 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal symmetric low-rank BD-RIS configuration maximizing the determinant of a MIMO link
Apr 10, 2026Beyond-diagonal reconfigurable intelligent surfaces (BD-RISs) significantly improve wireless performance by allowing tunable interconnections among elements, but their design in multiple-input multiple-output (MIMO) systems has so far relied on complex iterative algorithms or suboptimal approximations. This work introduces a simple yet powerful approach: instead of directly maximizing the achievable rate, we maximize the absolute value of the determinant of the equivalent MIMO channel. We derive a closed-form symmetric unitary scattering matrix whose rank is exactly twice the channel's degrees of freedom ($2r$). Remarkably, this low-rank solution achieves the same determinant value as the optimal unitary BD-RIS. Using log-majorization theory, we prove that the rate loss relative to the optimal unitary BD-RIS vanishes at high signal-to-noise ratio (SNR) or when the number of BD-RIS elements becomes large. Moreover, the proposed solution can be perfectly implemented using a $q$-stem BD-RIS architecture with only $q=2r-1$ stems, requiring a minimum number of reconfigurable circuits. The resulting Max-Det solution is orders of magnitude faster to compute than existing iterative methods while achieving near-optimal rates in practical scenarios. This makes high-performance BD-RIS deployment feasible even with large surfaces and limited computational resources.
GDPO-Listener: Expressive Interactive Head Generation via Auto-Regressive Flow Matching and Group reward-Decoupled Policy Optimization
Mar 26, 2026Generating realistic 3D head motion for dyadic interactions is a significant challenge in virtual human synthesis. While recent methods achieve impressive results with speaking heads, they frequently suffer from the `Regression-to-the-Mean' problem in listener motions, collapsing into static faces, and lack the parameter space for complex nonverbal motions. In this paper, we propose GDPO-Listener, a novel framework that achieves highly expressive speaking and listening motion generation. First, we introduce an Auto-Regressive Flow Matching architecture enabling stable supervised learning. Second, to overcome kinematic stillness, we apply the Group reward-Decoupled Policy Optimization (GDPO). By isolating reward normalization across distinct FLAME parameter groups, GDPO explicitly incentivizes high variance expressive generations. Finally, we enable explicit semantic text control for customizable responses. Extensive evaluations across the Seamless Interaction and DualTalk datasets demonstrate superior performance compared to existing baselines on long-term kinematic variance, visual expressivity and semantic controllability.
RIS-Aided RSMA Improves the Latency vs. Energy Trade-off in the Finite Block Length MIMO Downlink
Mar 16, 2026We simultaneously minimize the latency and improve energy efficiency (EE) of the multi-user multiple-input multiple-output (MU-MIMO) rate splitting multiple access (RSMA) downlink, aided by a reconfigurable intelligent surface (RIS). Our results show that RSMA improves the EE and may reduce the delay to 13\% of that of spatial division multiple access (SDMA). Moreover, RIS and RSMA support each other synergistically, while an RIS operating without RSMA provides limited benefits in terms of latency and cannot effectively mitigate interference. {Furthermore, increasing the RIS size amplifies the gains of RSMA more significantly than those of SDMA, without altering the fundamental EE-latency trade-offs.} Results also show that latency increases with more stringent reliability requirements, and RSMA yields more significant gains under such conditions, making it eminently suitable for energy-efficient ultra-reliable low-latency communication (URLLC) scenarios.
MoD-DPO: Towards Mitigating Cross-modal Hallucinations in Omni LLMs using Modality Decoupled Preference Optimization
Mar 03, 2026Omni-modal large language models (omni LLMs) have recently achieved strong performance across audiovisual understanding tasks, yet they remain highly susceptible to cross-modal hallucinations arising from spurious correlations and dominant language priors. In this work, we propose Modality-Decoupled Direct Preference Optimization (MoD-DPO), a simple and effective framework for improving modality grounding in omni LLMs. MoD-DPO introduces modality-aware regularization terms that explicitly enforce invariance to corruptions in irrelevant modalities and sensitivity to perturbations in relevant modalities, thereby reducing unintended cross-modal interactions. To further mitigate over-reliance on textual priors, we incorporate a language-prior debiasing penalty that discourages hallucination-prone text-only responses. Extensive experiments across multiple audiovisual hallucination benchmarks demonstrate that MoD-DPO consistently improves perception accuracy and hallucination resistance, outperforming previous preference optimization baselines under similar training budgets. Our findings underscore the importance of modality-faithful alignment and demonstrate a scalable path toward more reliable and resilient multimodal foundation models.
HairWeaver: Few-Shot Photorealistic Hair Motion Synthesis with Sim-to-Real Guided Video Diffusion
Feb 11, 2026We present HairWeaver, a diffusion-based pipeline that animates a single human image with realistic and expressive hair dynamics. While existing methods successfully control body pose, they lack specific control over hair, and as a result, fail to capture the intricate hair motions, resulting in stiff and unrealistic animations. HairWeaver overcomes this limitation using two specialized modules: a Motion-Context-LoRA to integrate motion conditions and a Sim2Real-Domain-LoRA to preserve the subject's photoreal appearance across different data domains. These lightweight components are designed to guide a video diffusion backbone while maintaining its core generative capabilities. By training on a specialized dataset of dynamic human motion generated from a CG simulator, HairWeaver affords fine control over hair motion and ultimately learns to produce highly realistic hair that responds naturally to movement. Comprehensive evaluations demonstrate that our approach sets a new state of the art, producing lifelike human hair animations with dynamic details.
AVERE: Improving Audiovisual Emotion Reasoning with Preference Optimization
Feb 04, 2026Emotion understanding is essential for building socially intelligent agents. Although recent multimodal large language models have shown strong performance on this task, two key challenges remain - spurious associations between emotions and irrelevant audiovisual cues, and hallucinations of audiovisual cues driven by text priors in the language model backbone. To quantify and understand these issues, we introduce EmoReAlM, a benchmark designed to evaluate MLLMs for cue-emotion associations, hallucinations and modality agreement. We then propose AVEm-DPO, a preference optimization technique that aligns model responses with both audiovisual inputs and emotion-centric queries. Specifically, we construct preferences over responses exhibiting spurious associations or hallucinations, and audiovisual input pairs guided by textual prompts. We also include a regularization term that penalizes reliance on text priors, thereby mitigating modality-specific cue hallucinations. Experimental results on DFEW, RAVDESS and EMER demonstrate that our method significantly improves the performance of the reference baseline models with 6-19% of relative performance gains in zero-shot settings. By providing both a rigorous benchmark and a robust optimization framework, this work enables principled evaluation and improvement of MLLMs for emotion understanding and social AI. Code, models and benchmark will be released at https://avere-iclr.github.io.
Riemannian optimization on the manifold of unitary and symmetric matrices with application to BD-RIS-assisted systems
Jan 20, 2026In this paper, we rigorously characterize for the first time the manifold of unitary and symmetric matrices, deriving its tangent space and its geodesics. The resulting parameterization of the geodesics (through a real and symmetric matrix) allows us to derive a new Riemannian manifold optimization (MO) algorithm whose most remarkable feature is that it does not need to set any adaptation parameter. We apply the proposed MO algorithm to maximize the achievable rate in a multiple-input multiple-output (MIMO) system assisted by a beyond-diagonal reconfigurable intelligent surface (BD-RIS), illustrating the method's performance through simulations. The MO algorithm achieves a significant reduction in computational cost compared to previous alternatives based on Takagi decomposition, while retaining global convergence to a stationary point of the cost function.
Discrete Facial Encoding: : A Framework for Data-driven Facial Display Discovery
Oct 02, 2025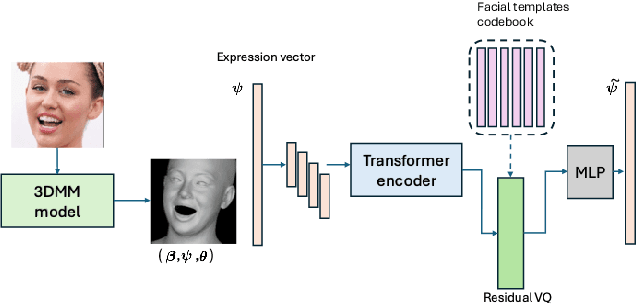
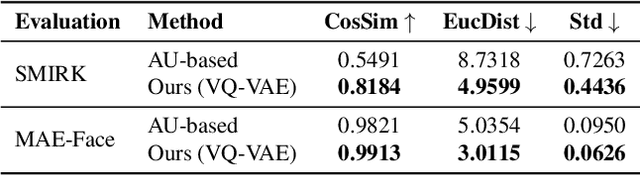

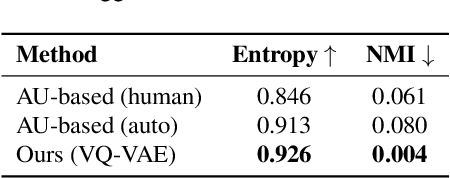
Facial expression analysis is central to understanding human behavior, yet existing coding systems such as the Facial Action Coding System (FACS) are constrained by limited coverage and costly manual annotation. In this work, we introduce Discrete Facial Encoding (DFE), an unsupervised, data-driven alternative of compact and interpretable dictionary of facial expressions from 3D mesh sequences learned through a Residual Vector Quantized Variational Autoencoder (RVQ-VAE). Our approach first extracts identity-invariant expression features from images using a 3D Morphable Model (3DMM), effectively disentangling factors such as head pose and facial geometry. We then encode these features using an RVQ-VAE, producing a sequence of discrete tokens from a shared codebook, where each token captures a specific, reusable facial deformation pattern that contributes to the overall expression. Through extensive experiments, we demonstrate that Discrete Facial Encoding captures more precise facial behaviors than FACS and other facial encoding alternatives. We evaluate the utility of our representation across three high-level psychological tasks: stress detection, personality prediction, and depression detection. Using a simple Bag-of-Words model built on top of the learned tokens, our system consistently outperforms both FACS-based pipelines and strong image and video representation learning models such as Masked Autoencoders. Further analysis reveals that our representation covers a wider variety of facial displays, highlighting its potential as a scalable and effective alternative to FACS for psychological and affective computing applications.
Social-MAE: A Transformer-Based Multimodal Autoencoder for Face and Voice
Aug 24, 2025Human social behaviors are inherently multimodal necessitating the development of powerful audiovisual models for their perception. In this paper, we present Social-MAE, our pre-trained audiovisual Masked Autoencoder based on an extended version of Contrastive Audio-Visual Masked Auto-Encoder (CAV-MAE), which is pre-trained on audiovisual social data. Specifically, we modify CAV-MAE to receive a larger number of frames as input and pre-train it on a large dataset of human social interaction (VoxCeleb2) in a self-supervised manner. We demonstrate the effectiveness of this model by finetuning and evaluating the model on different social and affective downstream tasks, namely, emotion recognition, laughter detection and apparent personality estimation. The model achieves state-of-the-art results on multimodal emotion recognition and laughter recognition and competitive results for apparent personality estimation, demonstrating the effectiveness of in-domain self-supervised pre-training. Code and model weight are available here https://github.com/HuBohy/SocialMAE.
* 5 pages, 3 figures, IEEE FG 2024 conference
Energy Efficiency Optimization of Finite Block Length STAR-RIS-aided MU-MIMO Broadcast Channels
Jun 13, 2025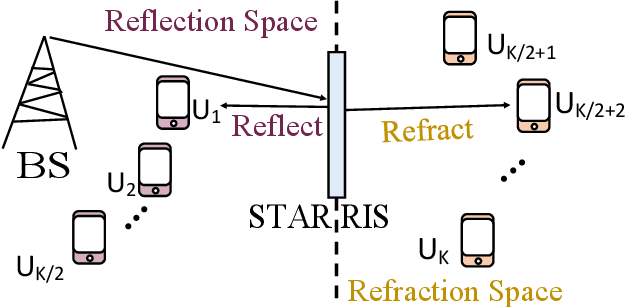
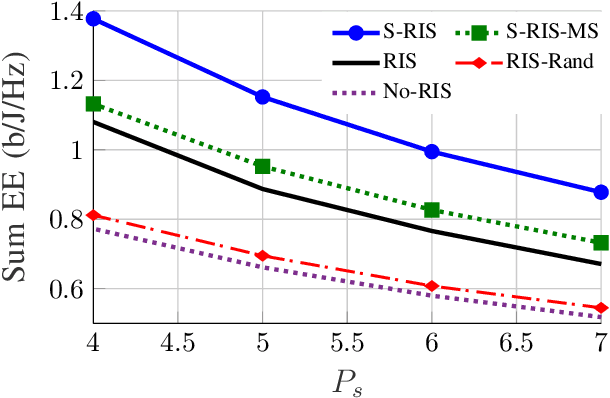
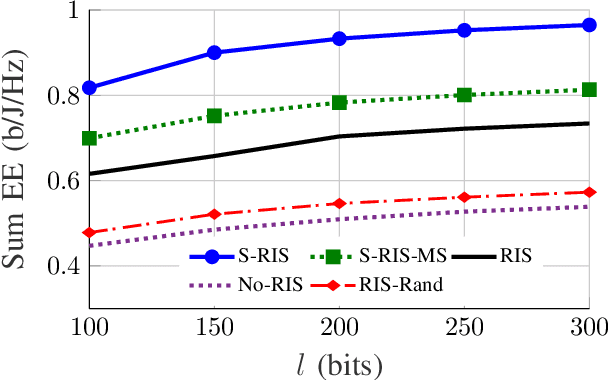
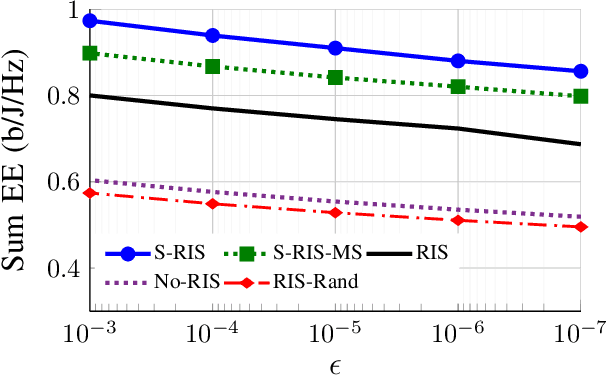
Energy-efficient designs are proposed for multi-user (MU) multiple-input multiple-output (MIMO) broadcast channels (BC), assisted by simultaneously transmitting and reflecting (STAR) reconfigurable intelligent surfaces (RIS) operating at finite block length (FBL). In particular, we maximize the sum energy efficiency (EE), showing that STAR-RIS can substantially enhance it. Our findings demonstrate that the gains of employing STAR-RIS increase when the codeword length and the maximum tolerable bit error rate decrease, meaning that a STAR-RIS is more energy efficient in a system with more stringent latency and reliability requirements.