 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Four-Tier Communication Architecture and Sim-to-Real Validation of a Graphical Open-Source Platform for Robotic Engineering Education
May 30, 2026The persistent challenge in scaling authentic manipulator education within university laboratories is a structural dichotomy: commercial digital twins are often cost-prohibitive and rigidly scripted, whereas open-source robotics middleware (ROS) imposes steep technical and syntax barriers for novices. To resolve this logistical and educational friction, this Work-in-Progress (WiP) paper proposes a scalable four-tier communication architecture tailored for sustainable robotic curricula. Rather than focusing on software application design, our study examines the underlying data exchange mechanisms required to bridge visual conceptual environments with physical robotic endpoints, utilizing the Graphical Open-Source Platform (GOSP) as a foundational instantiation. This WiP details the framework's technical integration of 3D visual armature modeling with a robust ROS middleware backend, emphasizing the serialization, routing, and encapsulation of intricate communication routines. Preliminary sim-to-real validation using multi-axis spatial trajectories confirms that encapsulating these communication pipelines provides a sufficient fidelity hardware-agnostic pathway. By bridging virtual design and physical execution, this architectural blueprint offers a viable infrastructure for engineering education.
Edge-Based QoS-Aware Adaptive Task Placement: A Closed-Loop Control in Multi-Robot Systems
May 30, 2026Multi-robot systems (MRS) increasingly offload compute-intensive perception tasks to edge nodes to meet strict time-sensitive Quality-of-Service (QoS) constraints. However, static task orchestration on a shared edge node can severely degrade QoS due to network latency, jitter, and edge-resource contention. We present a pilot edge-centric MRS testbed using Raspberry Pi nodes to evaluate a camera-to-manipulator pipeline under three modes: local execution, static offloading, and a QoS-aware Adaptive Task Placement (ATP) controller. ATP scores candidate placements using a multi-metric cost (normalized latency, CPU utilization, and switching overhead) over two-second control windows. The closed-loop visual servoing testbed is instrumented with sub-millisecond clock synchronization, network emulation, and detailed monitoring of multiple metrics across nodes to capture realistic jitter. Experimental results under compute-stress and network-fault scenarios show that static edge offloading reduces on-board CPU load but amplifies tail latency and deadline misses. In contrast, the QoS-aware ATP controller, by switching task placement based on measured latency and utilization thresholds, consistently lowers deadline violations and tail latency. Overall, the results position ATP as a practical edge-side control primitive for MRS and concrete design guidelines for Cloud-Edge Robotics deployments within the broader cloud-fog automation, while motivating QoS-aware multi-objective workload orchestration for industrial cyber-physical systems.
DAG-Based QoS-Aware Dynamic Task Placement for Networked Multi-Stage Control Pipelines
May 19, 2026Current Physical AI (PAI) relies heavily on closed-loop visual-servoing pipelines, whose perception and planning stages may become computationally intensive onboard due to complex models embedded on robots. In practice, offloading the perception task to on-site edges statically is inappropriate for latency-sensitive, precise industrial settings over a standardized industrial network. This emphasizes the importance of Control-Communication-Computing (3C) co-design in industrial automation: monolithic local execution saturates AI-accelerated machine and robot hardware, while static edge offloading exposes the control loop to network jitter. Existing adaptive task placement (ATP) controllers can partially address the gap by relocating a single pipeline stage on binary threshold rules, without a multi-stage model and an explicit cost on placement switching. In this Work-in-Progress (WiP) paper, we propose a directed acyclic graph (DAG) based quality-of-service (QoS)-aware dynamic task placement (DTP) framework for sensing-perception-planning-control pipelines in networked robotics. This pipeline is formalized as a DAG with task-level and node-level attributes for compute cost, communication delay, and feasible placement sets; over a small interpretable candidate set (fully local, static offload, hybrid), a window-based cost function combines tail end-to-end latency, deadline violation rate, hardware utilization, and a Hamming-distance switching penalty, and a DTP algorithm with hysteresis and a minimum dwell-time bounds placement chatter. Our WiP paper presents the theoretical framework, a structured qualitative analysis, and a two-phase simulation plus hardware-in-the-loop validation roadmap.
Generalizable IoT Traffic Representations for Cross-Network Device Identification
Jan 27, 2026Machine learning models have demonstrated strong performance in classifying network traffic and identifying Internet-of-Things (IoT) devices, enabling operators to discover and manage IoT assets at scale. However, many existing approaches rely on end-to-end supervised pipelines or task-specific fine-tuning, resulting in traffic representations that are tightly coupled to labeled datasets and deployment environments, which can limit generalizability. In this paper, we study the problem of learning generalizable traffic representations for IoT device identification. We design compact encoder architectures that learn per-flow embeddings from unlabeled IoT traffic and evaluate them using a frozen-encoder protocol with a simple supervised classifier. Our specific contributions are threefold. (1) We develop unsupervised encoder--decoder models that learn compact traffic representations from unlabeled IoT network flows and assess their quality through reconstruction-based analysis. (2) We show that these learned representations can be used effectively for IoT device-type classification using simple, lightweight classifiers trained on frozen embeddings. (3) We provide a systematic benchmarking study against the state-of-the-art pretrained traffic encoders, showing that larger models do not necessarily yield more robust representations for IoT traffic. Using more than 18 million real IoT traffic flows collected across multiple years and deployment environments, we learn traffic representations from unlabeled data and evaluate device-type classification on disjoint labeled subsets, achieving macro F1-scores exceeding 0.9 for device-type classification and demonstrating robustness under cross-environment deployment.
Discrete Facial Encoding: : A Framework for Data-driven Facial Display Discovery
Oct 02, 2025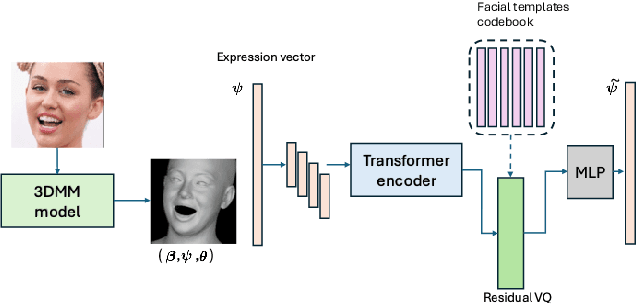
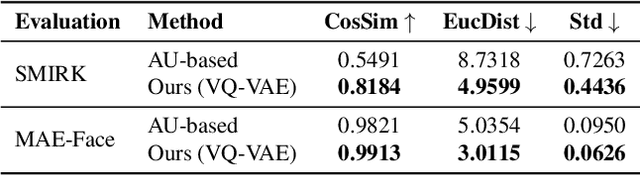

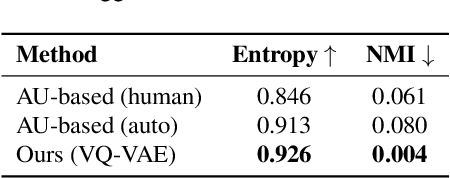
Facial expression analysis is central to understanding human behavior, yet existing coding systems such as the Facial Action Coding System (FACS) are constrained by limited coverage and costly manual annotation. In this work, we introduce Discrete Facial Encoding (DFE), an unsupervised, data-driven alternative of compact and interpretable dictionary of facial expressions from 3D mesh sequences learned through a Residual Vector Quantized Variational Autoencoder (RVQ-VAE). Our approach first extracts identity-invariant expression features from images using a 3D Morphable Model (3DMM), effectively disentangling factors such as head pose and facial geometry. We then encode these features using an RVQ-VAE, producing a sequence of discrete tokens from a shared codebook, where each token captures a specific, reusable facial deformation pattern that contributes to the overall expression. Through extensive experiments, we demonstrate that Discrete Facial Encoding captures more precise facial behaviors than FACS and other facial encoding alternatives. We evaluate the utility of our representation across three high-level psychological tasks: stress detection, personality prediction, and depression detection. Using a simple Bag-of-Words model built on top of the learned tokens, our system consistently outperforms both FACS-based pipelines and strong image and video representation learning models such as Masked Autoencoders. Further analysis reveals that our representation covers a wider variety of facial displays, highlighting its potential as a scalable and effective alternative to FACS for psychological and affective computing applications.
Social-MAE: A Transformer-Based Multimodal Autoencoder for Face and Voice
Aug 24, 2025Human social behaviors are inherently multimodal necessitating the development of powerful audiovisual models for their perception. In this paper, we present Social-MAE, our pre-trained audiovisual Masked Autoencoder based on an extended version of Contrastive Audio-Visual Masked Auto-Encoder (CAV-MAE), which is pre-trained on audiovisual social data. Specifically, we modify CAV-MAE to receive a larger number of frames as input and pre-train it on a large dataset of human social interaction (VoxCeleb2) in a self-supervised manner. We demonstrate the effectiveness of this model by finetuning and evaluating the model on different social and affective downstream tasks, namely, emotion recognition, laughter detection and apparent personality estimation. The model achieves state-of-the-art results on multimodal emotion recognition and laughter recognition and competitive results for apparent personality estimation, demonstrating the effectiveness of in-domain self-supervised pre-training. Code and model weight are available here https://github.com/HuBohy/SocialMAE.
* 5 pages, 3 figures, IEEE FG 2024 conference
A Robust BERT-Based Deep Learning Model for Automated Cancer Type Extraction from Unstructured Pathology Reports
Aug 21, 2025The accurate extraction of clinical information from electronic medical records is particularly critical to clinical research but require much trained expertise and manual labor. In this study we developed a robust system for automated extraction of the specific cancer types for the purpose of supporting precision oncology research. from pathology reports using a fine-tuned RoBERTa model. This model significantly outperformed the baseline model and a Large Language Model, Mistral 7B, achieving F1_Bertscore 0.98 and overall exact match of 80.61%. This fine-tuning approach demonstrates the potential for scalability that can integrate seamlessly into the molecular tumour board process. Fine-tuning domain-specific models for precision tasks in oncology, may pave the way for more efficient and accurate clinical information extraction.
DiTaiListener: Controllable High Fidelity Listener Video Generation with Diffusion
Apr 05, 2025



Generating naturalistic and nuanced listener motions for extended interactions remains an open problem. Existing methods often rely on low-dimensional motion codes for facial behavior generation followed by photorealistic rendering, limiting both visual fidelity and expressive richness. To address these challenges, we introduce DiTaiListener, powered by a video diffusion model with multimodal conditions. Our approach first generates short segments of listener responses conditioned on the speaker's speech and facial motions with DiTaiListener-Gen. It then refines the transitional frames via DiTaiListener-Edit for a seamless transition. Specifically, DiTaiListener-Gen adapts a Diffusion Transformer (DiT) for the task of listener head portrait generation by introducing a Causal Temporal Multimodal Adapter (CTM-Adapter) to process speakers' auditory and visual cues. CTM-Adapter integrates speakers' input in a causal manner into the video generation process to ensure temporally coherent listener responses. For long-form video generation, we introduce DiTaiListener-Edit, a transition refinement video-to-video diffusion model. The model fuses video segments into smooth and continuous videos, ensuring temporal consistency in facial expressions and image quality when merging short video segments produced by DiTaiListener-Gen. Quantitatively, DiTaiListener achieves the state-of-the-art performance on benchmark datasets in both photorealism (+73.8% in FID on RealTalk) and motion representation (+6.1% in FD metric on VICO) spaces. User studies confirm the superior performance of DiTaiListener, with the model being the clear preference in terms of feedback, diversity, and smoothness, outperforming competitors by a significant margin.
Negative to Positive Co-learning with Aggressive Modality Dropout
Jan 01, 2025This paper aims to document an effective way to improve multimodal co-learning by using aggressive modality dropout. We find that by using aggressive modality dropout we are able to reverse negative co-learning (NCL) to positive co-learning (PCL). Aggressive modality dropout can be used to "prep" a multimodal model for unimodal deployment, and dramatically increases model performance during negative co-learning, where during some experiments we saw a 20% gain in accuracy. We also benchmark our modality dropout technique against PCL to show that our modality drop out technique improves co-learning during PCL, although it does not have as much as an substantial effect as it does during NCL. Github: https://github.com/nmagal/modality_drop_for_colearning
A2VIS: Amodal-Aware Approach to Video Instance Segmentation
Dec 02, 2024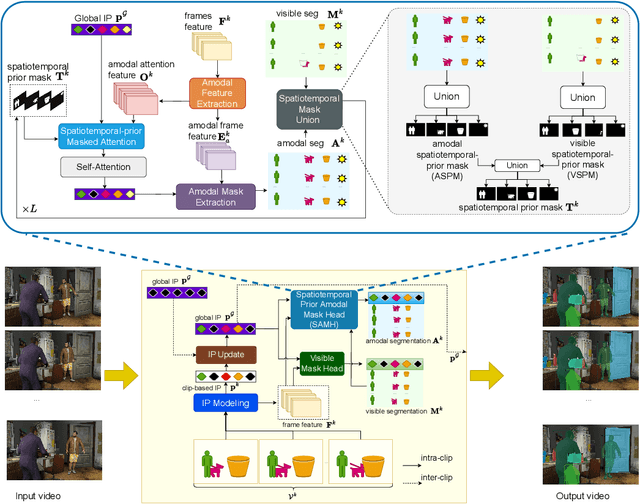
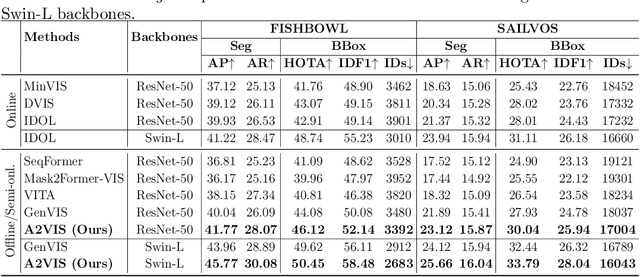
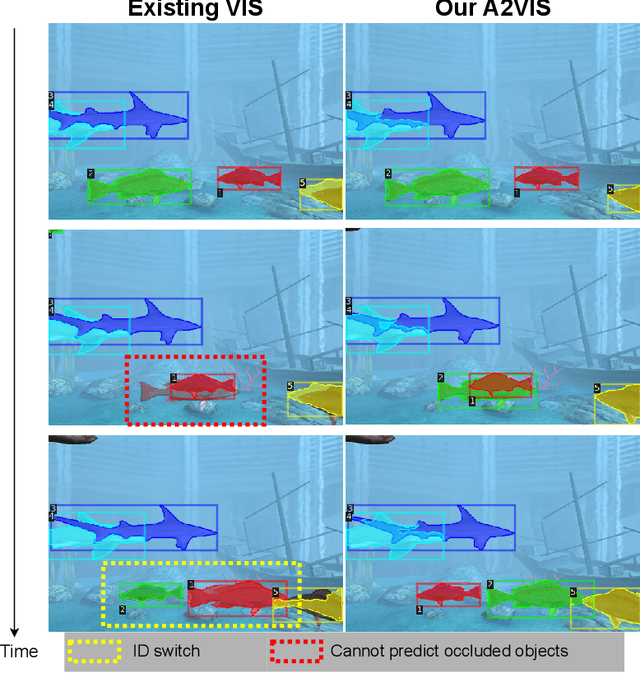
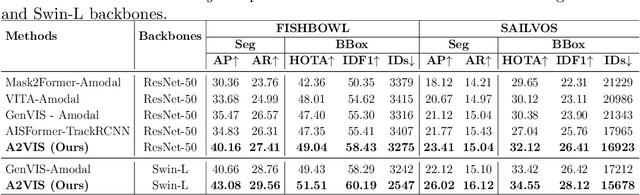
Handling occlusion remains a significant challenge for video instance-level tasks like Multiple Object Tracking (MOT) and Video Instance Segmentation (VIS). In this paper, we propose a novel framework, Amodal-Aware Video Instance Segmentation (A2VIS), which incorporates amodal representations to achieve a reliable and comprehensive understanding of both visible and occluded parts of objects in a video. The key intuition is that awareness of amodal segmentation through spatiotemporal dimension enables a stable stream of object information. In scenarios where objects are partially or completely hidden from view, amodal segmentation offers more consistency and less dramatic changes along the temporal axis compared to visible segmentation. Hence, both amodal and visible information from all clips can be integrated into one global instance prototype. To effectively address the challenge of video amodal segmentation, we introduce the spatiotemporal-prior Amodal Mask Head, which leverages visible information intra clips while extracting amodal characteristics inter clips. Through extensive experiments and ablation studies, we show that A2VIS excels in both MOT and VIS tasks in identifying and tracking object instances with a keen understanding of their full shape.