two challenging benchmarks with diverse novel classes for comprehensive generalization evaluation. Experiments validate the effectiveness of our framework across models and datasets. Our approach and benchmarks provide a solid foundation for advancing GFS-PCS in the real world. The code is at https://github.com/ZhaochongAn/GFS-VL
Semantic Score Distillation Sampling for Compositional Text-to-3D Generation
Oct 11, 2024



Generating high-quality 3D assets from textual descriptions remains a pivotal challenge in computer graphics and vision research. Due to the scarcity of 3D data, state-of-the-art approaches utilize pre-trained 2D diffusion priors, optimized through Score Distillation Sampling (SDS). Despite progress, crafting complex 3D scenes featuring multiple objects or intricate interactions is still difficult. To tackle this, recent methods have incorporated box or layout guidance. However, these layout-guided compositional methods often struggle to provide fine-grained control, as they are generally coarse and lack expressiveness. To overcome these challenges, we introduce a novel SDS approach, Semantic Score Distillation Sampling (SemanticSDS), designed to effectively improve the expressiveness and accuracy of compositional text-to-3D generation. Our approach integrates new semantic embeddings that maintain consistency across different rendering views and clearly differentiate between various objects and parts. These embeddings are transformed into a semantic map, which directs a region-specific SDS process, enabling precise optimization and compositional generation. By leveraging explicit semantic guidance, our method unlocks the compositional capabilities of existing pre-trained diffusion models, thereby achieving superior quality in 3D content generation, particularly for complex objects and scenes. Experimental results demonstrate that our SemanticSDS framework is highly effective for generating state-of-the-art complex 3D content. Code: https://github.com/YangLing0818/SemanticSDS-3D
Flex3D: Feed-Forward 3D Generation With Flexible Reconstruction Model And Input View Curation
Oct 02, 2024

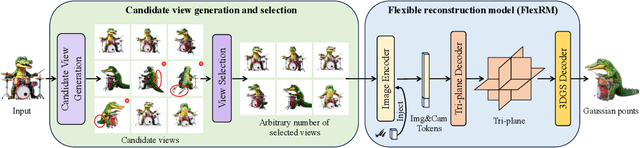
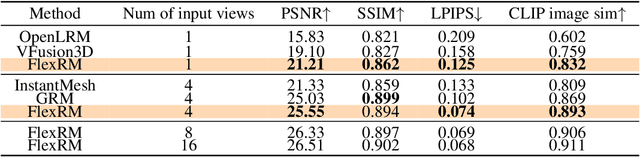
Generating high-quality 3D content from text, single images, or sparse view images remains a challenging task with broad applications. Existing methods typically employ multi-view diffusion models to synthesize multi-view images, followed by a feed-forward process for 3D reconstruction. However, these approaches are often constrained by a small and fixed number of input views, limiting their ability to capture diverse viewpoints and, even worse, leading to suboptimal generation results if the synthesized views are of poor quality. To address these limitations, we propose Flex3D, a novel two-stage framework capable of leveraging an arbitrary number of high-quality input views. The first stage consists of a candidate view generation and curation pipeline. We employ a fine-tuned multi-view image diffusion model and a video diffusion model to generate a pool of candidate views, enabling a rich representation of the target 3D object. Subsequently, a view selection pipeline filters these views based on quality and consistency, ensuring that only the high-quality and reliable views are used for reconstruction. In the second stage, the curated views are fed into a Flexible Reconstruction Model (FlexRM), built upon a transformer architecture that can effectively process an arbitrary number of inputs. FlemRM directly outputs 3D Gaussian points leveraging a tri-plane representation, enabling efficient and detailed 3D generation. Through extensive exploration of design and training strategies, we optimize FlexRM to achieve superior performance in both reconstruction and generation tasks. Our results demonstrate that Flex3D achieves state-of-the-art performance, with a user study winning rate of over 92% in 3D generation tasks when compared to several of the latest feed-forward 3D generative models.
DreamBeast: Distilling 3D Fantastical Animals with Part-Aware Knowledge Transfer
Sep 12, 2024



We present DreamBeast, a novel method based on score distillation sampling (SDS) for generating fantastical 3D animal assets composed of distinct parts. Existing SDS methods often struggle with this generation task due to a limited understanding of part-level semantics in text-to-image diffusion models. While recent diffusion models, such as Stable Diffusion 3, demonstrate a better part-level understanding, they are prohibitively slow and exhibit other common problems associated with single-view diffusion models. DreamBeast overcomes this limitation through a novel part-aware knowledge transfer mechanism. For each generated asset, we efficiently extract part-level knowledge from the Stable Diffusion 3 model into a 3D Part-Affinity implicit representation. This enables us to instantly generate Part-Affinity maps from arbitrary camera views, which we then use to modulate the guidance of a multi-view diffusion model during SDS to create 3D assets of fantastical animals. DreamBeast significantly enhances the quality of generated 3D creatures with user-specified part compositions while reducing computational overhead, as demonstrated by extensive quantitative and qualitative evaluations.
Learning-based Multi-View Stereo: A Survey
Aug 27, 2024



3D reconstruction aims to recover the dense 3D structure of a scene. It plays an essential role in various applications such as Augmented/Virtual Reality (AR/VR), autonomous driving and robotics. Leveraging multiple views of a scene captured from different viewpoints, Multi-View Stereo (MVS) algorithms synthesize a comprehensive 3D representation, enabling precise reconstruction in complex environments. Due to its efficiency and effectiveness, MVS has become a pivotal method for image-based 3D reconstruction. Recently, with the success of deep learning, many learning-based MVS methods have been proposed, achieving impressive performance against traditional methods. We categorize these learning-based methods as: depth map-based, voxel-based, NeRF-based, 3D Gaussian Splatting-based, and large feed-forward methods. Among these, we focus significantly on depth map-based methods, which are the main family of MVS due to their conciseness, flexibility and scalability. In this survey, we provide a comprehensive review of the literature at the time of this writing. We investigate these learning-based methods, summarize their performances on popular benchmarks, and discuss promising future research directions in this area.
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
Mar 18, 2024This paper presents a novel paradigm for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire. This results in a significant disparity in scale compared to the vast quantities of other types of data. To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model. The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 70% of the time.
Strong and Controllable Blind Image Decomposition
Mar 15, 2024Blind image decomposition aims to decompose all components present in an image, typically used to restore a multi-degraded input image. While fully recovering the clean image is appealing, in some scenarios, users might want to retain certain degradations, such as watermarks, for copyright protection. To address this need, we add controllability to the blind image decomposition process, allowing users to enter which types of degradation to remove or retain. We design an architecture named controllable blind image decomposition network. Inserted in the middle of U-Net structure, our method first decomposes the input feature maps and then recombines them according to user instructions. Advantageously, this functionality is implemented at minimal computational cost: decomposition and recombination are all parameter-free. Experimentally, our system excels in blind image decomposition tasks and can outputs partially or fully restored images that well reflect user intentions. Furthermore, we evaluate and configure different options for the network structure and loss functions. This, combined with the proposed decomposition-and-recombination method, yields an efficient and competitive system for blind image decomposition, compared with current state-of-the-art methods.