 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPO-Listener: Expressive Interactive Head Generation via Auto-Regressive Flow Matching and Group reward-Decoupled Policy Optimization
Mar 26, 2026Generating realistic 3D head motion for dyadic interactions is a significant challenge in virtual human synthesis. While recent methods achieve impressive results with speaking heads, they frequently suffer from the `Regression-to-the-Mean' problem in listener motions, collapsing into static faces, and lack the parameter space for complex nonverbal motions. In this paper, we propose GDPO-Listener, a novel framework that achieves highly expressive speaking and listening motion generation. First, we introduce an Auto-Regressive Flow Matching architecture enabling stable supervised learning. Second, to overcome kinematic stillness, we apply the Group reward-Decoupled Policy Optimization (GDPO). By isolating reward normalization across distinct FLAME parameter groups, GDPO explicitly incentivizes high variance expressive generations. Finally, we enable explicit semantic text control for customizable responses. Extensive evaluations across the Seamless Interaction and DualTalk datasets demonstrate superior performance compared to existing baselines on long-term kinematic variance, visual expressivity and semantic controllability.
AVERE: Improving Audiovisual Emotion Reasoning with Preference Optimization
Feb 04, 2026Emotion understanding is essential for building socially intelligent agents. Although recent multimodal large language models have shown strong performance on this task, two key challenges remain - spurious associations between emotions and irrelevant audiovisual cues, and hallucinations of audiovisual cues driven by text priors in the language model backbone. To quantify and understand these issues, we introduce EmoReAlM, a benchmark designed to evaluate MLLMs for cue-emotion associations, hallucinations and modality agreement. We then propose AVEm-DPO, a preference optimization technique that aligns model responses with both audiovisual inputs and emotion-centric queries. Specifically, we construct preferences over responses exhibiting spurious associations or hallucinations, and audiovisual input pairs guided by textual prompts. We also include a regularization term that penalizes reliance on text priors, thereby mitigating modality-specific cue hallucinations. Experimental results on DFEW, RAVDESS and EMER demonstrate that our method significantly improves the performance of the reference baseline models with 6-19% of relative performance gains in zero-shot settings. By providing both a rigorous benchmark and a robust optimization framework, this work enables principled evaluation and improvement of MLLMs for emotion understanding and social AI. Code, models and benchmark will be released at https://avere-iclr.github.io.
Discrete Facial Encoding: : A Framework for Data-driven Facial Display Discovery
Oct 02, 2025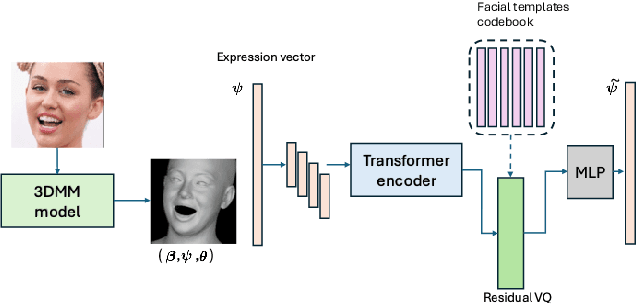
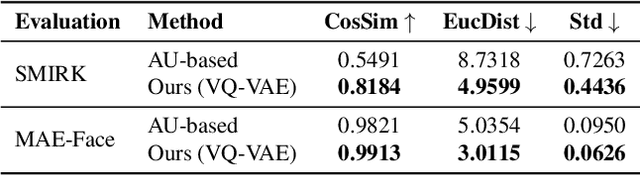

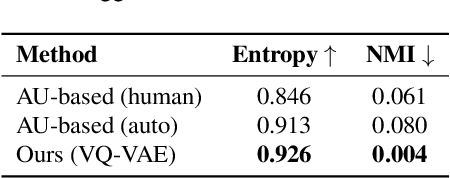
Facial expression analysis is central to understanding human behavior, yet existing coding systems such as the Facial Action Coding System (FACS) are constrained by limited coverage and costly manual annotation. In this work, we introduce Discrete Facial Encoding (DFE), an unsupervised, data-driven alternative of compact and interpretable dictionary of facial expressions from 3D mesh sequences learned through a Residual Vector Quantized Variational Autoencoder (RVQ-VAE). Our approach first extracts identity-invariant expression features from images using a 3D Morphable Model (3DMM), effectively disentangling factors such as head pose and facial geometry. We then encode these features using an RVQ-VAE, producing a sequence of discrete tokens from a shared codebook, where each token captures a specific, reusable facial deformation pattern that contributes to the overall expression. Through extensive experiments, we demonstrate that Discrete Facial Encoding captures more precise facial behaviors than FACS and other facial encoding alternatives. We evaluate the utility of our representation across three high-level psychological tasks: stress detection, personality prediction, and depression detection. Using a simple Bag-of-Words model built on top of the learned tokens, our system consistently outperforms both FACS-based pipelines and strong image and video representation learning models such as Masked Autoencoders. Further analysis reveals that our representation covers a wider variety of facial displays, highlighting its potential as a scalable and effective alternative to FACS for psychological and affective computing applications.
DiTaiListener: Controllable High Fidelity Listener Video Generation with Diffusion
Apr 05, 2025



Generating naturalistic and nuanced listener motions for extended interactions remains an open problem. Existing methods often rely on low-dimensional motion codes for facial behavior generation followed by photorealistic rendering, limiting both visual fidelity and expressive richness. To address these challenges, we introduce DiTaiListener, powered by a video diffusion model with multimodal conditions. Our approach first generates short segments of listener responses conditioned on the speaker's speech and facial motions with DiTaiListener-Gen. It then refines the transitional frames via DiTaiListener-Edit for a seamless transition. Specifically, DiTaiListener-Gen adapts a Diffusion Transformer (DiT) for the task of listener head portrait generation by introducing a Causal Temporal Multimodal Adapter (CTM-Adapter) to process speakers' auditory and visual cues. CTM-Adapter integrates speakers' input in a causal manner into the video generation process to ensure temporally coherent listener responses. For long-form video generation, we introduce DiTaiListener-Edit, a transition refinement video-to-video diffusion model. The model fuses video segments into smooth and continuous videos, ensuring temporal consistency in facial expressions and image quality when merging short video segments produced by DiTaiListener-Gen. Quantitatively, DiTaiListener achieves the state-of-the-art performance on benchmark datasets in both photorealism (+73.8% in FID on RealTalk) and motion representation (+6.1% in FD metric on VICO) spaces. User studies confirm the superior performance of DiTaiListener, with the model being the clear preference in terms of feedback, diversity, and smoothness, outperforming competitors by a significant margin.
Towards a Generalizable Speech Marker for Parkinson's Disease Diagnosis
Jan 07, 2025



Parkinson's Disease (PD) is a neurodegenerative disorder characterized by motor symptoms, including altered voice production in the early stages. Early diagnosis is crucial not only to improve PD patients' quality of life but also to enhance the efficacy of potential disease-modifying therapies during early neurodegeneration, a window often missed by current diagnostic tools. In this paper, we propose a more generalizable approach to PD recognition through domain adaptation and self-supervised learning. We demonstrate the generalization capabilities of the proposed approach across diverse datasets in different languages. Our approach leverages HuBERT, a large deep neural network originally trained for speech recognition and further trains it on unlabeled speech data from a population that is similar to the target group, i.e., the elderly, in a self-supervised manner. The model is then fine-tuned and adapted for use across different datasets in multiple languages, including English, Italian, and Spanish. Evaluations on four publicly available PD datasets demonstrate the model's efficacy, achieving an average specificity of 92.1% and an average sensitivity of 91.2%. This method offers objective and consistent evaluations across large populations, addressing the variability inherent in human assessments and providing a non-invasive, cost-effective and accessible diagnostic option.
Dyadic Interaction Modeling for Social Behavior Generation
Mar 27, 2024Human-human communication is like a delicate dance where listeners and speakers concurrently interact to maintain conversational dynamics. Hence, an effective model for generating listener nonverbal behaviors requires understanding the dyadic context and interaction. In this paper, we present an effective framework for creating 3D facial motions in dyadic interactions. Existing work consider a listener as a reactive agent with reflexive behaviors to the speaker's voice and facial motions. The heart of our framework is Dyadic Interaction Modeling (DIM), a pre-training approach that jointly models speakers' and listeners' motions through masking and contrastive learning to learn representations that capture the dyadic context. To enable the generation of non-deterministic behaviors, we encode both listener and speaker motions into discrete latent representations, through VQ-VAE. The pre-trained model is further fine-tuned for motion generation. Extensive experiments demonstrate the superiority of our framework in generating listener motions, establishing a new state-of-the-art according to the quantitative measures capturing the diversity and realism of generated motions. Qualitative results demonstrate the superior capabilities of the proposed approach in generating diverse and realistic expressions, eye blinks and head gestures.
Hacking VMAF and VMAF NEG: vulnerability to different preprocessing methods
Aug 16, 2021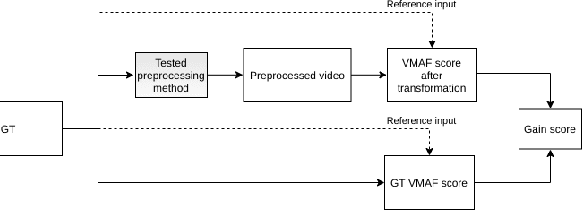
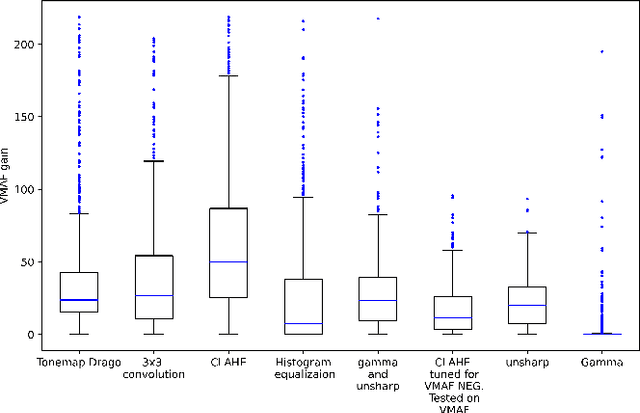


Video-quality measurement plays a critical role in the development of video-processing applications. In this paper, we show how video preprocessing can artificially increase the popular quality metric VMAF and its tuning-resistant version, VMAF NEG. We propose a pipeline that tunes processing-algorithm parameters to increase VMAF by up to 218.8%. A subjective comparison revealed that for most preprocessing methods, a video's visual quality drops or stays unchanged. We also show that some preprocessing methods can increase VMAF NEG scores by up to 23.6%.