 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHairWeaver: Few-Shot Photorealistic Hair Motion Synthesis with Sim-to-Real Guided Video Diffusion
Feb 11, 2026We present HairWeaver, a diffusion-based pipeline that animates a single human image with realistic and expressive hair dynamics. While existing methods successfully control body pose, they lack specific control over hair, and as a result, fail to capture the intricate hair motions, resulting in stiff and unrealistic animations. HairWeaver overcomes this limitation using two specialized modules: a Motion-Context-LoRA to integrate motion conditions and a Sim2Real-Domain-LoRA to preserve the subject's photoreal appearance across different data domains. These lightweight components are designed to guide a video diffusion backbone while maintaining its core generative capabilities. By training on a specialized dataset of dynamic human motion generated from a CG simulator, HairWeaver affords fine control over hair motion and ultimately learns to produce highly realistic hair that responds naturally to movement. Comprehensive evaluations demonstrate that our approach sets a new state of the art, producing lifelike human hair animations with dynamic details.
DiTaiListener: Controllable High Fidelity Listener Video Generation with Diffusion
Apr 05, 2025



Generating naturalistic and nuanced listener motions for extended interactions remains an open problem. Existing methods often rely on low-dimensional motion codes for facial behavior generation followed by photorealistic rendering, limiting both visual fidelity and expressive richness. To address these challenges, we introduce DiTaiListener, powered by a video diffusion model with multimodal conditions. Our approach first generates short segments of listener responses conditioned on the speaker's speech and facial motions with DiTaiListener-Gen. It then refines the transitional frames via DiTaiListener-Edit for a seamless transition. Specifically, DiTaiListener-Gen adapts a Diffusion Transformer (DiT) for the task of listener head portrait generation by introducing a Causal Temporal Multimodal Adapter (CTM-Adapter) to process speakers' auditory and visual cues. CTM-Adapter integrates speakers' input in a causal manner into the video generation process to ensure temporally coherent listener responses. For long-form video generation, we introduce DiTaiListener-Edit, a transition refinement video-to-video diffusion model. The model fuses video segments into smooth and continuous videos, ensuring temporal consistency in facial expressions and image quality when merging short video segments produced by DiTaiListener-Gen. Quantitatively, DiTaiListener achieves the state-of-the-art performance on benchmark datasets in both photorealism (+73.8% in FID on RealTalk) and motion representation (+6.1% in FD metric on VICO) spaces. User studies confirm the superior performance of DiTaiListener, with the model being the clear preference in terms of feedback, diversity, and smoothness, outperforming competitors by a significant margin.
X-Dancer: Expressive Music to Human Dance Video Generation
Feb 24, 2025We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to produce both diverse and characterized dance videos, substantially outperforming state-of-the-art methods in term of diversity, expressiveness and realism. Code and model will be available for research purposes.
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.
Multi-scale Generative Modeling for Fast Sampling
Nov 14, 2024

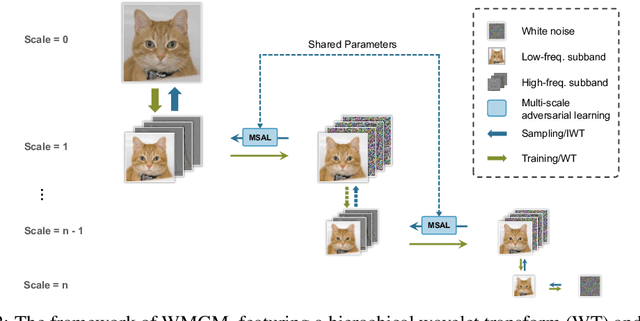
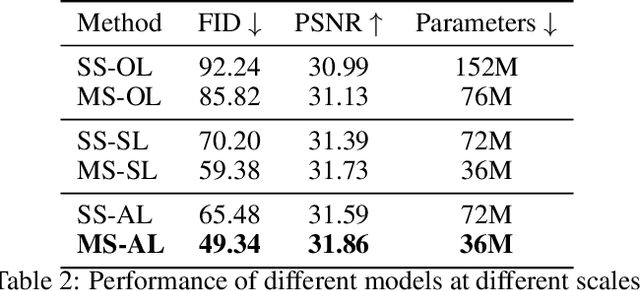
While working within the spatial domain can pose problems associated with ill-conditioned scores caused by power-law decay, recent advances in diffusion-based generative models have shown that transitioning to the wavelet domain offers a promising alternative. However, within the wavelet domain, we encounter unique challenges, especially the sparse representation of high-frequency coefficients, which deviates significantly from the Gaussian assumptions in the diffusion process. To this end, we propose a multi-scale generative modeling in the wavelet domain that employs distinct strategies for handling low and high-frequency bands. In the wavelet domain, we apply score-based generative modeling with well-conditioned scores for low-frequency bands, while utilizing a multi-scale generative adversarial learning for high-frequency bands. As supported by the theoretical analysis and experimental results, our model significantly improve performance and reduce the number of trainable parameters, sampling steps, and time.
Learning-based Multi-View Stereo: A Survey
Aug 27, 2024



3D reconstruction aims to recover the dense 3D structure of a scene. It plays an essential role in various applications such as Augmented/Virtual Reality (AR/VR), autonomous driving and robotics. Leveraging multiple views of a scene captured from different viewpoints, Multi-View Stereo (MVS) algorithms synthesize a comprehensive 3D representation, enabling precise reconstruction in complex environments. Due to its efficiency and effectiveness, MVS has become a pivotal method for image-based 3D reconstruction. Recently, with the success of deep learning, many learning-based MVS methods have been proposed, achieving impressive performance against traditional methods. We categorize these learning-based methods as: depth map-based, voxel-based, NeRF-based, 3D Gaussian Splatting-based, and large feed-forward methods. Among these, we focus significantly on depth map-based methods, which are the main family of MVS due to their conciseness, flexibility and scalability. In this survey, we provide a comprehensive review of the literature at the time of this writing. We investigate these learning-based methods, summarize their performances on popular benchmarks, and discuss promising future research directions in this area.
MagicPose4D: Crafting Articulated Models with Appearance and Motion Control
May 22, 2024



With the success of 2D and 3D visual generative models, there is growing interest in generating 4D content. Existing methods primarily rely on text prompts to produce 4D content, but they often fall short of accurately defining complex or rare motions. To address this limitation, we propose MagicPose4D, a novel framework for refined control over both appearance and motion in 4D generation. Unlike traditional methods, MagicPose4D accepts monocular videos as motion prompts, enabling precise and customizable motion generation. MagicPose4D comprises two key modules: i) Dual-Phase 4D Reconstruction Module} which operates in two phases. The first phase focuses on capturing the model's shape using accurate 2D supervision and less accurate but geometrically informative 3D pseudo-supervision without imposing skeleton constraints. The second phase refines the model using more accurate pseudo-3D supervision, obtained in the first phase and introduces kinematic chain-based skeleton constraints to ensure physical plausibility. Additionally, we propose a Global-local Chamfer loss that aligns the overall distribution of predicted mesh vertices with the supervision while maintaining part-level alignment without extra annotations. ii) Cross-category Motion Transfer Module} leverages the predictions from the 4D reconstruction module and uses a kinematic-chain-based skeleton to achieve cross-category motion transfer. It ensures smooth transitions between frames through dynamic rigidity, facilitating robust generalization without additional training. Through extensive experiments, we demonstrate that MagicPose4D significantly improves the accuracy and consistency of 4D content generation, outperforming existing methods in various benchmarks.
Dyadic Interaction Modeling for Social Behavior Generation
Mar 27, 2024Human-human communication is like a delicate dance where listeners and speakers concurrently interact to maintain conversational dynamics. Hence, an effective model for generating listener nonverbal behaviors requires understanding the dyadic context and interaction. In this paper, we present an effective framework for creating 3D facial motions in dyadic interactions. Existing work consider a listener as a reactive agent with reflexive behaviors to the speaker's voice and facial motions. The heart of our framework is Dyadic Interaction Modeling (DIM), a pre-training approach that jointly models speakers' and listeners' motions through masking and contrastive learning to learn representations that capture the dyadic context. To enable the generation of non-deterministic behaviors, we encode both listener and speaker motions into discrete latent representations, through VQ-VAE. The pre-trained model is further fine-tuned for motion generation. Extensive experiments demonstrate the superiority of our framework in generating listener motions, establishing a new state-of-the-art according to the quantitative measures capturing the diversity and realism of generated motions. Qualitative results demonstrate the superior capabilities of the proposed approach in generating diverse and realistic expressions, eye blinks and head gestures.
DiffPortrait3D: Controllable Diffusion for Zero-Shot Portrait View Synthesis
Dec 22, 2023



We present DiffPortrait3D, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. Specifically, given a single RGB input, we aim to synthesize plausible but consistent facial details rendered from novel camera views with retained both identity and facial expression. In lieu of time-consuming optimization and fine-tuning, our zero-shot method generalizes well to arbitrary face portraits with unposed camera views, extreme facial expressions, and diverse artistic depictions. At its core, we leverage the generative prior of 2D diffusion models pre-trained on large-scale image datasets as our rendering backbone, while the denoising is guided with disentangled attentive control of appearance and camera pose. To achieve this, we first inject the appearance context from the reference image into the self-attention layers of the frozen UNets. The rendering view is then manipulated with a novel conditional control module that interprets the camera pose by watching a condition image of a crossed subject from the same view. Furthermore, we insert a trainable cross-view attention module to enhance view consistency, which is further strengthened with a novel 3D-aware noise generation process during inference. We demonstrate state-of-the-art results both qualitatively and quantitatively on our challenging in-the-wild and multi-view benchmarks.
MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer
Nov 18, 2023In this work, we propose MagicDance, a diffusion-based model for 2D human motion and facial expression transfer on challenging human dance videos. Specifically, we aim to generate human dance videos of any target identity driven by novel pose sequences while keeping the identity unchanged. To this end, we propose a two-stage training strategy to disentangle human motions and appearance (e.g., facial expressions, skin tone and dressing), consisting of the pretraining of an appearance-control block and fine-tuning of an appearance-pose-joint-control block over human dance poses of the same dataset. Our novel design enables robust appearance control with temporally consistent upper body, facial attributes, and even background. The model also generalizes well on unseen human identities and complex motion sequences without the need for any fine-tuning with additional data with diverse human attributes by leveraging the prior knowledge of image diffusion models. Moreover, the proposed model is easy to use and can be considered as a plug-in module/extension to Stable Diffusion. We also demonstrate the model's ability for zero-shot 2D animation generation, enabling not only the appearance transfer from one identity to another but also allowing for cartoon-like stylization given only pose inputs. Extensive experiments demonstrate our superior performance on the TikTok dataset.